AI能自主出“竞赛题”了!港大&蚂蚁让大模型学会生成难题,水平已接近AIME
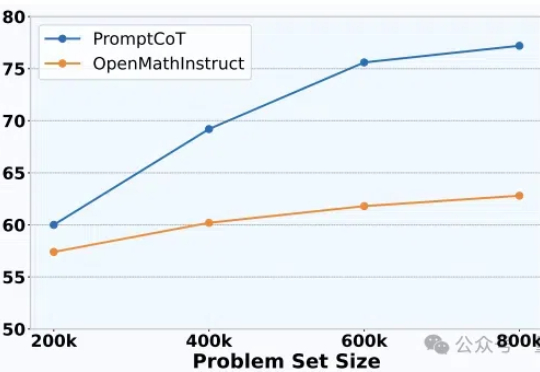
AI能自主出“竞赛题”了!港大&蚂蚁让大模型学会生成难题,水平已接近AIME大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。
来自主题: AI技术研报
9718 点击 2025-03-15 15:39
 搜索
搜索
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

Anthropic 昨晚发布了他们最新的 Claude 3.7 Sonnet 混合推理模型,并在官网同步更新了 Claude 3.7 的系统提示词。

在32道高等数学测试中,LLM表现出色,平均能得分90.4(按百分制计算)。GPT-4o和Mistral AI更是几乎没错!向量计算、几何分析、积分计算、优化问题等,高等AI模型轻松拿捏。研究发现,再提示(Re-Prompting)对提升准确率至关重要。
从本质上讲,LLM会根据用户从UI的输入生成代码示例。然后,生成的代码会通过中间件逻辑进行处理,根据逻辑跟踪文件、代码更改和第三方API调用。

单个模型的优缺点也能分析
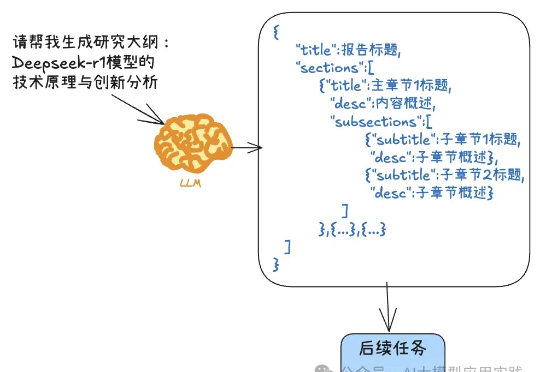
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。

一直以来,学术与实际产品的 Prompt 完全脱节,真实场景下,很多产品都聚焦情感陪伴,文案生成等开放任务里。而学术上这些任务没有明确的指标,无法量化也就没办法被比较,于是绝大部分的 Prompt 优化工作都聚焦在“刷榜”,例如怎么提升一个模型的代码/数学能力。我们今天跑的项目叫 SPO,具体什么意思并不重要,重要的是它把之前的所有问题全部解决了。

2024年春节,我其实已经尝试过用AI的介入,来完成一些原本长辈需要我才能完成、但实际上并没有什么难度的问题。例如帮助长辈学习如何用提示词(Prompt),使用类似“什么问题+细节描述+发生场景+附加需求”这样的结构来获得更准确的回复,或是发掘一些AI App中自带的例如一键P图等功能。

未来,掌握持续提示工程技术的开发者,将主导下一代智能系统的进化方向。