# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
下一步,大模型应该押注什么方向?
蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。

实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。
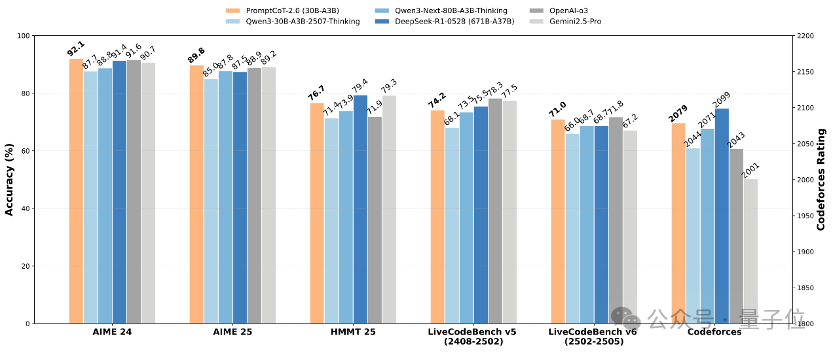
在一年前的这个时候,在整个AI社区都在思考大模型应该押注什么方向的时候,OpenAI公布了o1的预览版,通过深度思考的新范式以及在竞赛数学代码任务上远远甩开gpt4o的性能,让整个大模型社区进入了“深度思考”时代。
如今,又是一年9月,蚂蚁与港大联合在大模型下半场押注任务合成。
为什么是任务合成?
事实上,按照OpenAI规划的AGI蓝图,大模型社区正在从Reasoners向Agents急速推进,各种关于Agent的工作,包括搜索、软件工程、客服、以及GUI等层出不穷。
在这林林总总的工作背后,团队认为,无论是对大模型推理,还是对于方兴未艾的智能体,有两项技术是起着基石作用的:
一是强化学习。作为强化学习之年,该项技术已经得到社区足够多的关注与投入,无论是方法还是框架都在急速推进。

而另一个,团队认为是任务合成。这里的任务合成是一个比较广泛的概念,可能包含问题合成、答案合成、环境合成、乃至评估合成。之所以将其和强化学习并列起来,团队有一些底层思考。
①当大模型走出数学代码竞赛之后,必然要面对的是现实世界中长尾而又复杂的问题,而“长尾”和“复杂”两个属性叠加在一起,就会导致一个数据稀缺的问题。没有一定量高质量(难度合适、覆盖全面)的任务数据作为起始点,无论强化学习多么强大,也没法发挥作用,甚至没法开始;
②当大模型变得越来越智能之后,可以预见合成数据的质量会越来越高,那么有一天,合成数据也许会取代人工数据成为大模型训练的主力。
强化学习是引擎,任务合成提供燃料,这是团队对未来大模型后训练范式的一个判断。
在这样的判断下,团队首先从问题合成切入,力图发展一套通用且强力的问题合成框架。这样的选择一是任务合成的课题比较庞大;二是问题合成可以说是任务合成的基石和起点。
早在今年年初,团队就提出了PromptCoT框架,通过将“思考过程”引入问题合成来提升合成问题的难度。

在这个框架下,团队将问题合成拆解成了概念抽取、逻辑生成、以及问题生成模型训练三个步骤。按照这三个步骤,通过精心构造的提示词生成了一批问题合成训练数据,并由此训练了一个基于Llama3.1-8B的问题生成模型。
利用这个模型,团队生成了400k SFT数据,并用这份数据训练了DeepSeek-R1-Distill-Qwen-7B模型,在MATH-500、AIME 2024以及AIME 2025上的表现均超过了32B的s1模型。
在开源模型性能不断刷新的浪潮下,团队也在思考:
为了回答这些问题,团队推出了PromptCoT 2.0。
PromptCoT 2.0为一个可扩展框架,它用期望最大化(EM)循环取代了人工设计,在循环中,推理链会被迭代优化以指导提示构造。这样生成的问题不仅更难,而且比以往语料更加多样化。
PromptCoT 2.0在PromptCoT 1.0基础上,实现了效果、方法、数据的全面升级。
前面已经展示了PromptCoT 2.0+强化学习让强推理模型达到新SOTA的结果。那么如果用PromptCoT 2.0合成的问题进行蒸馏来训练弱推理模型,效果会怎样呢?
