# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
亲爱的Prompt读者朋友们,或许你认为掌握了某种Prompt技术已经可以天下无敌,没什么解决不了的问题啦,那是你还没有进入AI应用的深水区!当你被无休止的Token消耗和脆弱的甚至是垃圾般的输出,一遍一遍倒逼着优化Prompt时,你可能才会深深体会到人与机器沟通的无力。所以,和机器沟通的事情还是交给机器自己去办吧。

你肯定体验过,为了高质量的输出,你可能写出卑躬屈膝极具谄媚之词,冷静下来时你都不会相信那是出自你手别再写脆弱的prompt讨好LLM啦!快用DSPy拯救你宝贵的prompt思维,偷偷甩掉99%的人。假设,我是说假设,你在DSPy上稍微用点功夫,聪明的你重磅 | DSPy让你不写一句Prompt照样构建Agent,从此,你不再卑躬屈膝讨好LLM
DSPy(发音为:[di:s'pai])声明式自我优化语言程序(Python)(“Declarative Self-improving Language Programs(in Python)",是斯坦福大学的Omar Khattab(第一作者)团队2022年最早提出的一种改善大语言模型能力的框架(DSP,DEMONSTRATE-SEARCH-PREDICT《演示-搜索-预测:知识密集型NLP的组合检索和语言模型》),2023年又发布论文《DSPy:编译声明性语言模型调用到自我改进管道》正式称为DSPy,2024年该论文被ICLR收录(ICLR,人工智能顶级会议,全称:International Conferrence onLearning Representations,国际表征学习大会),DSPy现已被谷歌、亚马逊、IBM、VMware、Databricks以及众多初创公司作为应用程序框架广泛应用于AI产品开发。

Omar Khattab目前是斯坦福大学的博士候选人(2024年6月毕业),2019年Omar毕业于卡梅隆大学计算机科学专业,目前也是AI/ML的Apple博士学者。他构建了检索模型以及基于检索的NLP系统,这些系统可以利用大型文本集合来高效透明地制作知识丰富的响应。Omar是ColBERT检索模型的作者,该模型是神经检索领域发展的核心,也是ColBERT-QA和Baleen等几个衍生NLP系统的作者。他最近的工作包括使用语言模型(LM)和检索模型(RM)解决高级任务的DSPy框架,以下是他近半年的会议演讲主题。



作为人工智能领域最具创新力的研究之一,DSPy给prompt工程带来了全新的编程范式。Omar在一次会议中提到,prompt工程应该将重点从调整 LM 转移到良好的总体系统设计上。而DSPy中模拟了可用于DNN(深度神经网络)的硬件,将LM 抽象为设备,通过类似于 DNN 的抽象概念执行指令。
你可能会认为:我的文章标题有些夸张,一是因为算法使然,要不你我不会因此结缘;二是的确如实反映了目前的发展状态和你的预期不一致,所以你会有文章标题夸张的感觉。可能事实过于残忍,但事实就是下面这张图上你看到的这样:手写Prompt已经被Signatures(签名)代替,各种CoT等牛X的Prompt技术被Modules封装,让你引以为傲的Prompt优化已经可以自动完成,而你却一无所知。

在这篇文章中,我们将带你深入探索DSPy的核心理念、实现步骤和三个难点(篇幅原因先介绍前两个),(看不懂代码没关系,多看看你也就明白了)展现它在提高语言模型效率和可解释性方面的独特优势。
