
奥特曼认输:全球第一,根本不在OpenAI!
奥特曼认输:全球第一,根本不在OpenAI!奥特曼亲口承认,OpenAI内部token消费冠军月烧1000亿个,还不是全球第一。
来自主题: AI资讯
9213 点击 2026-06-09 14:30
 搜索
搜索
奥特曼亲口承认,OpenAI内部token消费冠军月烧1000亿个,还不是全球第一。

阿里巴巴今天宣布了围绕AI业务的一次重要组织升级调整: 宣布合并通义大模型事业部和未来生活实验室,成立Token Foundry事业部,由集团CEO吴泳铭直接负责。周靖人将担任阿里巴巴首席科学家,牵头成立阿里巴巴AI未来研究院,专注前沿AI科技的探索与突破。郑波带领Happy Horse、Happy Oyster等加入Token Foundry事业部。

最近,一个新词引发了广泛讨论:「Tokenpocalypse」(Token 末日)。

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。
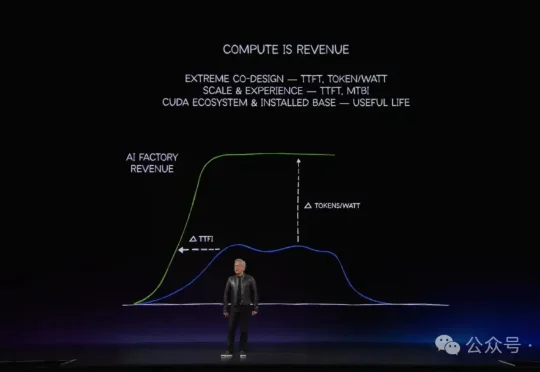
6月1日,在英伟达GTC舞台,黄仁勋聊AI工厂,聊智能体,反复念叨的也是这个Token:算力就是收入,算力就是利润。没有收入和利润,就是亏损。一座AI工厂这辈子能赚多少钱,看的就是它总共产出多少Token,也就是曲线下方的面积。一句话:谁能更快、更省电、更稳定地生产Token,谁就赚得多。
OpenSquilla 是一个开源 Agent Harness 框架(https://github.com/opensquilla/opensquilla)。它在 Agent 应用和模型之间加了一层运行中枢。OpenSquilla 由上海基元律动科技有限公司开发。基元律动成立仅几个月后,已完成首轮融资,估值高达1亿美元。
有人的Hermes像个聊天窗口,你喊一声它回一句,有人已经把Hermes用成了24小时不睡觉的AI助手,你不用说话,它自己就知道该干什么。这个人叫Sharbel,是海外视频平台YouTube大神,开源了一些Agent相关的项目。他在最新视频里公开了10个把Hermes从对话工具变成可用助手的操作,只要token充足,你的Hermes就可以7×24小时永不停转。
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”
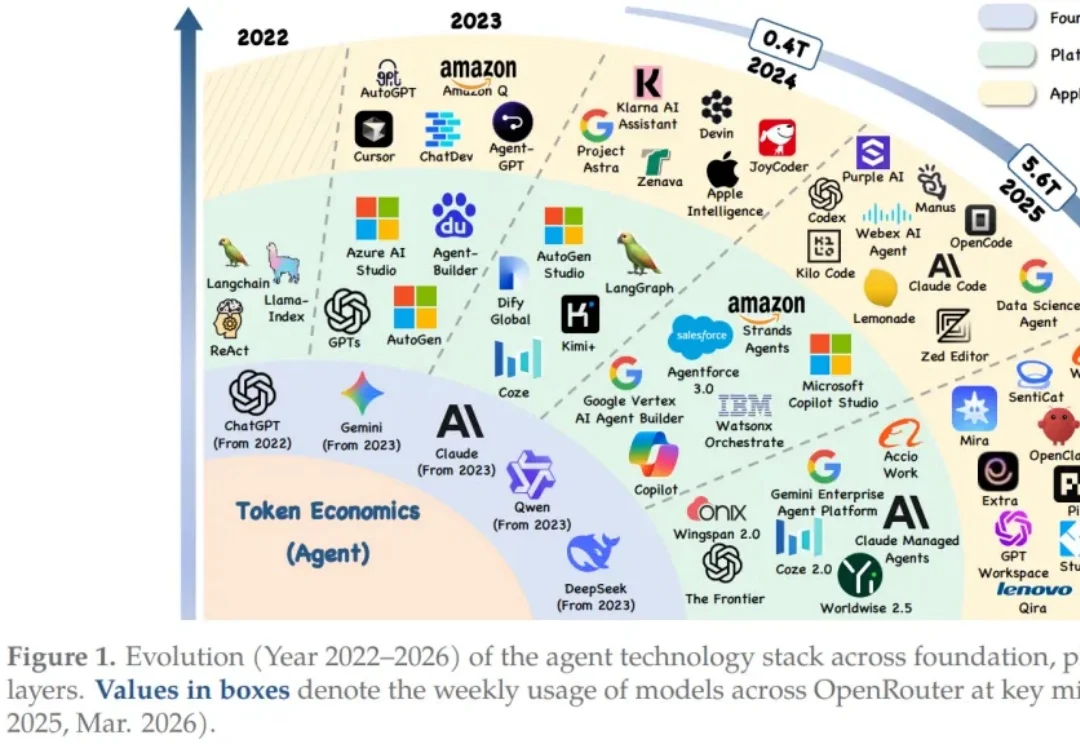
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

感觉大家对追新这事,没那么上头了。