ICLR 2026 Oral | 大道至简!斯坦福、英伟达、新国立联合推出InfoTok,用信息论重新定义高效视频分词
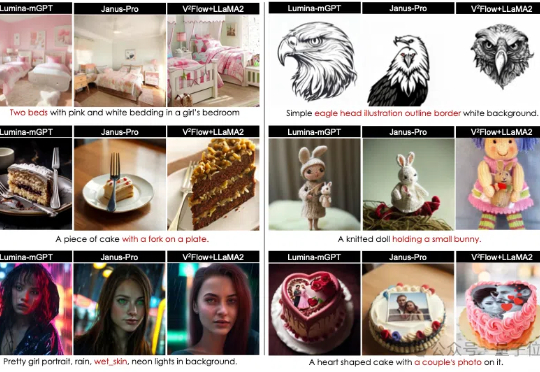
ICLR 2026 Oral | 大道至简!斯坦福、英伟达、新国立联合推出InfoTok,用信息论重新定义高效视频分词在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
来自主题: AI技术研报
5685 点击 2026-03-31 10:03