OneReason:当推荐系统学会思考
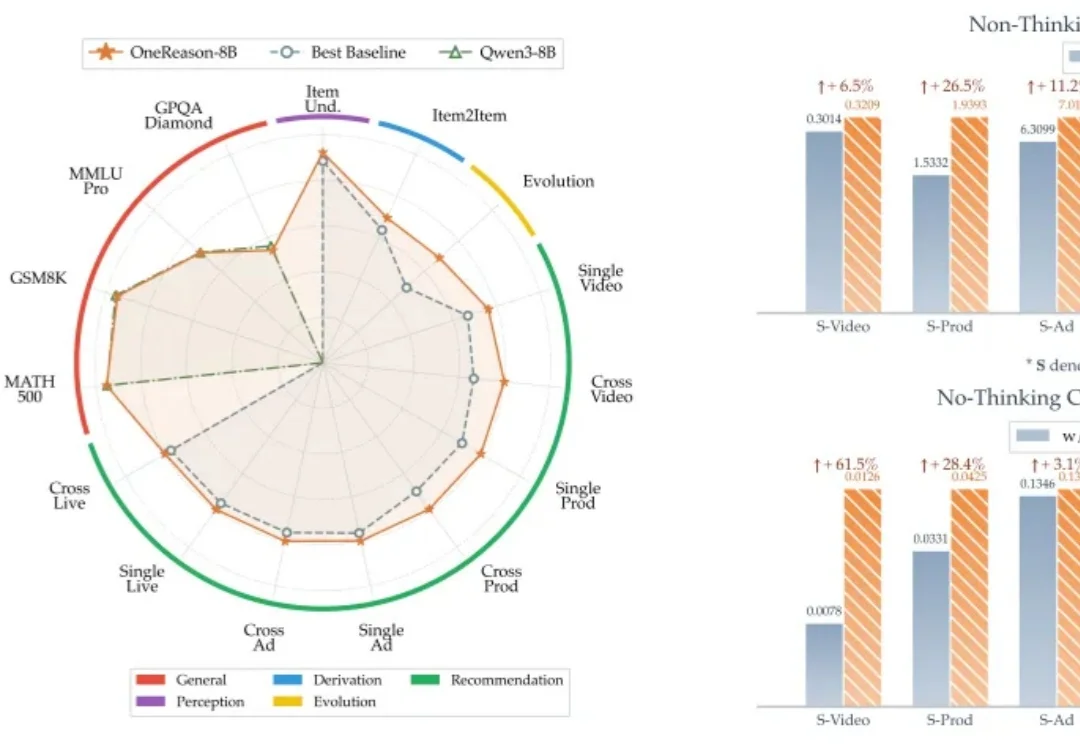
OneReason:当推荐系统学会思考推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。
来自主题: AI技术研报
8317 点击 2026-06-10 14:43
 搜索
搜索
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。

5 月 20 日,武汉光谷。极佳视界(GigaAI)在「家庭场景子品牌发布会暨物理通用智能技术发布会」上,给出了一份相对完整的答案。这场发布会公布了五件事:全球首个物理 AGI「双金字塔」体系;家庭场景子品牌「拾光 SeeLight」与首款家庭通用人形机器人「拾光 S1」同步亮相;国内首个真实家庭场景百台部署落地武汉,Q3 起规模化运营;

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
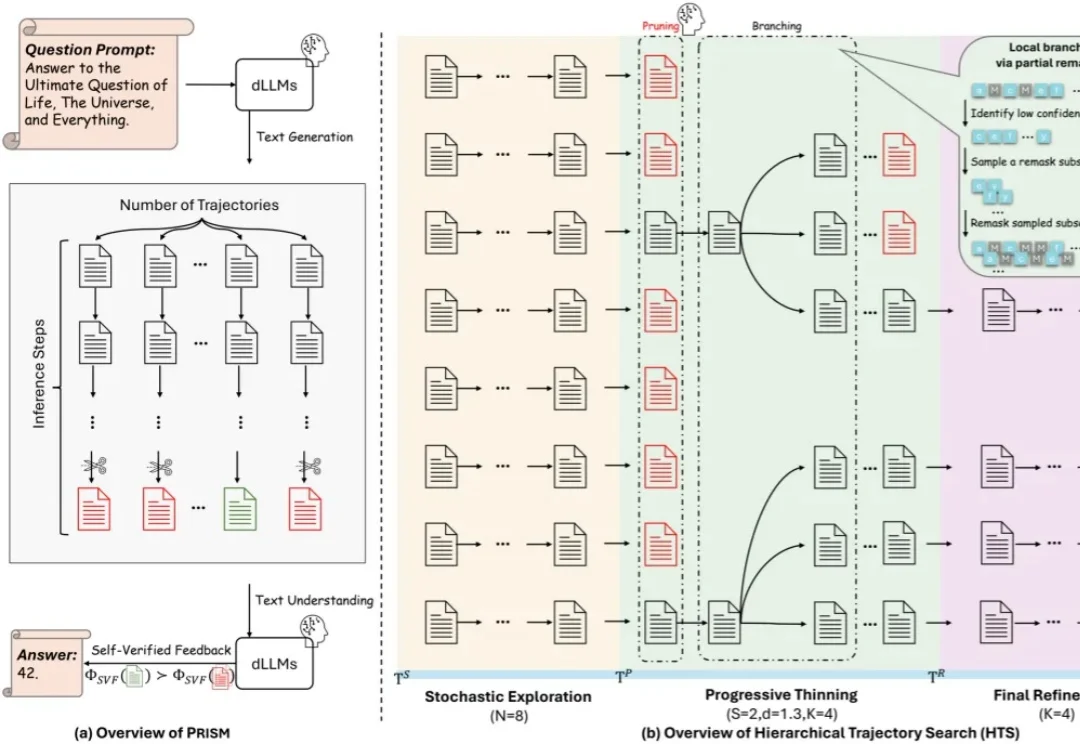
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining

今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

AlphaGo 之父 David Silver 创办的 Ineffable Intelligence 获 11 亿美元种子轮,创欧洲融资纪录,估值达 51 亿美元。这家公司押注强化学习和自我经验学习,试图挑战依赖 Scaling Law 的大模型主线。