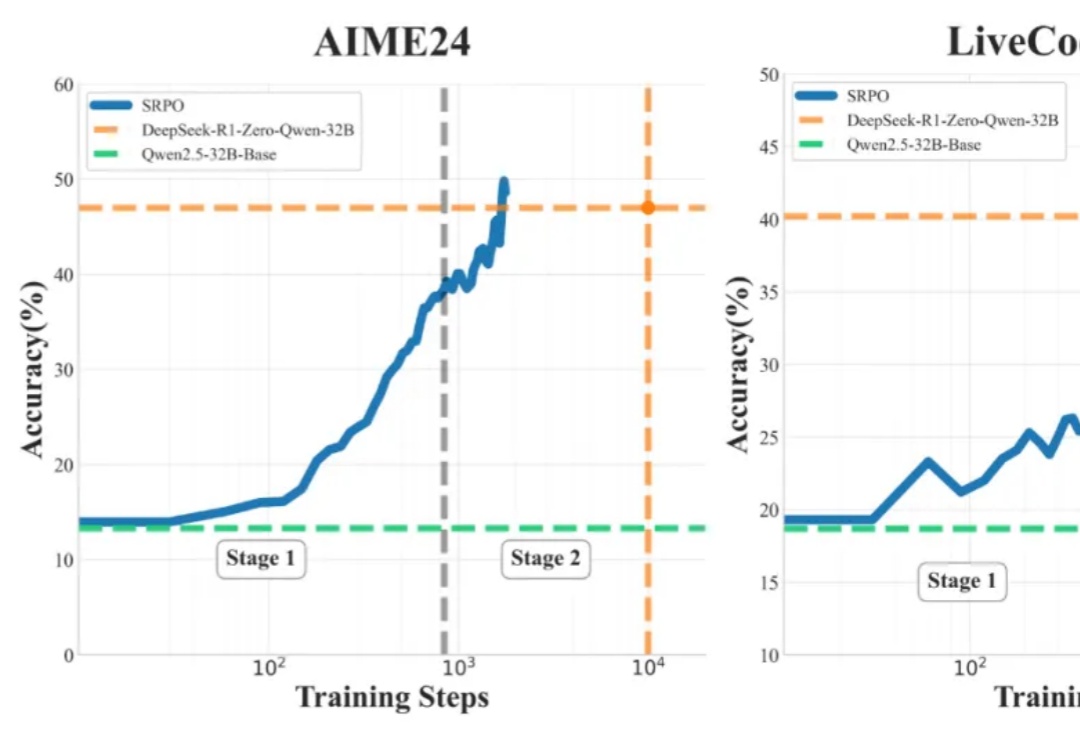
业内首次! 全面复现DeepSeek-R1-Zero数学代码能力,训练步数仅需其1/10
业内首次! 全面复现DeepSeek-R1-Zero数学代码能力,训练步数仅需其1/10OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。
来自主题: AI技术研报
8824 点击 2025-04-23 14:04
 搜索
搜索
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
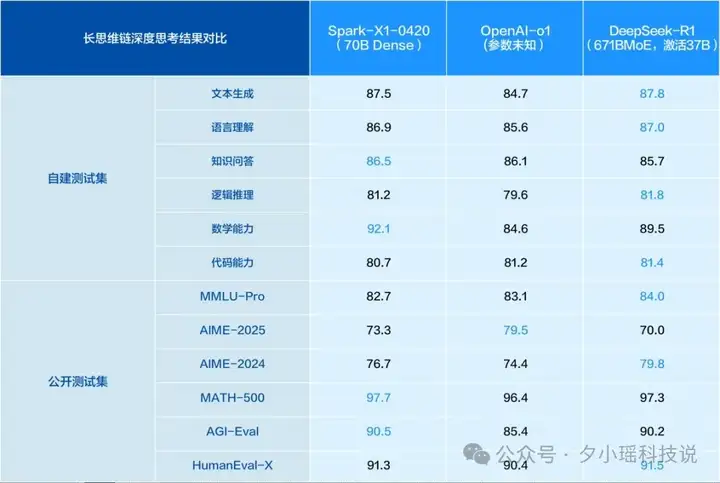
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。