伴随着ChatGPT、GPT-4等大型语言模型的出现,自然语言处理进入了一个全新的发展阶段。如今,研究人员和从业者面临的核心挑战不再是如何让模型"学会"完成某项任务,而是如何精准指导和调节这些庞大且通用的模型,使其输出满足特定应用场景的需求。
在此背景下,Prompt工程应运而生。通过精心设计的Prompt,人们可以指导语言模型按照某种预期的模式输出。然而,传统的Prompt工程依赖于大量的人工调试和试错,其效率和可重复性都受到了严重影响,prompt的脆弱性,大语言模型LLM的幻觉产生的精确性等问题,哪一个问题都是目前AI应用落地的绊脚石。DSPy的出现可能会彻底改变这种现状,它将Prompt工程转化为一个自优化过程,使语言模型的调用和应用变得更加高效和可解释。
DSPy的核心思想是将语言模型视为一种独特的"设备",类似于我们在深度学习中使用的CPU和GPU。在DSPy中,您只需声明所需的"自然语言签名"(Natural Language Signatures),而不必操心具体的Prompt实现细节(事实上我们经过一年的实践发现,你操心那些细节意义也不大,改变不了LLM输出不稳定的事实)。这样理解DSPy:根据这些签名,DSPy可自动生成、优化和微调Prompt,最终输出符合预期的结果。
为了实现上述过程,DSPy引入了三个关键概念:
1. 自然语言签名(Natural Language Signatures)
与其规定模型应如何被Prompt,不如直接说明它应该做什么。自然语言签名就是这样一种声明性描述,它只关注输入和期望输出,而不涉及具体实现。
例如,您可以声明一个签名为"输入为文档,输出为摘要"。根据这个签名,DSPy会自动生成合适的Prompt,无需您手动构造。这种抽象化的方式大大提高了灵活性和可重用性。


模块是对Prompt技术(如Chain of Thought、Program of Thought等)的抽象和封装。每个模块都关联一个自然语言签名,并内部实现了相应的Prompt流程。
您可以直接调用这些模块,而不必了解它们的具体实现细节。这为模块的复用和组合提供了基础,使构建复杂pipeline系统成为可能。


3. 优化器(Optimizers)
优化器的作用是将您的程序(由多个模块组成)自动编译为高质量的Prompt或微调后的模型权重,以最大化您所关注的指标。
在编译过程中,优化器会考虑多种因素,如Prompt指令、示例数据等,并通过离散优化寻找最优解。这确保了您的pipeline能够高效地产出所需的结果。
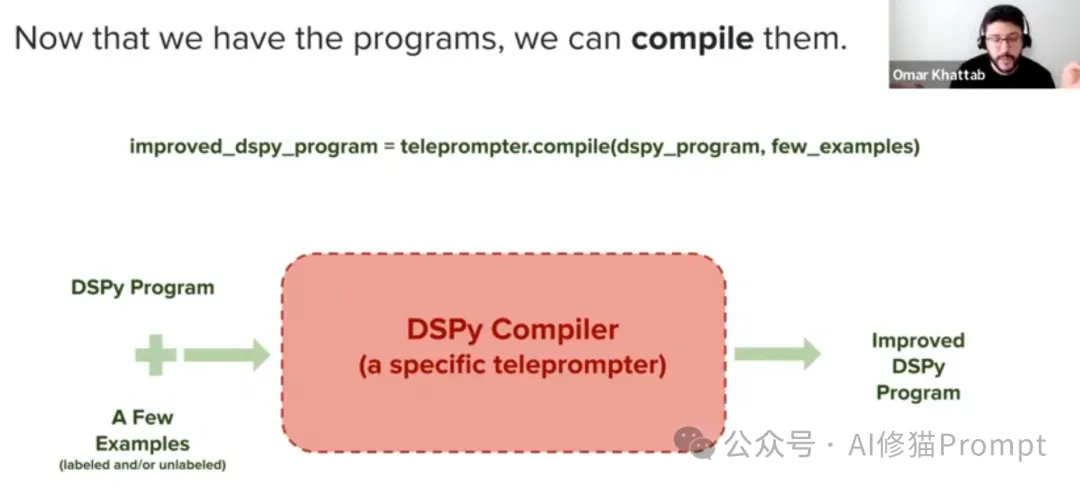

通过自然语言签名、模块和优化器的有机结合,DSPy实现了一种全新的"声明式"编程范式。您只需关注任务本身,而不必纠结于Prompt工程的具体细节。这不仅极大地提高了开发效率,也为复杂系统的构建和可解释性奠定了基础。
正如我们在下面讨论的,你将定义你的任务和你想要最大化的指标,并准备一些示例输入—通常没有标签(或者只有最终输出的标签,如果你的指标需要它们)。然后,通过选择要使用的内置层( modules ),为每个层指定 signature (输入/输出规范),然后在Python代码中自由调用模块来构建管道。最后,您可以使用DSPy optimizer 将代码编译为高质量的指令、自动少量示例或LM权重。
1)定义你的任务
如果没有定义要解决的问题,就不能很好地使用DSPy。
预期的输入/输出行为:您是否试图在您的数据上构建聊天机器人?密码助理?从论文中提取信息的系统?或者是翻译系统?或者是一个突出显示搜索结果中的片段的系统?或者是一个系统来总结一个主题的信息,并附有引用?
