
面壁智能开源Agent神器PilotDeck,让Token成本狂降70%!
面壁智能开源Agent神器PilotDeck,让Token成本狂降70%!刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!
来自主题: AI资讯
6265 点击 2026-05-28 15:14
 搜索
搜索
刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!

每周25万亿tokens的真实流量、估值一年翻倍——OpenRouter拿下1.13亿美元B轮融资。
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。
“纯血Claude,一手号池,0.1倍率,注册就送5000万token”,最近半个月,类似的推广帖密集涌现在技术论坛乃至小红书、抖音、闲鱼里。AI中转站这门号称今年最赚钱的生意,开始引起大众注意。
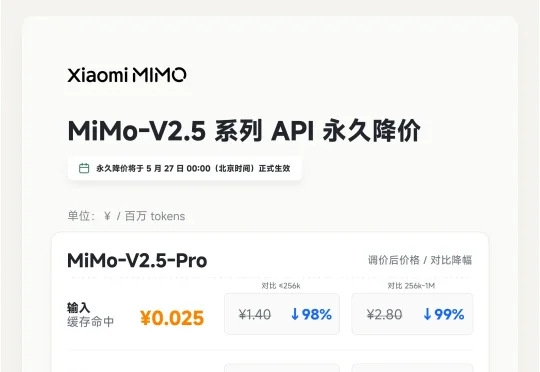
过往几个月,我们通过 MiMo Orbit、百万亿 Token 创造者激励计划等活动,让更多人有机会体验 MiMo ,并解决真实的问题——这是 MiMo 在规模化应用道路上的第一步。 而现在,随着底层

刚刚,蚂蚁集团旗下支付宝亮出AI支付“全家桶”:全球首个Token Pay服务、AI钱包产品,连同此前已落地的AI付与AI收,正式构成一套覆盖授权、支付、结算、管理、安全的全栈AI原生支付体系。

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )

4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。