
B站下场自研AI配音!纯正美音版甄嬛传流出,再不用看小红书学英语了(Doge)
B站下场自研AI配音!纯正美音版甄嬛传流出,再不用看小红书学英语了(Doge)当甄嬛传、让子弹飞全都转英文,会怎样?
来自主题: AI技术研报
9711 点击 2025-07-15 12:32
当甄嬛传、让子弹飞全都转英文,会怎样?
最近一个「泄露」的文本转语音模型演示版本在 Reddit 上火了。这个「泄露」的演示视频被网友贴出来后,评论区一片惊呼。
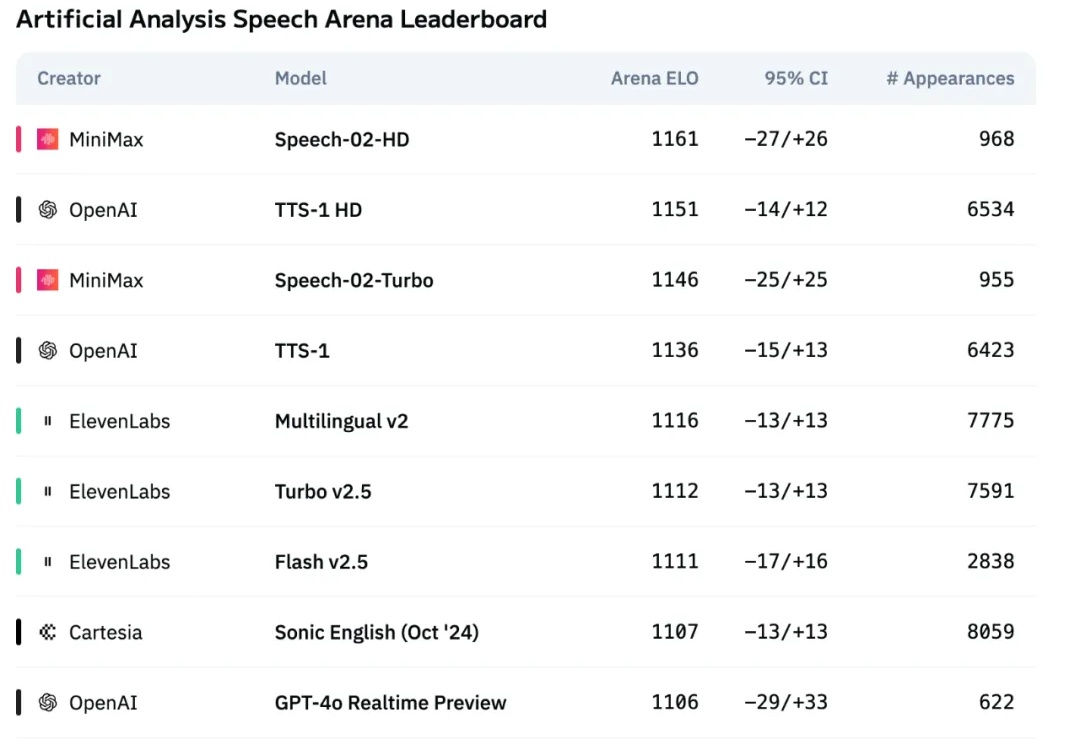
今天咱们再聊聊TTS(文本转语音)这个话题。4月份给大家分享了MiniMax的TTS平台:MiniMax Audio当时我直呼它是最强中文TTS,那篇反响还不错,主要他们Speech-02-HD的效果确实NB

