
OpenAI强化微调登场:几十条数据o1-mini反超o1暴涨80%,奥特曼:今年最大惊喜
OpenAI强化微调登场:几十条数据o1-mini反超o1暴涨80%,奥特曼:今年最大惊喜OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
来自主题: AI资讯
11588 点击 2024-12-07 09:26
 搜索
搜索
OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
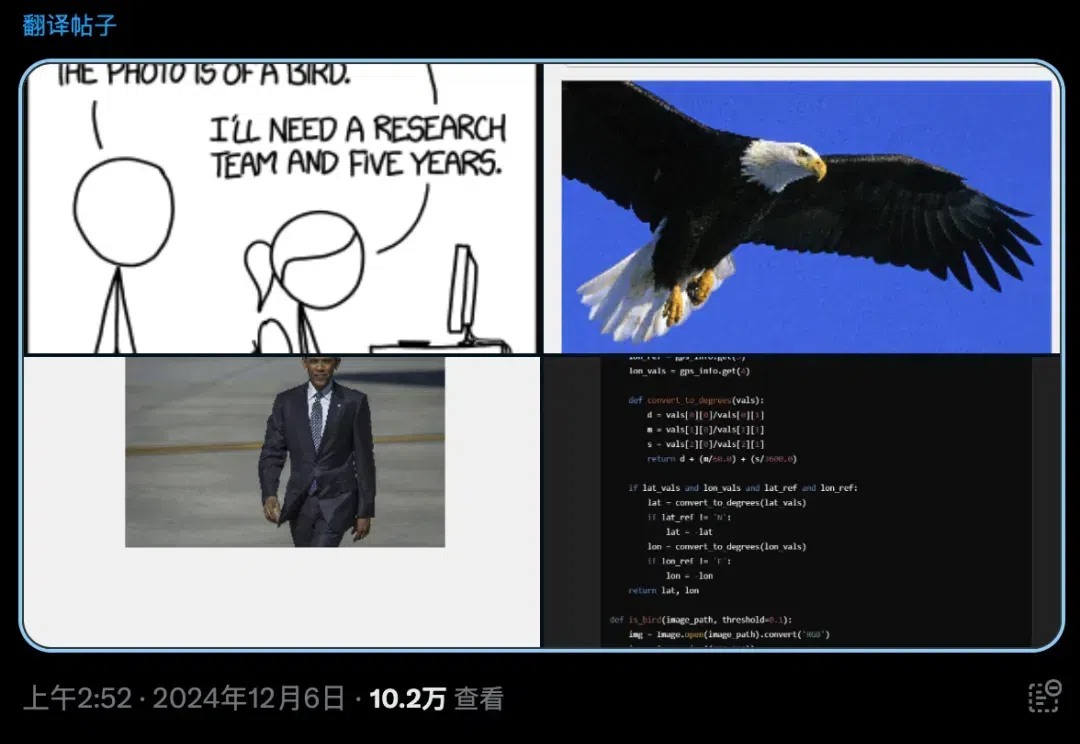
o1满血版这次不搞灰度了,发布仅4个小时后,已推送给所有(付费)用户! 手快的网友已经耍起来了~
