
“游戏圈野蛮人”跳进AI火坑,周亚辉要“拳打Netflix、脚踢Spotify”!
“游戏圈野蛮人”跳进AI火坑,周亚辉要“拳打Netflix、脚踢Spotify”!昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。
来自主题: AI资讯
8943 点击 2026-05-02 13:36
 搜索
搜索
昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。
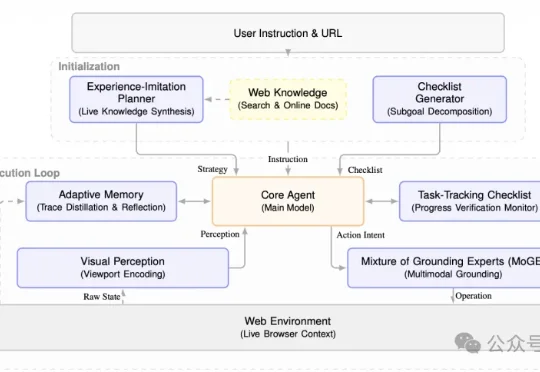
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。
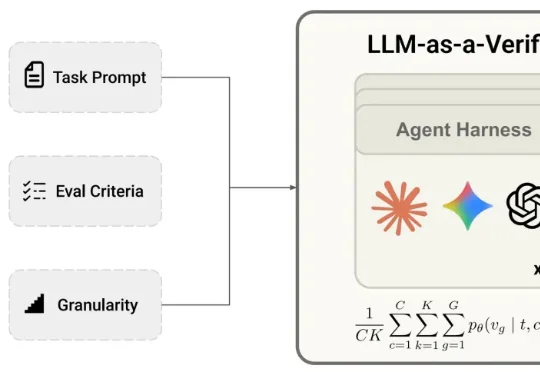
Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
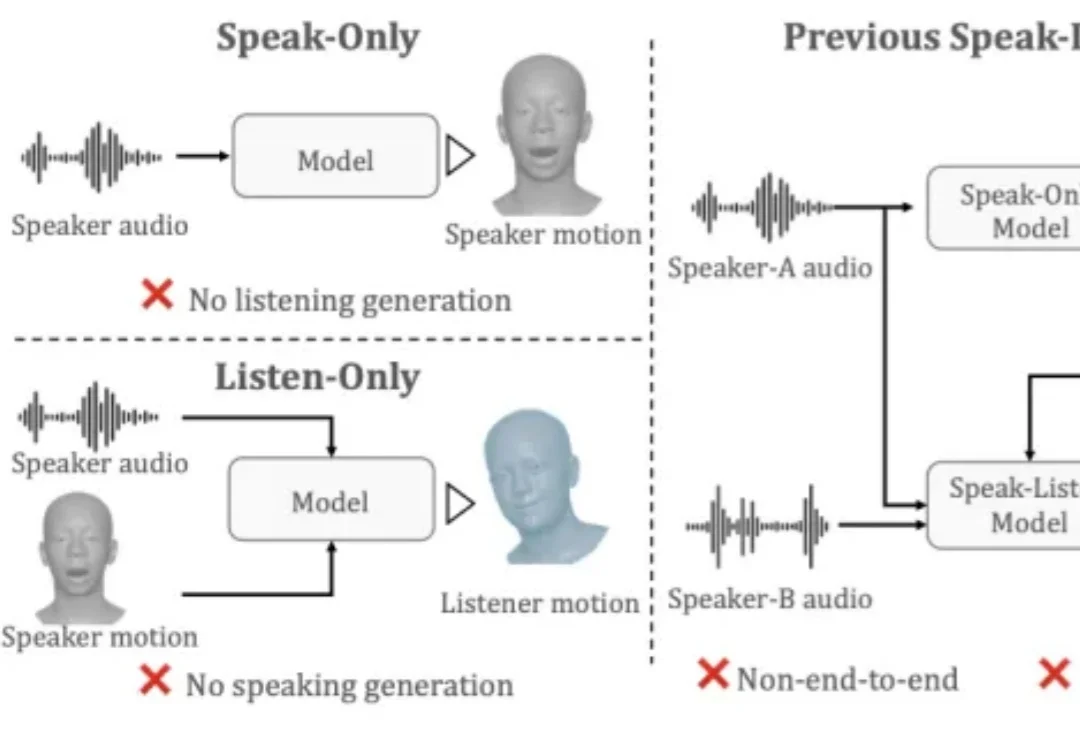
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。
