
全球顶尖法律AI每月处理12万亿token,为什么不用OpenAI的云?
全球顶尖法律AI每月处理12万亿token,为什么不用OpenAI的云?Harvey 是全球最大的法律 AI 公司,客户是世界顶尖律所和企业法务团队。你可能没怎么听说过它,但在法律行业,它基本上是那个大家已经在用、不需要再讨论的选择——就像律师界的 Salesforce,你不会问"要不要用",只问"怎么接进来"。
来自主题: AI资讯
6813 点击 2026-06-03 14:31
 搜索
搜索
Harvey 是全球最大的法律 AI 公司,客户是世界顶尖律所和企业法务团队。你可能没怎么听说过它,但在法律行业,它基本上是那个大家已经在用、不需要再讨论的选择——就像律师界的 Salesforce,你不会问"要不要用",只问"怎么接进来"。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。

“AI新物种”企业级Token生产平台TokenBox™。

4个月烧光全年AI预算,天价Token正逼疯硅谷!最近,墨芯人工智能斩获近10亿融资,用「稀疏计算」强势破局,全新一代算力芯片年内发牌。

最近我发现一个很有意思的反转。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

让用户实现从「租赁智能」到「拥有智能」。

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。
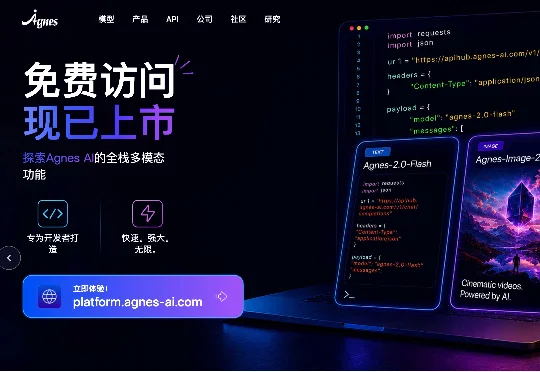
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。

4月,OpenAI Codex正式把计费口径从按消息估算转向按token用量;Anthropic侧的企业续约和新版模型tokenizer(分词器),也让 Claude Code的实际账单压力集中显现。明升与暗涨,两家各有各的玩法。