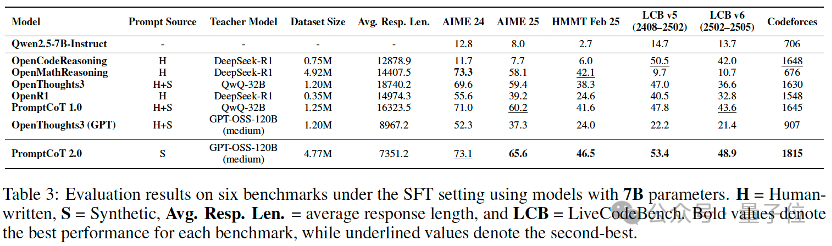
从表里可以看到,在完全不依赖人工问题的情况下,PromptCoT 2.0大幅提升了弱模型的数学与代码推理能力,且整体表现优于依赖人工问题构建的数据集(如OpenMathReasoning、OpenCodeReasoning)。
这一结果充分说明,相较于人工数据,合成数据具备更强的可扩展性,未来有望成为推动大模型推理能力提升的核心动力。与此同时,团队使用的教师监督(来自GPT-OSS-120B-medium)在表达上更为紧凑(平均推理长度更短)。在保证高质量的前提下,较短的输出不仅减少了推理开销,也为更高效的大模型训练和推理提供了新的可能。
更重要的是,团队此次全面开源了4.77M个合成问题及对应的教师监督,供社区进行模型训练,特别是一些不适于LongCoT的模型(如扩散语言模型)。
在数据层面,开源的4.77M合成数据展现出两个显著特征:
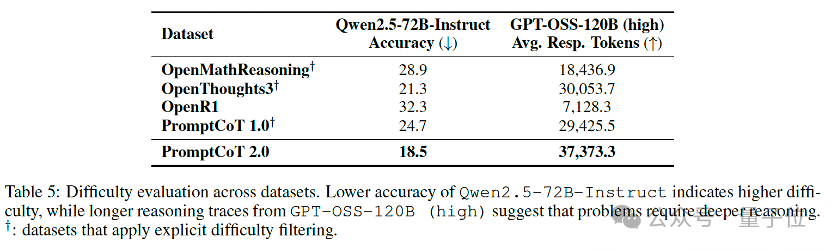
1、更难:在零微调评测下(例如直接使用强指令模型解题),PromptCoT 2.0表现为更低的即刻正确率和更高的推理token消耗,说明这些题目更能“咬合推理”,有效挖掘模型潜在的推理上限。
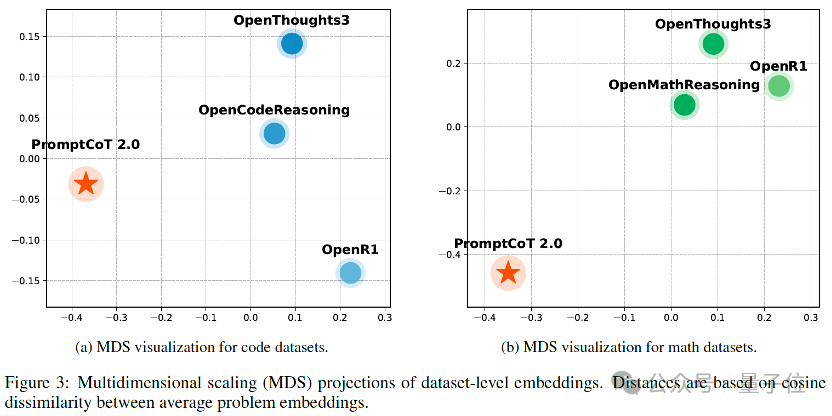
2、更具差异化:基于all-MiniLM-L6-v2的嵌入均值与余弦距离,并通过MDS映射到二维空间后,PromptCoT 2.0的数据点与现有开源题集(OpenMathReasoning、OpenThoughts3、OpenR1 等)形成了独立分簇,而后者之间分布更为接近。
这表明 PromptCoT 2.0并非简单重复已有题库,而是补充了其中缺失的“困难+新颖”区域,为模型训练提供了额外的分布层增益。
PromptCoT 2.0在PromptCoT 1.0基础上引入基于期望最大化(EM)的优化过程,使逻辑生成模型和问题生成模型能够在迭代中相互促进。
具体而言,E-step通过奖励信号不断优化逻辑生成,使其更契合概念并支撑问题构造;M-step则利用这些逻辑持续改进问题生成模型。与以往依赖人工提示或特定领域规则的方式不同,PromptCoT 2.0完全可学习、跨领域通用,能够在几乎无需人工干预的情况下,生成更具挑战性和多样性的问题。
