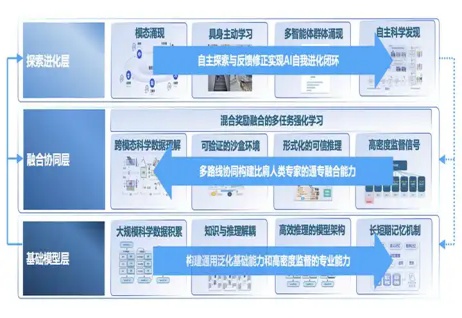
通专融合,思维链还透明,上海AI Lab为新一代大模型打了个样
通专融合,思维链还透明,上海AI Lab为新一代大模型打了个样OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
来自主题: AI技术研报
11505 点击 2025-05-24 15:33
 搜索
搜索
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
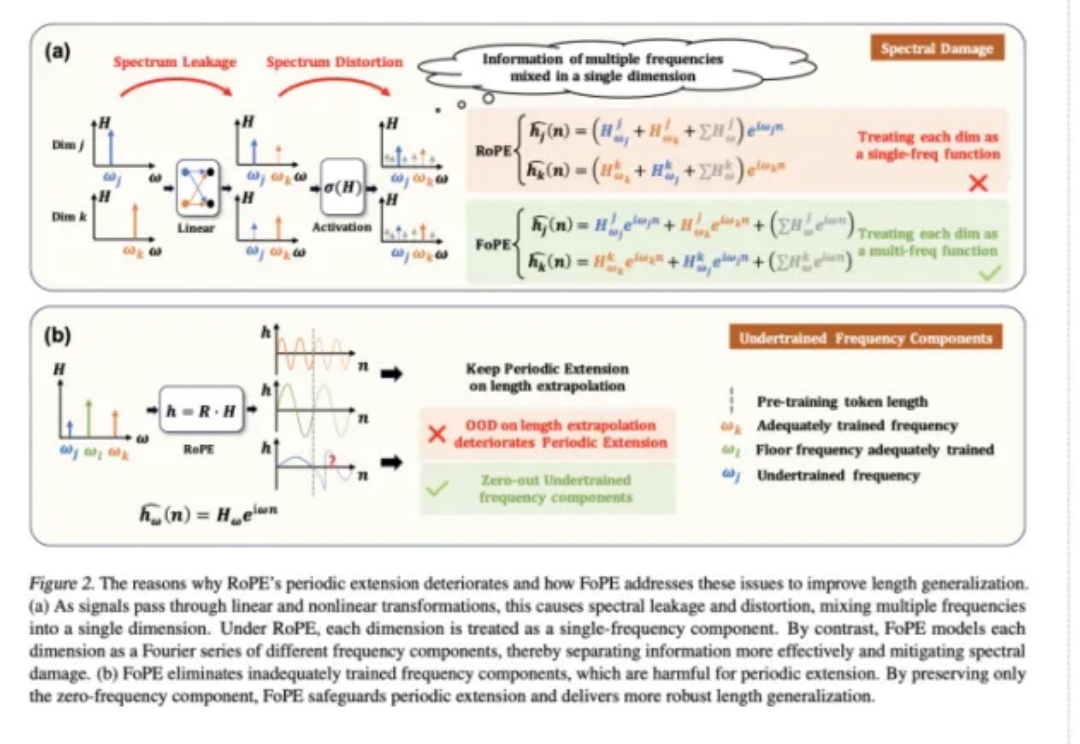
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
4月29日,习近平总书记在上海考察时,在中共中央政治局委员、上海市委书记陈吉宁和市长龚正陪同下,来到位于徐汇区的上海“模速空间”大模型创新生态社区调研。
