不会封号的Claude Code使用方法!已稳定测试一个月,还能共享给团队。
不会封号的Claude Code使用方法!已稳定测试一个月,还能共享给团队。哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。
来自主题: AI技术研报
7646 点击 2026-01-14 10:03
 搜索
搜索
哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。
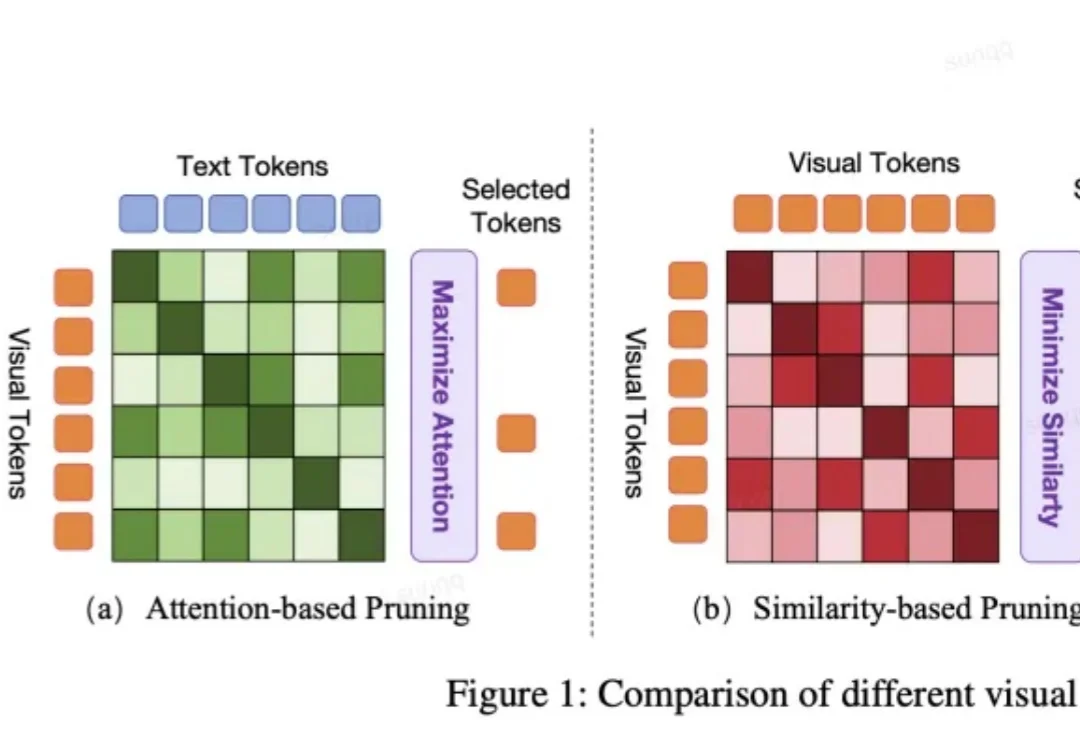
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
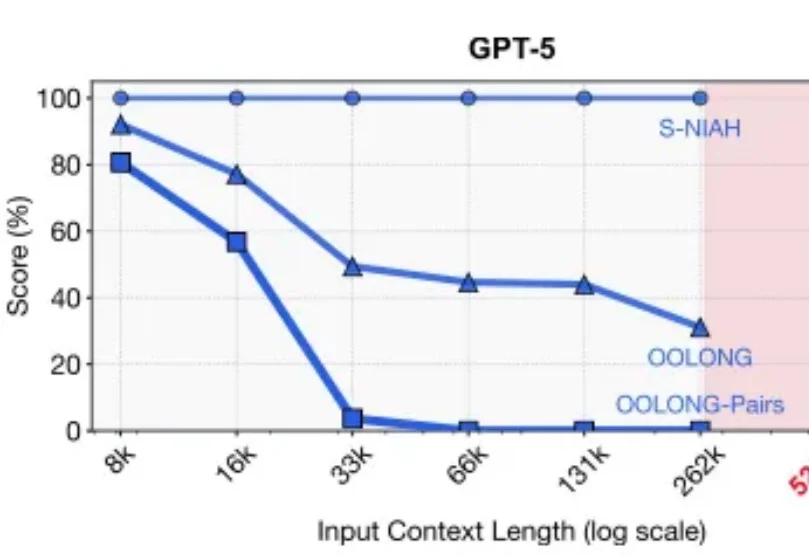
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。

随着大模型的发展,编程不再是一场苦修,而是一场大型即时策略游戏。在这个游戏里,很多人学会了与 AI 并肩作战,学会了用一种更纯粹、更直抵本质的方式去构建自己想要的世界。

最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,