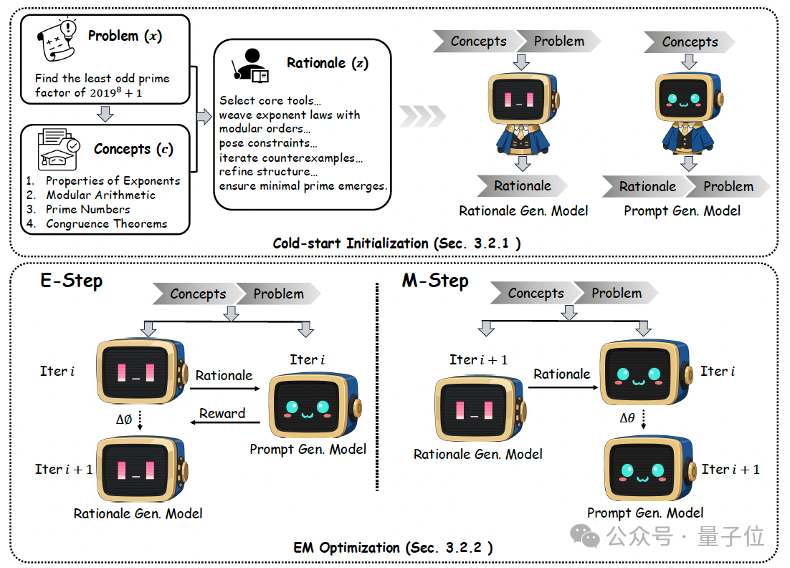
在后训练上,除了SFT,PromptCoT 2.0采用了一种强化学习方法。在给定奖励信号的情况下,PromptCoT 2.0从合成问题出发,让强基线模型通过自我探索推理路径来进行学习。实际优化兼容PPO、GRPO、DPO等各种在线离线强化学习方法。
这里PromptCoT 2.0对奖励信号要求较低,只要相对易得,可以包含一定噪音(实验中采用对数学代码分别采用的是GPT-OSS-120B和Qwen3-32B)。在这种情况下,强基线模型就可以通过自博弈方式从自我经验中进行学习提升。
尽管实现了大幅升级,但从任务合成来看,PromptCoT 2.0仍只是起点。下一步,PromptCoT将会考虑几个方向:
1、Agentic环境合成。不仅出题,还要“造环境”(网页、API、GUI、代码沙盒、对话场景),让模型在可交互、可验证的世界里学会规划、操作与反思。
2、多模态任务合成。把图像/视频/表格/语音等信息纳入“概念→逻辑→任务”的模式,催生跨模态推理与工具使用。
3、自奖励和对局式自进化。 在社区中,已有一些自奖励以及基于“两方博弈”的自进化探索,例如“出题者–解题者”或“执行者–评审者”的对抗协作模式。这些探索为大模型发展提供了很好的思路,但却没法实现强基座模型下的SOTA效果。
那么,如果PromptCoT和自奖励相结合,或者EM内循环与博弈式外循环相结合,有没有可能进一步提升模型上限呢?
时间很紧,可做的却很多,在PromptCoT 2.0发布之际,下一个PromptCoT也已经在路上了。
该工作的第一作者为香港大学计算机系博士生赵学亮,目前在蚂蚁技术研究院通用人工智能中心实习。蚂蚁技术研究院通用人工智能中心自然语言组武威、关健、龚卓成为共同贡献者。
论文链接:https://arxiv.org/abs/2509.19894
Github链接: https://github.com/inclusionAI/PromptCoT
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