OpenAI新模型发布后,大家体感都幻觉更多了。甚至有人测试后发出预警:使用它辅助编程会很危险。当大家带着疑问仔细阅读System Card,发现OpenAI官方也承认了这个问题,与o1相比o3幻觉率是两倍,o4-mini更是达到3倍。
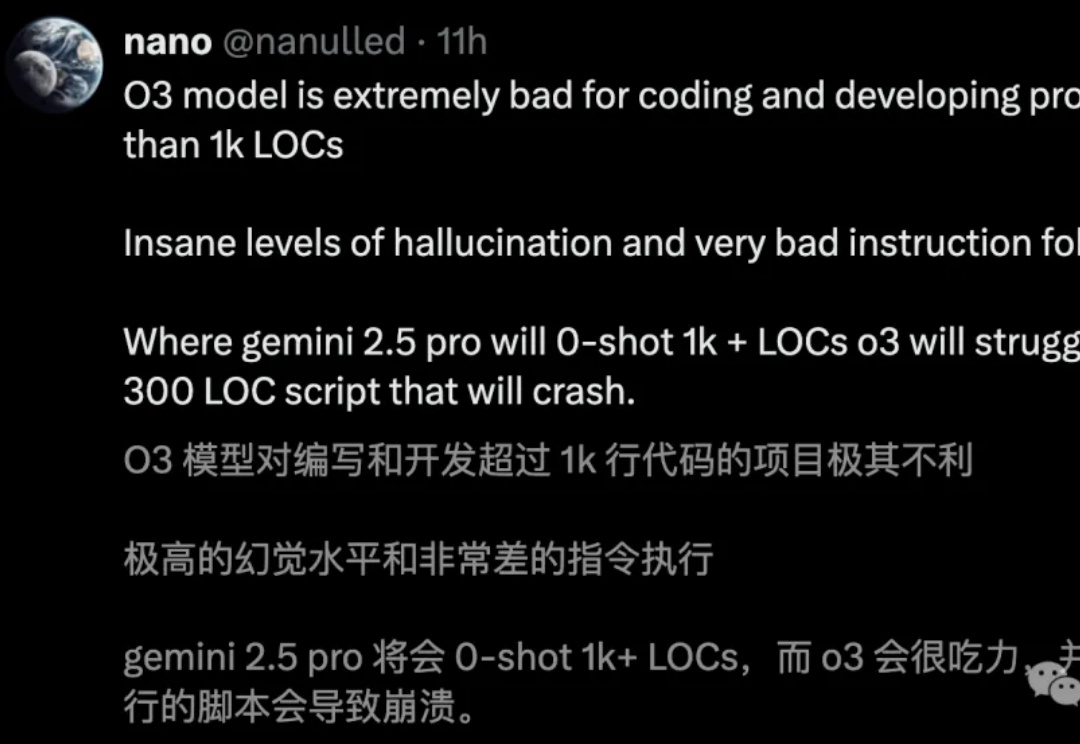
o3编码直逼全球TOP 200人类选手,却存在一个致命问题:幻觉率高达33%,是o1的两倍。Ai2科学家直指,RL过度优化成硬伤。

当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

公考行测中的逻辑推理题,是不少考生的噩梦,这次,CMU团队就此为基础,打造了一套逻辑谜题挑战。实测后发现,o1、Gemini-2.5 Pro、Claude-3.7-Sonnet这些顶尖大模型全部惨败!最强的AI正确率也只有57.5%,而人类TOP选手却能接近满分。

悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。

视频理解的CoT推理能力,怎么评?

满血版o3和o4-mini深夜登场,首次将图像推理融入思维链,还会自主调用工具,60秒内破解复杂难题。尤其是,o3以十倍o1算力刷新编程、数学、视觉推理SOTA,接近「天才水平」。此外,OpenAI还开源了编程神器Codex CLI,一夜爆火。