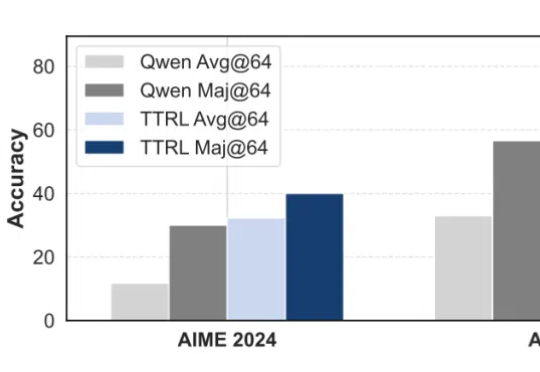
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
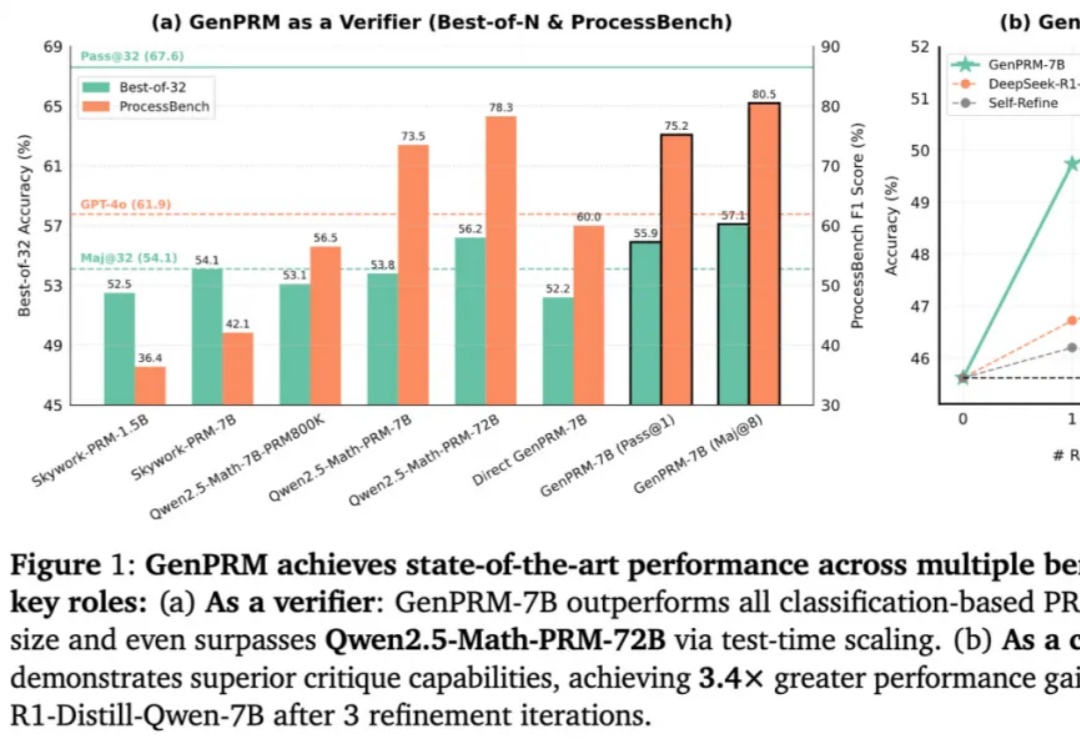
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

仅用4090就能实现大规模城市场景重建!
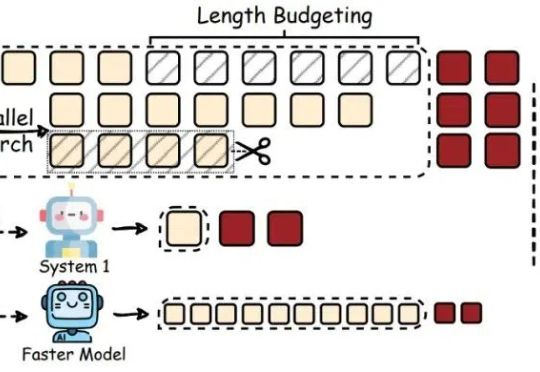
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。

近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。

低秩适配器(LoRA)能够在有监督微调中以约 5% 的可训练参数实现全参数微调 90% 性能。