通常只给出3-4个程序输入和输出的例子是很有用的(例如,问题及其答案,或主题及其摘要)。
质量和成本规格:你可能没有无限的预算。最终的系统运行起来不会太昂贵,而且它应该能够足够快地响应用户。
2)定义你的管道
您的DSPy程序应该做什么?它可以只是一个简单的思想链步骤吗?或者你需要LM来使用检索?或者其他工具,比如计算器或日历API?
是否有一个典型的工作流程,可以通过多个明确定义的步骤来解决您的问题?或者你想要一个完全开放的LM(或开放式工具与代理一起使用)来完成你的任务?
想想这个空间,但总是从简单的开始。几乎每个任务都应该从一个单独的dspy.ChainofThought模块开始,然后逐渐增加复杂性。
然后编写您的(初始)DSPy程序。同样:从简单开始,让接下来的几个步骤指导你将添加的任何复杂性。
3)探索几个例子
到目前为止,你可能已经有了一些你试图解决的任务的例子。
通过你的管道运行它们。考虑在这一点上使用一个大而强大的LM,或者几个不同的LM,只是为了了解什么是可能的。(DSPy将使交换这些LM相当容易—LM指南。)
在这一点上,你仍然在使用你的管道zero—shot,所以它离完美还很远。DSPy将帮助您优化下面的指令,少量示例,甚至LM调用的权重,但了解零次使用中的错误将有很长的路要走。
记录下你尝试的有趣的(简单和困难的)例子:即使你没有标签,简单地跟踪你尝试的输入对下面的DSPy优化器也很有用。
4)定义您的数据
现在是时候更正式地声明用于DSPy评估和优化的训练和验证数据了—数据指南。
您可以使用DSPy优化器有效地使用10个示例,但拥有50-100个示例(甚至更好,300-500个示例)会有很长的路要走。
你怎么能得到这样的例子?如果你的任务是非常不寻常的,请投资准备~10个例子的手。通常情况下,根据下面的指标,你只需要输入而不是标签,所以这并不难。
然而,很有可能你的任务实际上并不是那么独特。你几乎总是可以找到一些相邻的数据集,比如说,HuggingFace数据集或其他形式的数据,你可以在这里利用。
如果有数据的许可证足够宽松,我们建议您使用它们。否则,您也可以开始使用/部署/演示您的系统,并以这种方式收集一些初始数据。
5)定义你的指标
是什么让你的系统输出是好还是坏?投资于定义指标,并随着时间的推移逐步改进它们。要持续改进你无法定义的东西真的很难。
指标只是一个函数,它将从您的数据中获取示例,并获取系统的输出,然后返回一个量化输出有多好的分数-指标指南。
对于简单的任务,这可能只是“准确性”或“精确匹配”或“F1分数”。这可能是简单分类或简短形式QA任务的情况。
但是,对于大多数应用程序,您的系统将输出长格式输出。在那里,你的指标可能应该是一个较小的DSPy程序,检查输出的多个属性(很可能使用来自LM的AI反馈)。
在第一次尝试时就做到这一点是不可能的,但你应该从简单和容易的事情开始。(If你的指标本身就是一个DSPy程序,请注意,最强大的方法之一是编译(优化)你的指标本身。这通常很容易,因为度量的输出通常是一个简单的值(例如,满分为5分),因此该指标的指标很容易通过收集一些示例来定义和优化。
6)收集初步的“Zero/Few shot”评价
