
"Token工厂"硅基流动完成B轮20亿融资,创中国AI基础设施单轮融资记录
"Token工厂"硅基流动完成B轮20亿融资,创中国AI基础设施单轮融资记录AI公司还在拼模型,另一门更底层的生意正在变大。
来自主题: AI资讯
8807 点击 2026-06-16 14:39
 搜索
搜索
AI公司还在拼模型,另一门更底层的生意正在变大。
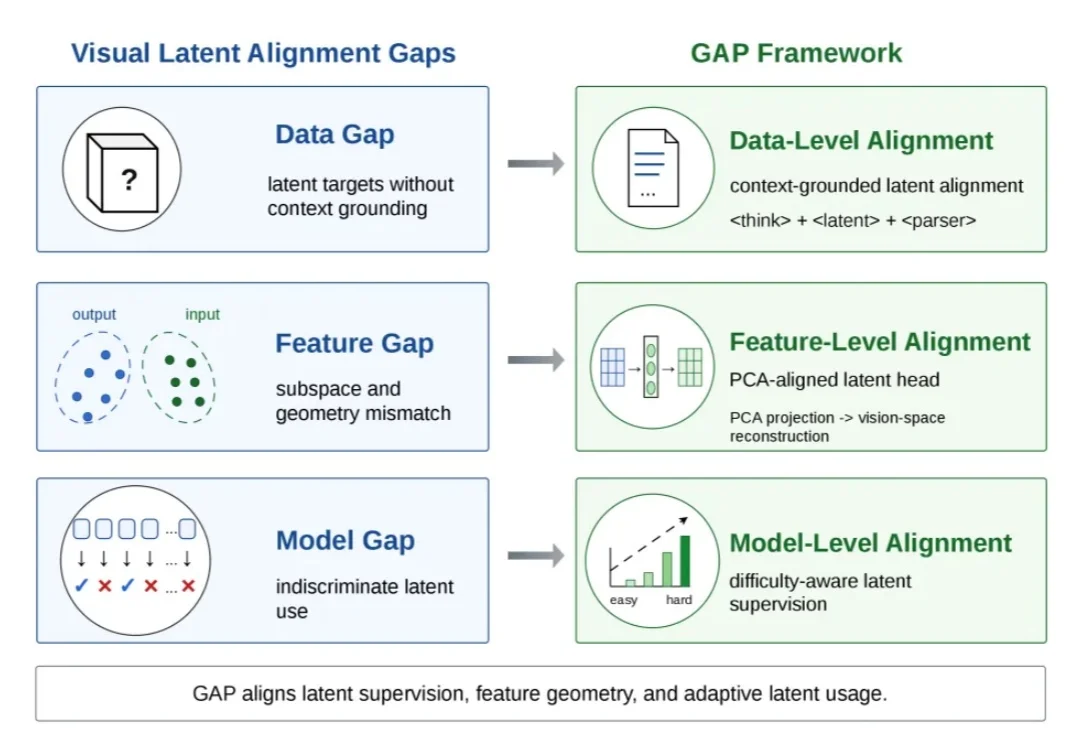
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。

新智元近日对话了清华大学教授沈阳。作为长期关注 AI 应用、智能体与产业实践的学者,同时也是 ZeeLin(智灵动力)首席科学家,他个人每天的Token消耗量近10亿,本次对话围绕「自进化AI的自我递归进化」这一主线展开,讨论 AI 自进化与科研、叙事、商业与AGI相关的十个话题。