一天前,OpenAI 官方 X 账户的一条推文将 AI 社区的期待值拉满了。这家世界头部 AI 公司宣布将在未来的 12 天进行 12 场直播,发布一些「大大小小的新东西」。
提前过年了。OpenAI昨天在X上发推文,说从12月5日开始,要进行为期十二天的发布会,美国西部时间每天上午十点,每天挤一点点牙膏。这个配置非常像美国流行的圣诞倒数日历,每天开一个小奖,有一个小惊喜,直到节日来临。

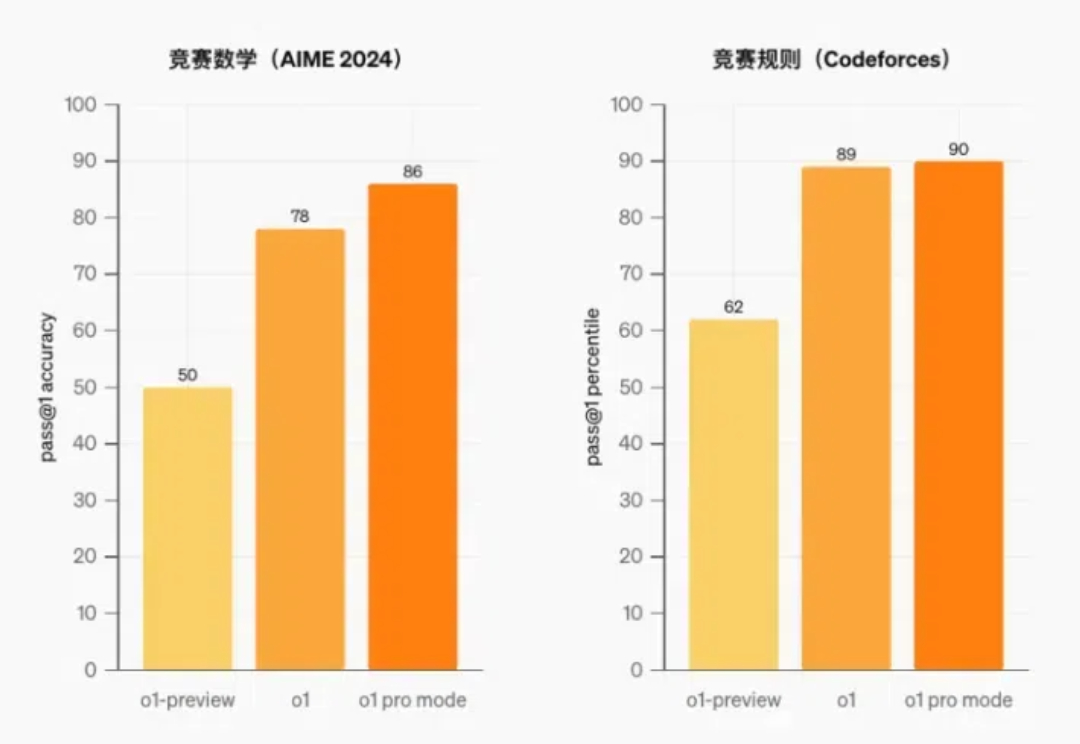
就在刚刚,满血版o1震撼上线了!它首次将多模态和新的推理范式结合起来,更智能、更快速。同时推出的还有200美元/月的专业版ChatGPT Pro。奥特曼亲自和Jason Wei等人做了演示,同时放出的,还有49页完整论文。据网友预测,GPT-4.5可能也要来了。