播客、访谈、体育解说、新闻报道和电商直播中,语音对话已经无处不在。 当前的文本到语音(TTS)模型在单句或孤立段落的语音生成效果上取得了令人瞩目的进展,合成语音的自然度、清晰度和表现力都已显著提升,甚至接近真人水平。不过,由于缺乏整体的对话情境,这些 TTS 模型仍然无法合成高质量的对话语音。
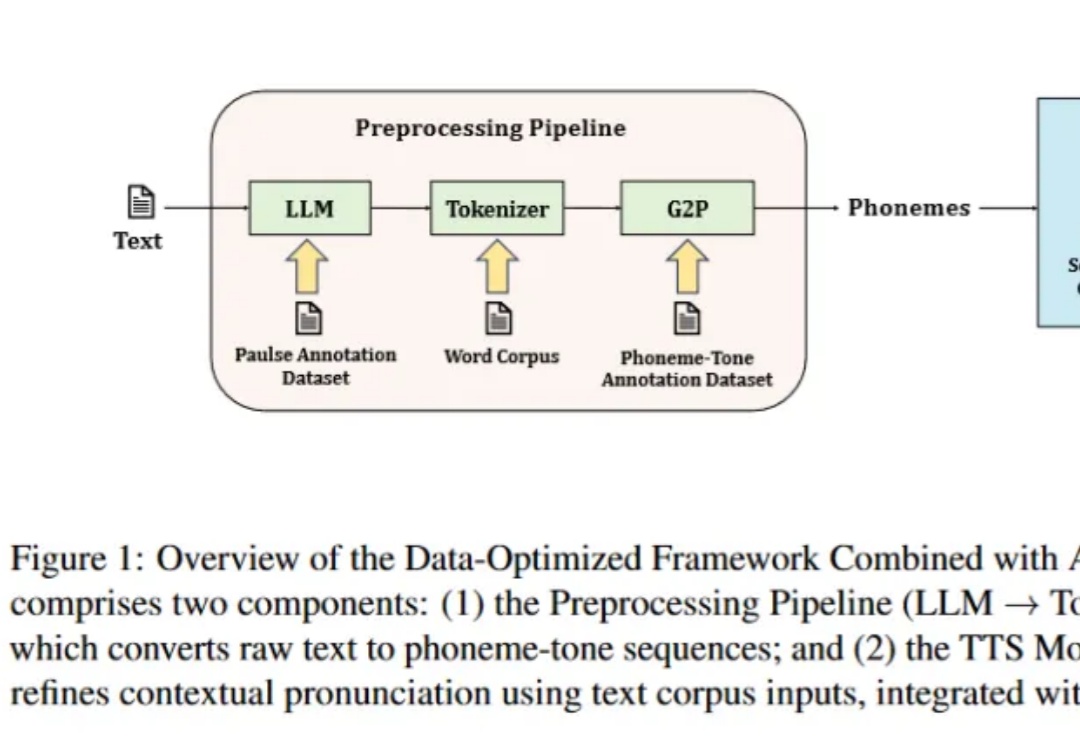
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。

六边形战士来了。

谷歌现象级产品NotebookLM,两个本科生自学3个月就复刻了?
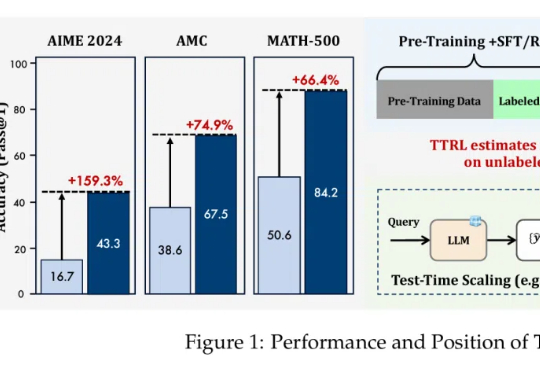
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
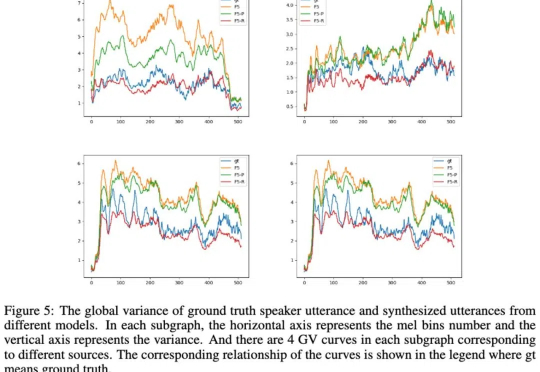
在人工智能技术日新月异的今天,语音合成(TTS)领域正经历着一场前所未有的技术革命。最新一代文本转语音系统不仅能够生成媲美真人音质的高保真语音,更实现了「只听一次」就能完美复刻目标音色的零样本克隆能力。