现在您已经有了一些数据和指标,在运行任何优化器之前,在管道上运行评估。看看输出和指标分数。这可能会让你发现任何重大问题,并为你的下一步定义一个基线。
7)使用DSPy优化器编译
给定一些数据和指标,我们现在可以优化您构建的程序—优化器指南。
DSPy包括许多做不同事情的优化器。请记住:DSPy优化器将创建每个步骤的示例,工艺指令和/或更新LM权重。一般来说,您不需要为管道步骤提供标签,但您的数据示例需要具有输入值和指标所需的任何标签(例如,如果指标是无引用的,则没有标签,但在大多数情况下,最终输出标签除外)。
以下是优化器入门的一般指导:
如果你只有很少的数据,例如10个任务示例,使用 BootstrapFewShot
WithRandomSearch 。
如果你有更多的数据,例如300个或更多的例子,使用 MIPRO 。
如果你已经能够使用其中一个与一个大的LM(例如,7B参数或以上),并需要一个非常有效的程序,编译到一个小LM与 BootstrapFinetune 。
8)迭代
在这一点上,你要么对一切都很满意(我们已经看到相当多的人在第一次尝试DSPy时就做对了),或者更有可能的是,你已经取得了很大的进展,但你不喜欢最终的程序或指标。
在这一点上,回到步骤1,重新审视主要问题。你是否很好地定义了你的任务?您是否需要为您的问题收集(或在线查找)更多数据?你想更新你的指标吗?你想使用更复杂的优化器吗?您是否需要考虑像DSPy断言这样的高级功能?或者,也许最重要的是,您是否希望在DSPy程序本身中添加更多的复杂性或步骤?你想在一个序列中使用多个优化器吗?
迭代开发是关键。DSPy为您提供了增量执行的部分:迭代您的数据、程序结构、断言、度量和优化步骤。
以上8步,最为关键和难以理解的是度量Metric、断言Assertions和优化器Optimizers ,篇幅原因只讲前两个。
DSPy的Mretrics是一个Python函数,它根据您的数据评估程序的输出,提供一个分数来量化性能—越高越好。度量函数涉及三个参数:数据集的示例 example ,程序的输出(也称为预测)和 trace ,我们现在将其放在一边。这个函数的本质是返回一个分数,它可以表现为 float 、 int 或 bool 。
DSPy Assertions
断言部分您可以看一下作者的一篇论文DSPy Assertions,里面对Assertion的作用、原理做了详尽的解释:
LLM断言的本质
Assertion,这个词除了断言还可以翻译为声明、申述、宣称、表态、明确断定,明确主张,在DSPy语境下,你意译成为LLM明确主张会对后续理解有所帮助。LLM断言是一种程序化元素,用于规定LLM管道执行时必须满足的条件或规则。这些约束可确保管道的行为符合开发人员指定的不变量或准则,从而提高输出的可靠性、可预测性和正确性。
研究人员将LLM断言分为两个独特的构造:断言(Assertions)和建议(Suggestions),分别用Assert和Suggest表示。它们是强制执行约束和指导LLM管道执行流程的构造。
Suggest与Assert的区别