重磅!12月5日起,OpenAI将开始连续12天的圣诞马拉松。根据外媒The Verge的内部消息,满血版o1和Sora会正式发布。消息一出,网友们沸腾了。奥特曼也提前预热,称AGI将在2025年实现!
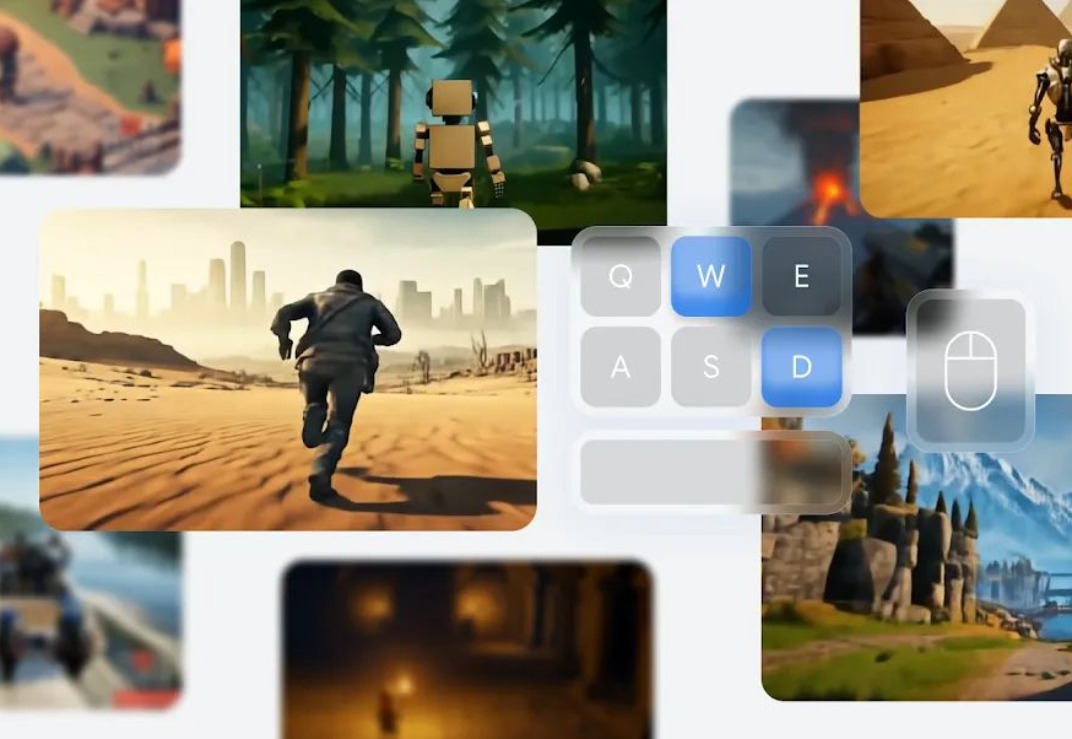
就在刚刚,Google Deepmind 深夜放大招,发布了最新基础世界模型 Genie 2。 想体验游戏世界?未来只需一张图片就能实现。 作为一个基础世界模型,Genie 2 能够凭借开局一张图生成各种可操作、可玩的 3D 环境。
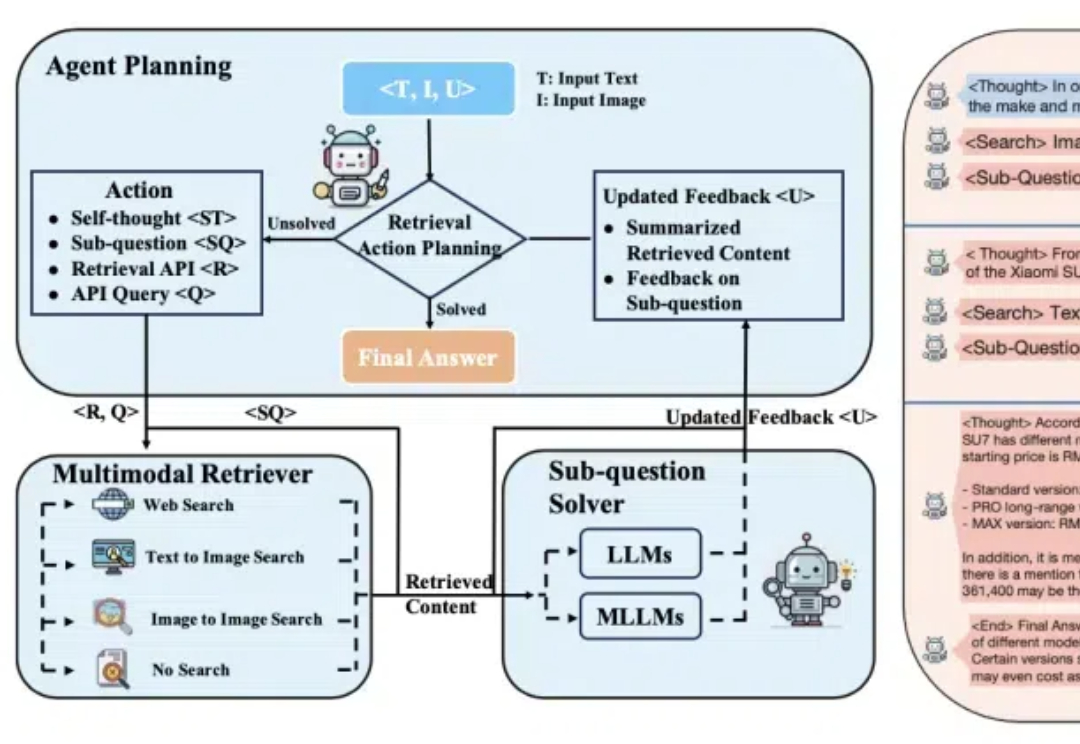
