蚂蚁再把医疗AI卷出新高度!蚂蚁·安诊儿医疗大模型开源即SOTA
蚂蚁再把医疗AI卷出新高度!蚂蚁·安诊儿医疗大模型开源即SOTA就在医疗AI赛道激战正酣时,一个搅局者低调入场了。它就是蚂蚁集团联合浙江省卫生健康信息中心、浙江省安诊儿医学人工智能科技有限公司开源的医疗大模型——蚂蚁·安诊⼉(AntAngelMed)。
来自主题: AI资讯
9969 点击 2026-01-10 17:03
 搜索
搜索
就在医疗AI赛道激战正酣时,一个搅局者低调入场了。它就是蚂蚁集团联合浙江省卫生健康信息中心、浙江省安诊儿医学人工智能科技有限公司开源的医疗大模型——蚂蚁·安诊⼉(AntAngelMed)。

2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。

在 Anthropic 成立五周年前夕,联合创始人兼总裁 Daniela Amodei 罕见接受了公开采访!

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。
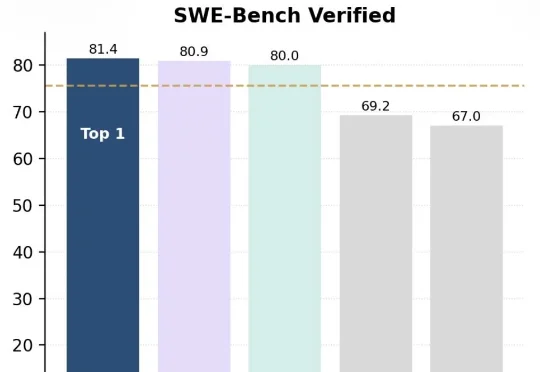
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。

刚刚,由SciMaster团队推出的AI机器学习专家ML-Master 2.0,基于国产开源大模型DeepSeek,在OpenAI权威基准测试MLE-bench中一举击败Google、Meta、微软等国际顶流,刷新全球SOTA,再次登顶!目前该功能已在SciMaster线上平台开放waiting list,欢迎申请体验。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。

MiniMax最新旗舰级Coding & Agent模型M2.1,刚刚对外发布了。这一次,它直接甩出了一份硬核成绩单,在衡量多语言软件工程能力的Multi-SWE-bench榜单中,以仅10B的激活参数拿下了49.4%的成绩,超越了Claude Sonnet 4.5等国际顶尖竞品,拿下全球SOTA。
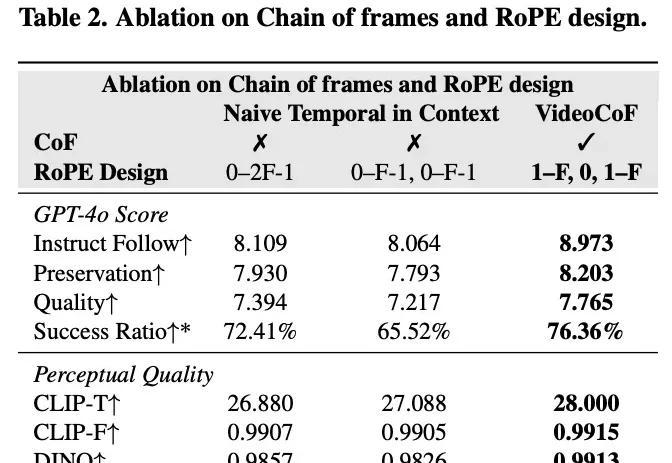
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。