VLA模型为何忽视语言?破解指令跟随幻觉,分布外场景泛化新突破
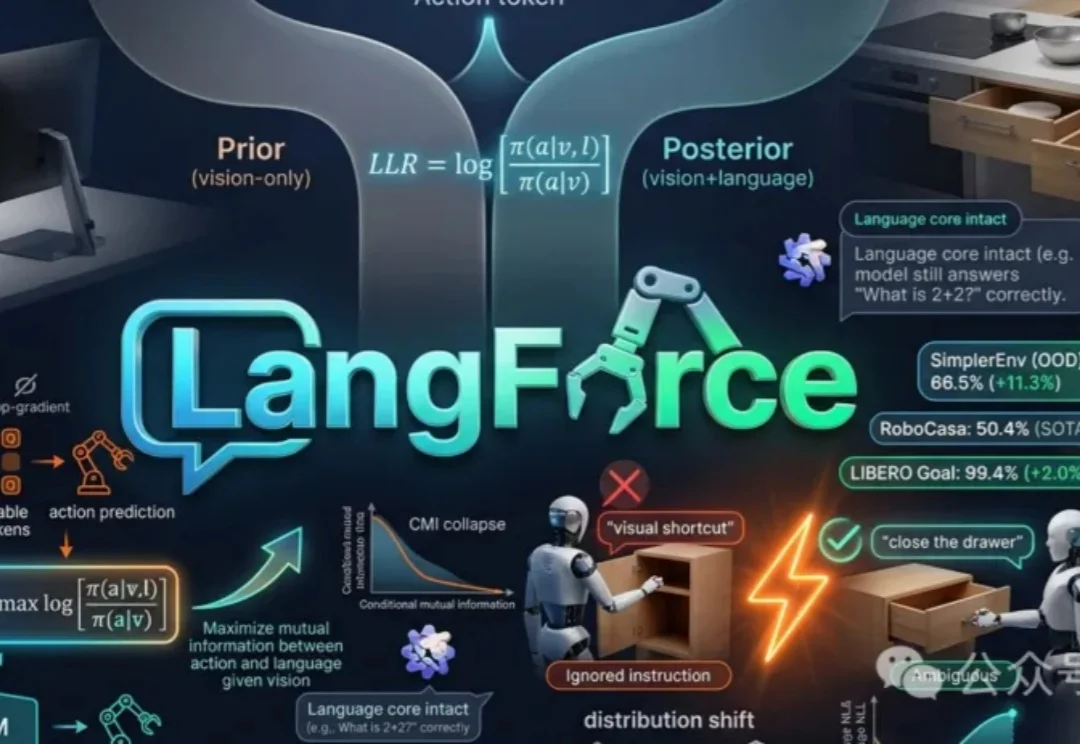
VLA模型为何忽视语言?破解指令跟随幻觉,分布外场景泛化新突破当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
来自主题: AI技术研报
9536 点击 2026-05-13 15:00
 搜索
搜索
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
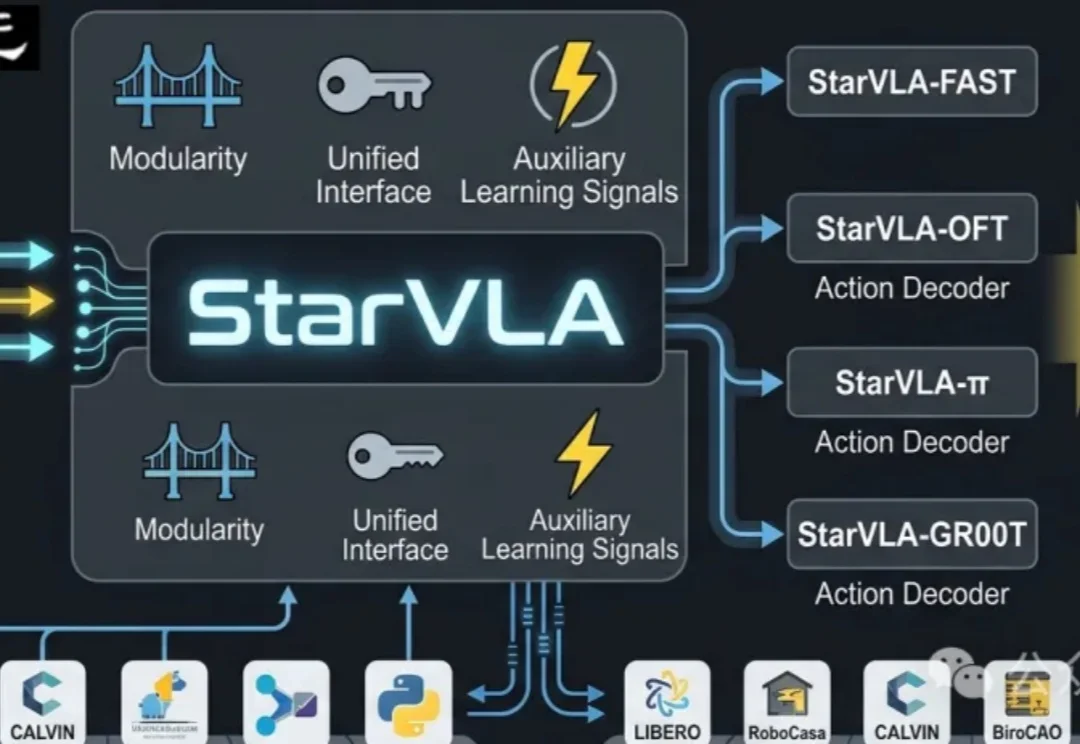
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。