
刚刚!谷歌内部揭秘Genie 3:Sora后最强AI爆款,开启世界模型新时代
刚刚!谷歌内部揭秘Genie 3:Sora后最强AI爆款,开启世界模型新时代Genie 3来了!这或许是最接近「模拟世界」的AI魔法。只需一句话,它就能生成一个动态、可互动的世界——角色能互动、下水会溅起水花,甚至还能记住一分钟前的细节。DeepMind研究者直言:Genie 3是通向AGI的关键一步。
来自主题: AI资讯
8610 点击 2025-08-18 10:54
 搜索
搜索
Genie 3来了!这或许是最接近「模拟世界」的AI魔法。只需一句话,它就能生成一个动态、可互动的世界——角色能互动、下水会溅起水花,甚至还能记住一分钟前的细节。DeepMind研究者直言:Genie 3是通向AGI的关键一步。

具身智能「大脑」,更准确地,以「世界模型」为内核的具身智能「大脑」会成为 AI 下一阶段竞争焦点吗? 上世纪九十年代,「世界模型」思想雏形初现,之后几十年被不断强化、延伸,直到 ChatGPT 引爆 AI 新浪潮、Sora 问世、大模型落地成主流、具身智能迎来新纪元……「世界模型」或是通往「类人智能」的解法被视为新的业界共识。
AI视频生成进入了秒生极速时代!UCSD等机构发布的FastWan系模型,在一张H200上,实现了5秒即生视频。稀疏蒸馏,让去噪时间大减,刷新SOTA。

你可能听说过OpenAI的Sora,用数百万视频、千万美元训练出的AI视频模型。 但你能想象,有团队只用3860段视频、不到500美元成本,也能在关键任务上做到SOTA?
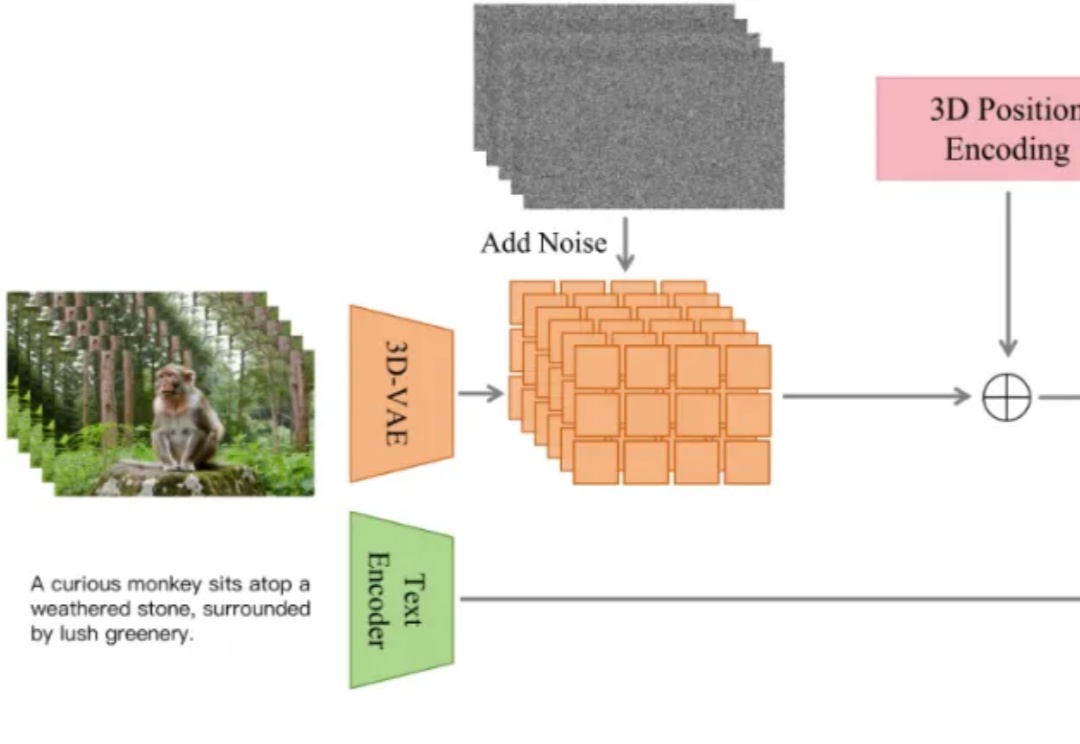
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
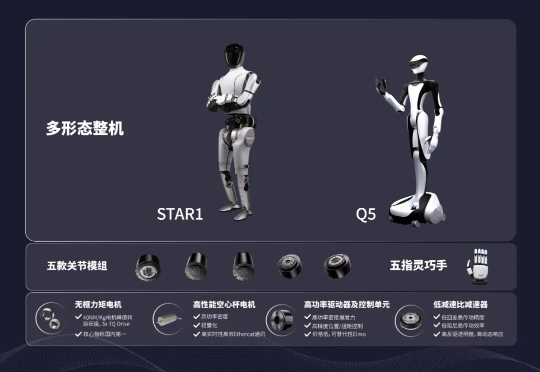
新皮层独家获悉,具身智能公司星动纪元近期完成近5亿元A轮融资。这是该公司自2023年8月成立以来完成的第4轮融资,最近一次是去年10月近3亿元的Pre-A轮。本轮融资由鼎晖资本和海尔资本联合领投,厚雪资本、华映资本、襄禾资本、丰立智能等财务机构及产业资本跟投,老股东清流资本、清控基金等机构继续追加投资;华兴资本担任独家财务顾问。

今天,百度AI Day上双杀全场!自研多模态大模型MuseSteamer携「绘想」平台重磅上线,视频创作直接杀进电影级AI时代。同时,百度搜索迎十年最大改版,体验全面开挂。

AI视频生成,Midjourney终于落下大锤了!今天,V1视频生成模型正式上线,每一帧效果超逼真,网友上手实测惊掉下巴。
近日,抖音内容技术团队开源了 ContentV,一种面向视频生成任务的高效训练方案。该方案在多项技术优化的基础上,使用 256 块 NPU,在约 4 周内完成了一个 8B 参数模型的训练。尽管资源有限,ContentV 在多个评估维度上取得了与现有主流方案相近的生成效果。

Manus疯狂更新,视频生成也来了!