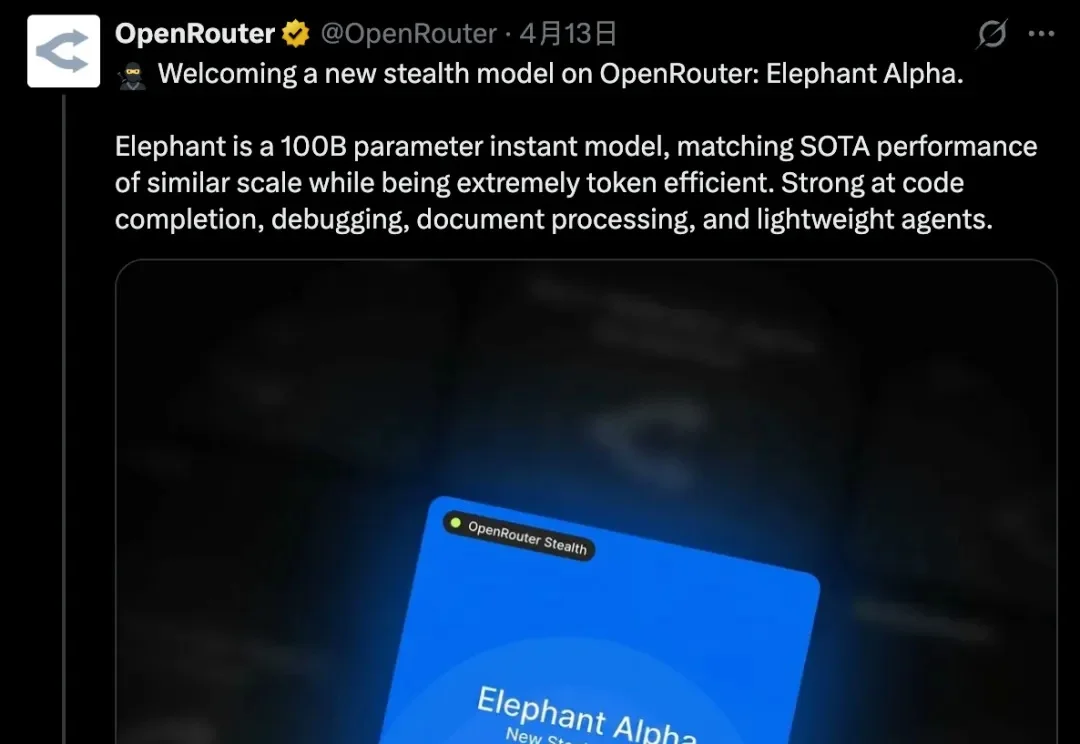
神秘模型Elephant的面纱,终于被揭开了。
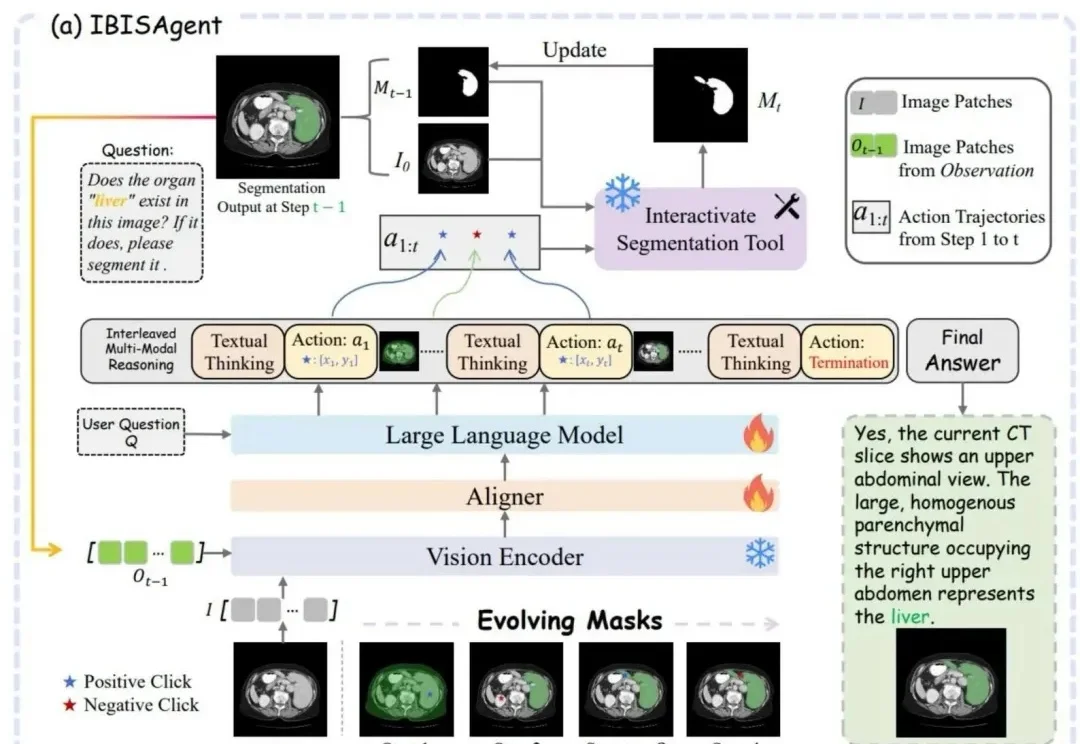
这个生物医学视觉推理框架,被CVPR 2026接收了!

有没有想过让「龙虾」替你打麻将?
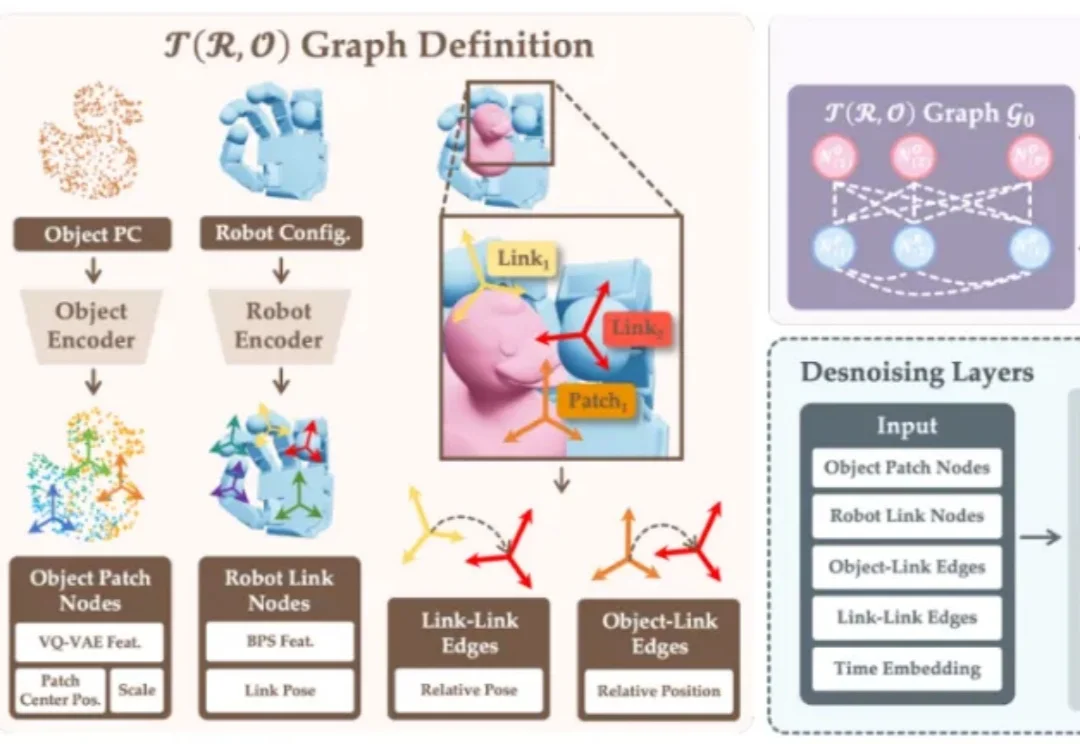
T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。