多模态检索增强生成(mRAG)也有o1思考推理那味儿了! 阿里通义实验室新研究推出自适应规划的多模态检索智能体。 名叫OmniSearch,它能模拟人类解决问题的思维方式,将复杂问题逐步拆解进行智能检索规划。
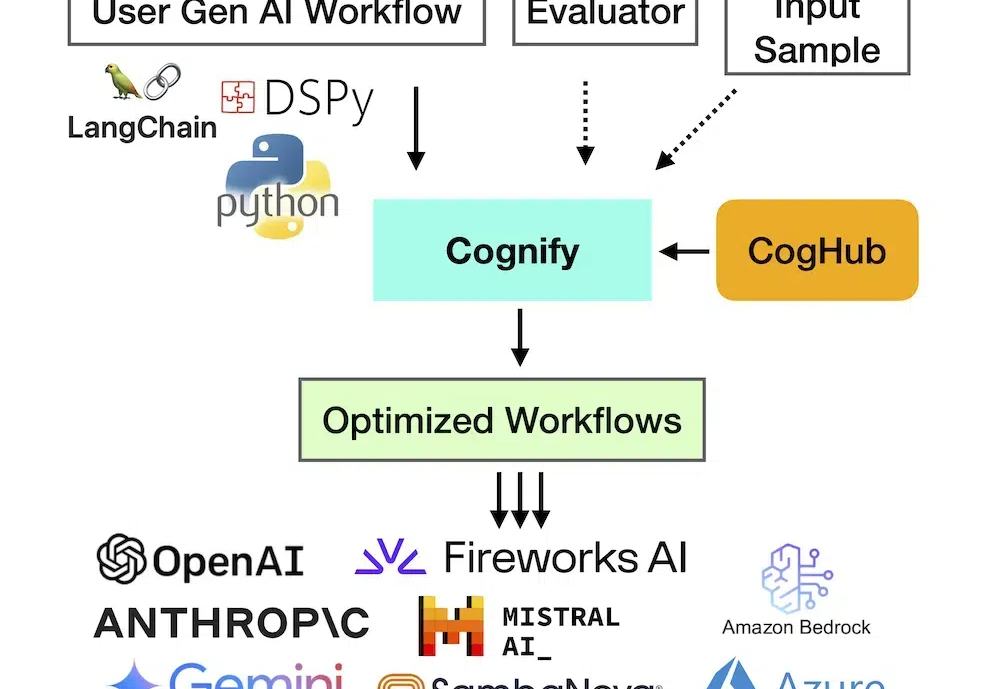
近几年在生成式 AI 技术和商业创新飞速发展的背景下,创建高质量且低成本的生成式 AI 应用在业界仍有相当难度,主要原因在于缺乏系统化的调试和优化方法。
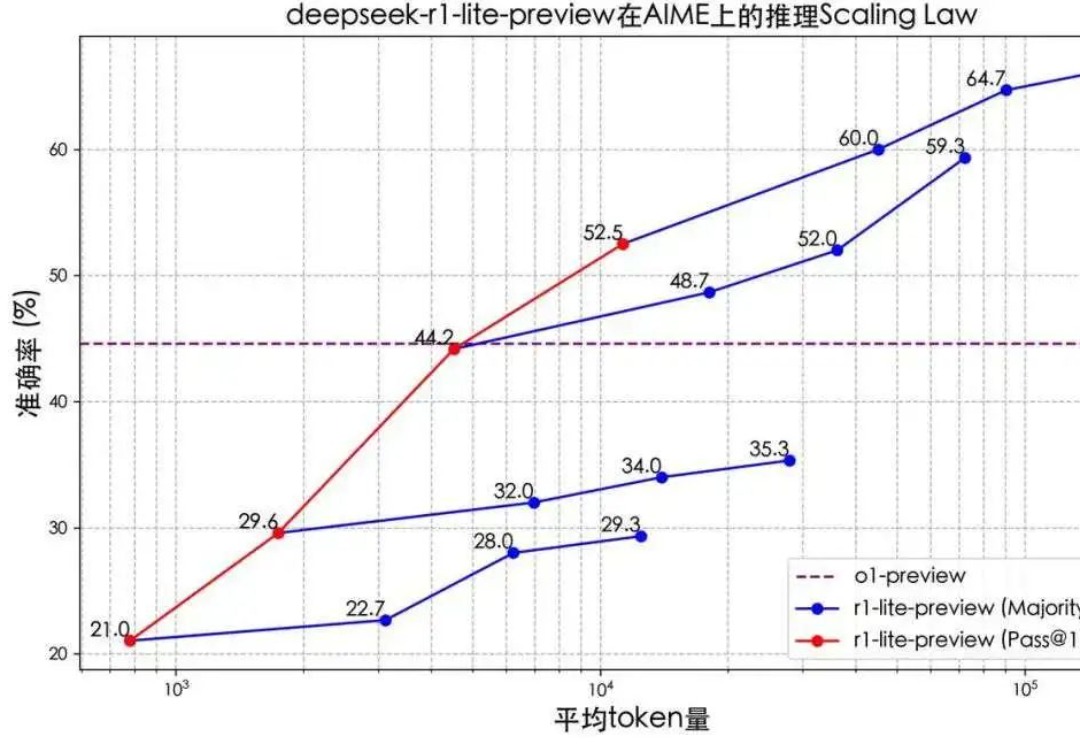
ChatGPT诞生的第二年,OpenAI和国内的一众企业正在试着“抛弃”它。 在Scaling Law被质疑能力“见顶”的情况下,今年9月,OpenAI带着以全新系列命名的模型o1一经发布,“会思考的大模型”再度成为焦点。