与Assert不同,Suggest语句代表较为宽松的约束,建议但并不强制执行可能指导LLM管道朝着预期结果发展的条件。当建议条件不满足时,管道也会进入特殊的重试状态,允许重新尝试失败的LLM调用并进行自我完善。然而,与Assert不同的是,如果建议在最大重试次数后仍然失败,管道只会记录一条SuggestionError警告消息,而不会引发异常,而是继续执行下一个模块。这使得管道能够根据建议调整行为,同时保持灵活性和对次优状态的容错性。
基于断言的示例引导
LLM断言不仅可用于运行时监控,还可用于优化提示。DSPy中的BootstrapFewShot优化器采用教师-学生方法,使用教师模型为同一程序的学生模型引导代表性的少量示例。在引导步骤中,教师模型可以利用LLM断言作为额外的过滤器,引导出更加健壮的示例。
基于研究人员的观察,在某些情况下,DSPy中的naive优化器会引导出一个示例,其最终响应是正确的,但中间模块输出却是错误的,这导致了中间LLM模块的错误示例。为了启用基于断言的示例引导,研究人员在BootstrapFewShot优化器中对教师模型应用断言驱动的回溯。通过这种方式,所有引导的示例都保证遵循中间约束。尽管提示优化器只有最终答案的指标,但所选择的示例对于所有中间模块都具有更高的质量,这要归功于LLM断言。
在论文中,作者介绍了一个名为MultiHopQA的程序,用于多跳问答任务。它由三个模块组成:
这篇论文DSPy Assertions验证了三个主要假设:
假设1:LLM断言确实能够通过在提示中显示过去的输出和错误信息,促进任意LLM管道的自动自我纠正和完善。
假设2:通过自我纠正,确实能为LLM管道带来更好的下游性能。
假设3:在提示优化中使用LLM断言,可以更好地引导和优化少量示例。
通过大量实验,他们证实了LLM断言在促进LLM自我完善、提高下游应用性能和引导高质量少量示例方面的卓越能力。
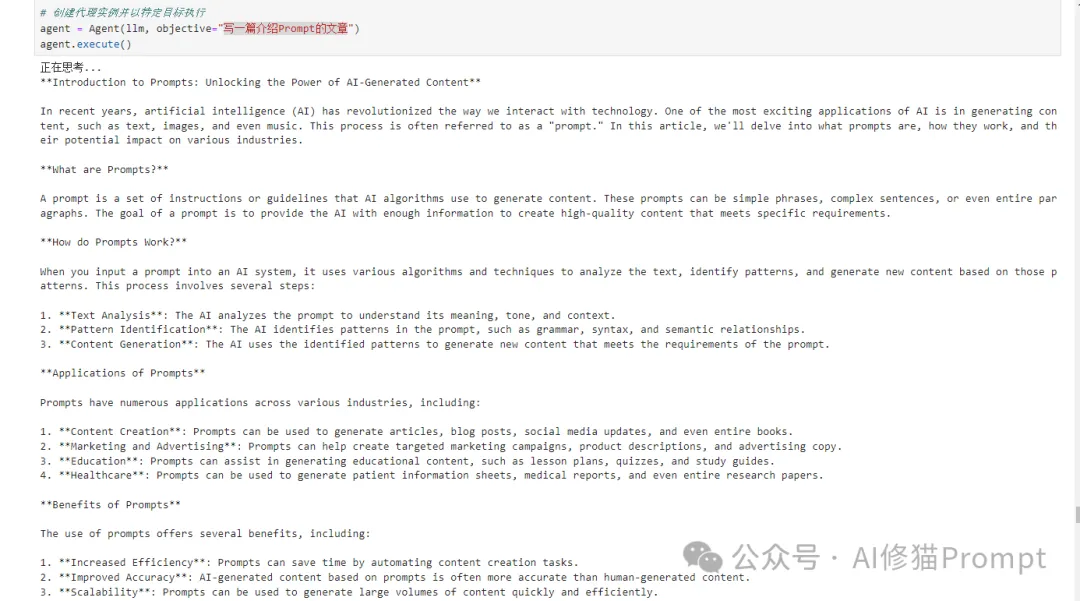
篇幅原因,关于优化器Optimizers 部分后续我写文章专门介绍。但在所有的模块中,我认为您应该最先理解或掌握的是signature和module部分,因为你一旦掌握这两个部分,就可以构建很多应用,比如,我原先写过不少Agent,发现这个DSPy后,我立即试了一下,效果还不错,尽管还有很多需要优化的地方,但不到100行代码,就可以作为Agent执行很复杂的推理任务,效果还不错。
在这个Agent中,我使用了有限状态机transitions这个Python的第三方库。有限状态机(Finite State Machine, FSM)是一种数学计算模型,它具有一系列的状态,以及规定如何从一个状态转移到另一个状态的规则。有限状态机广泛应用于计算机科学、编译器设计、人工智能、通信协议等诸多领域。使用transitions库,你也可以轻松地用面向对象的方式构建有限状态机模型,而不必从头编写复杂的状态转移逻辑。它使代码更加模块化、易于维护和扩展。以下是Agent的部分输出,全部输出一次有15000多Token
DSPy不仅解决了Prompt工程的效率和可解释性问题,更为构建复杂AI系统奠定了坚实基础。我认为它体现了人工智能发展的四个重要趋势:
本文来自微信公众号”AI修猫Prompt“




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
