
不给现金,只给超3亿美元Token!Sam Altman开始“拿算力换股份”:向169家YC公司发200万美元Token,但要拿股权来换
不给现金,只给超3亿美元Token!Sam Altman开始“拿算力换股份”:向169家YC公司发200万美元Token,但要拿股权来换当年互联网创业公司最熟悉的“羊毛”,是云厂商送的服务器额度;现在,AI 创业圈的“新硬通货”,已经变成了大模型 Token。
来自主题: AI资讯
6686 点击 2026-05-26 10:27
 搜索
搜索
当年互联网创业公司最熟悉的“羊毛”,是云厂商送的服务器额度;现在,AI 创业圈的“新硬通货”,已经变成了大模型 Token。
最近,GPT-5.6泄露了!150万Token+神级极简UI,下月紧急上线,奥特曼的「超级智能体」要掀翻整个硅谷?6月AI大战,已经提前爆发了。
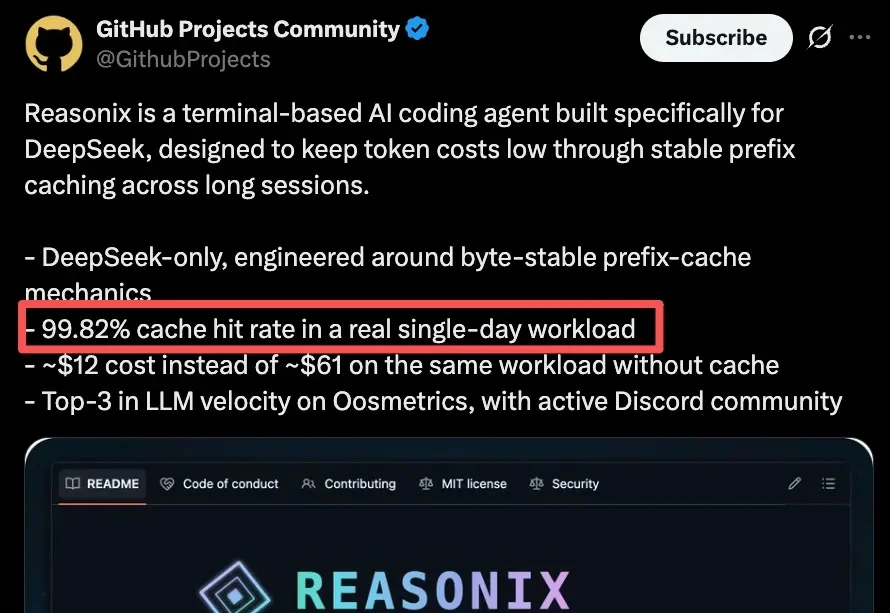
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

亚马逊给员工的AI工具装了计量器,官方说不考核,经理盯着排行榜不放。Meta内部榜单30天烧掉60万亿token,扎克伯格没进前250。然而Jellyfish数据打脸:刷10倍token,产出只多了1倍。谁在为这场荒诞游戏推波助澜?
大家好,我是袋鼠帝。 不知道大家有没有发现,随着AI的发展,token这个东西居然还变得越来越贵了。

“Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。”
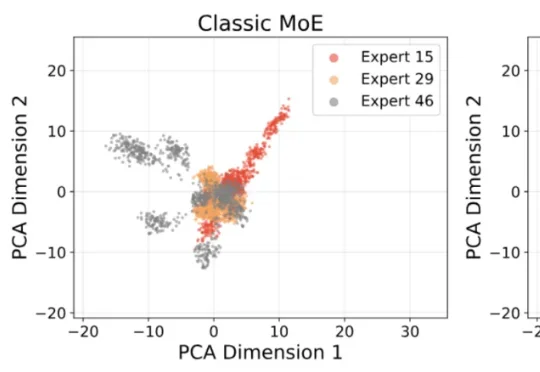
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。

Token之战要追求数量,更要追求质量。

iOS用户还要再等等。