昨天晚上,微软 CEO 萨蒂亚·纳德拉(Satya Nadella)在 𝕏 上发布了一篇长推文《A frontier without an ecosystem is not stable》,即「没有生态系统的前沿是不稳定的」。
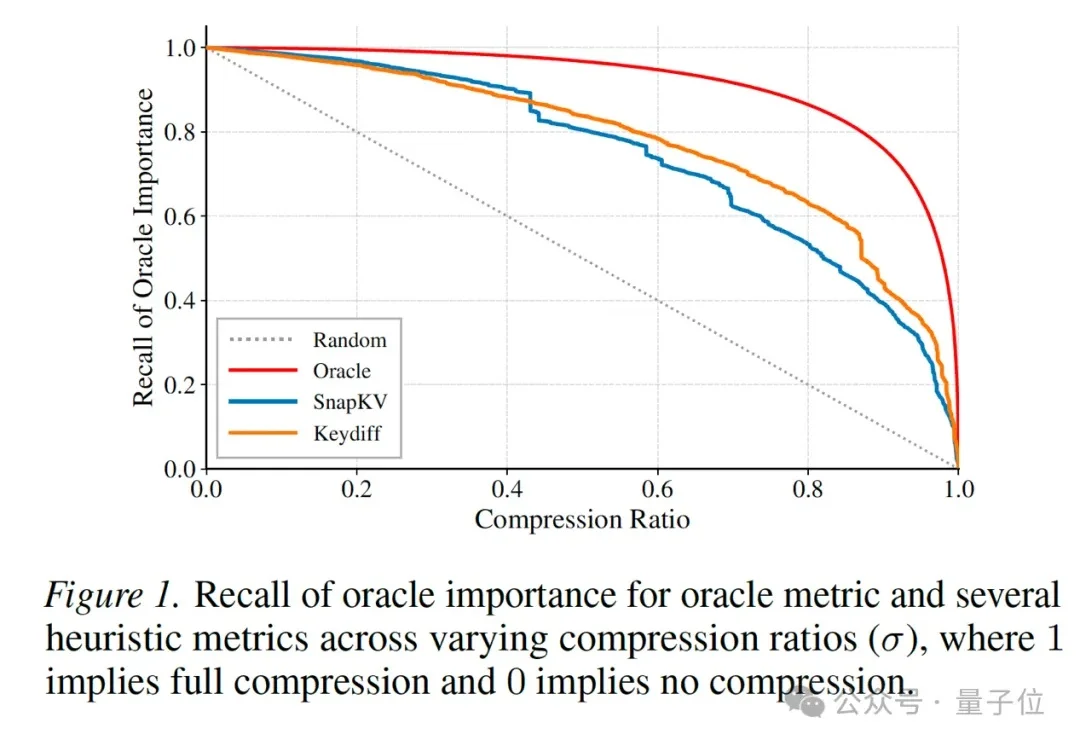
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。
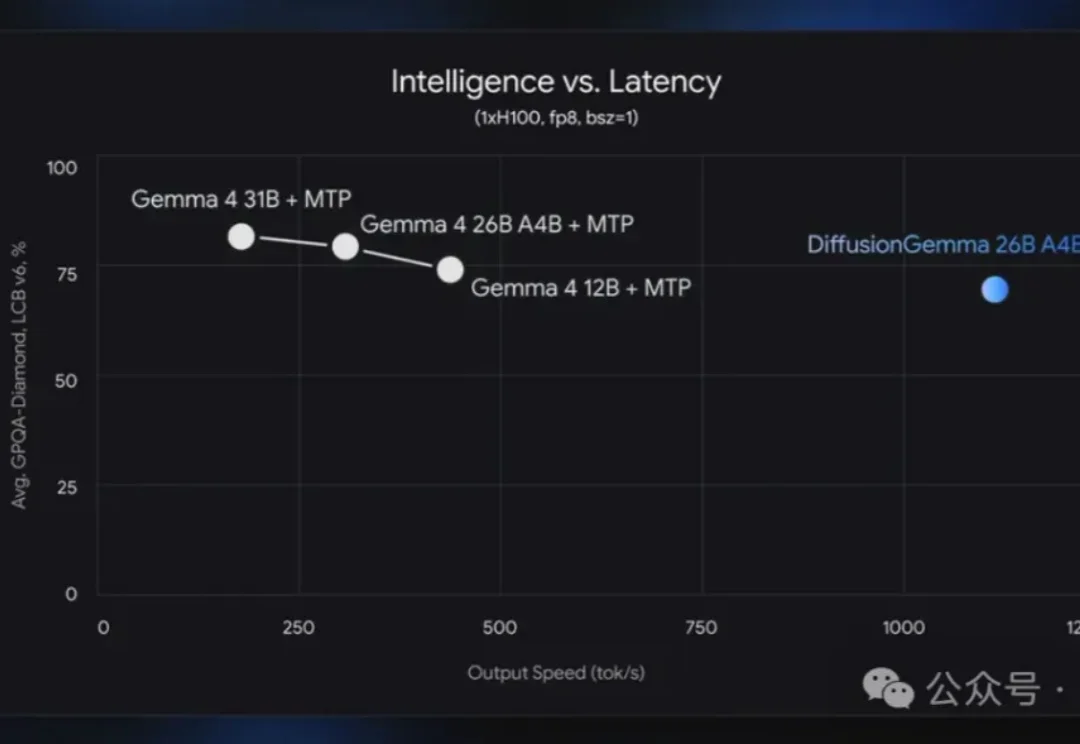
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
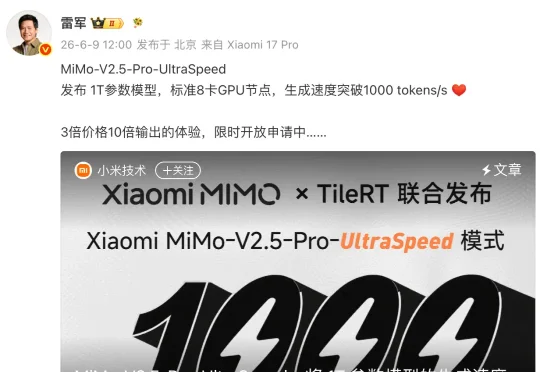
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。