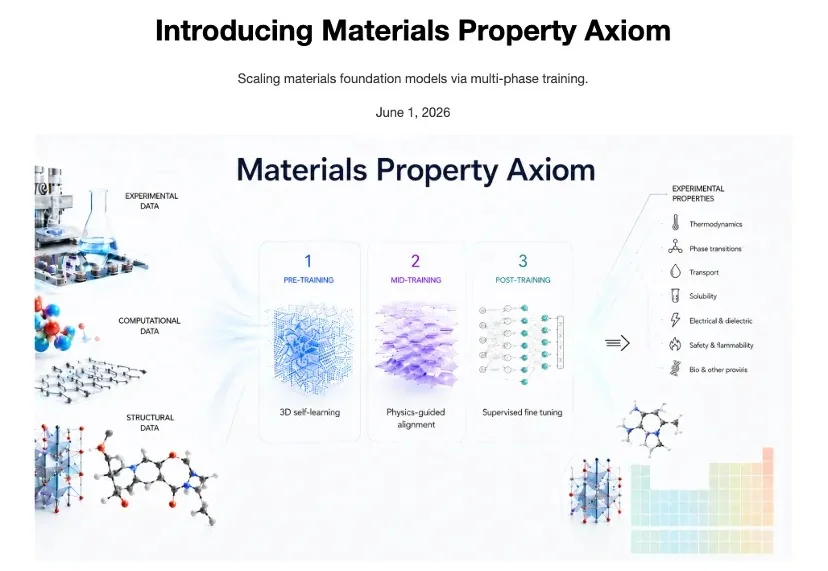
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。
来自主题: AI技术研报
6607 点击 2026-06-02 15:23
 搜索
搜索
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。

AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
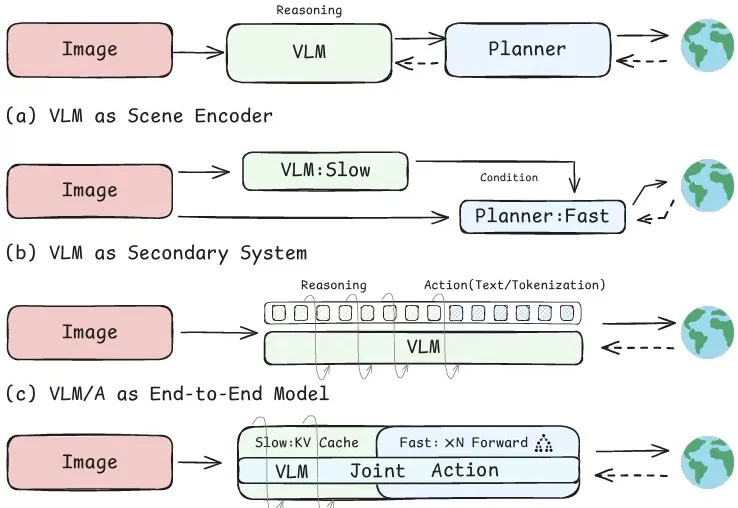
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
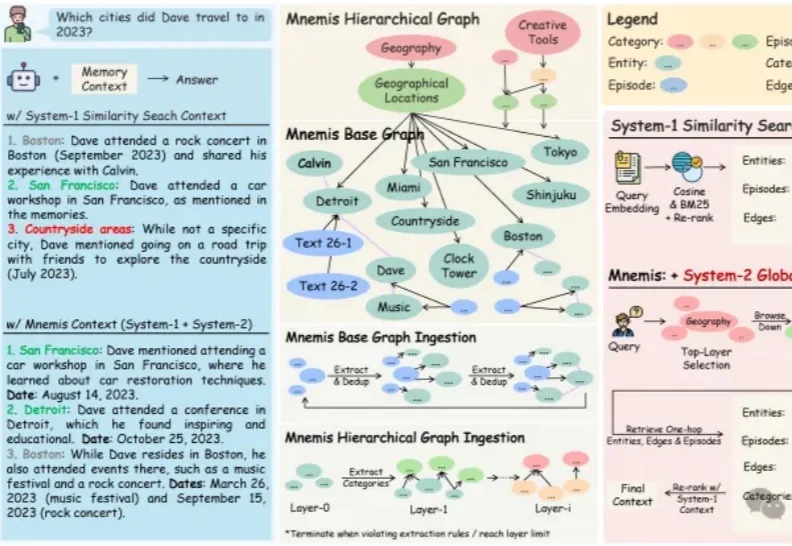
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

顶级大佬Elad Gil抛出残酷真相:顶级实验室员工领先硅谷4个月,硅谷领先世界1年。你引以为傲的SOTA,在实验室里可能早已是淘汰的旧引擎。
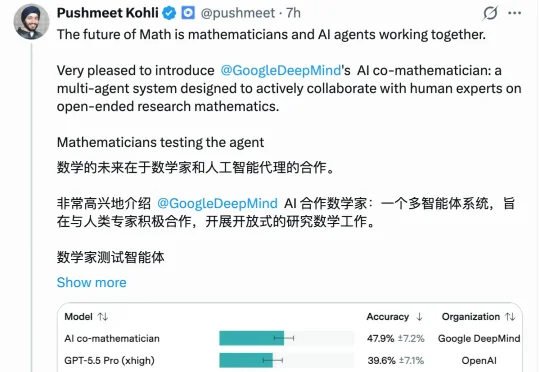
群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。
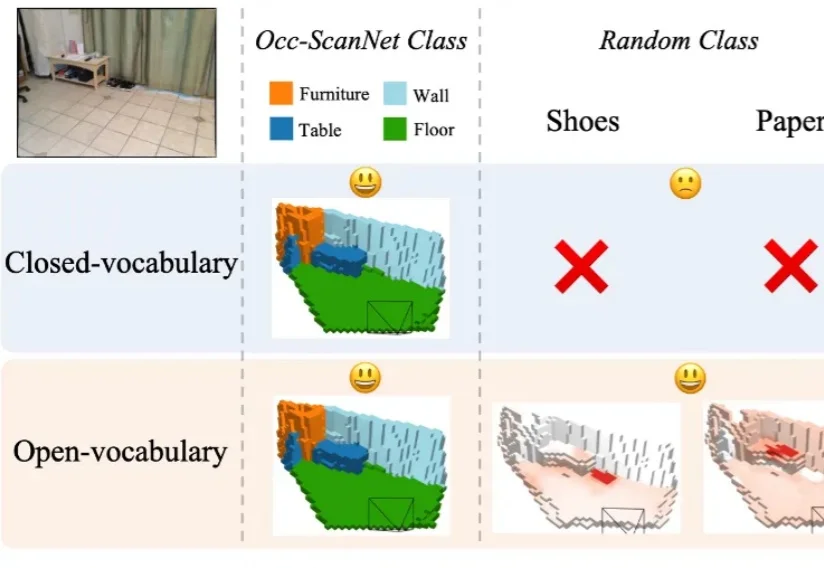
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」