深度|告别手工作坊,AI时代达人营销的底层逻辑彻底变了
深度|告别手工作坊,AI时代达人营销的底层逻辑彻底变了于是海量的AI需求密集冲向同一批达人。现实问题是,达人背后受众固定,而产品的受众却截然不同。当然,除非花大量时间看达人视频,再叠加点个人经验判断,否则你也无法知道,达人是真正懂技术的leader,还是只会蹭热点的营销号? 达人背后的粉丝是付费意愿极强的开发者,还是小白用户。
来自主题: AI资讯
9943 点击 2025-12-10 14:31
 搜索
搜索
于是海量的AI需求密集冲向同一批达人。现实问题是,达人背后受众固定,而产品的受众却截然不同。当然,除非花大量时间看达人视频,再叠加点个人经验判断,否则你也无法知道,达人是真正懂技术的leader,还是只会蹭热点的营销号? 达人背后的粉丝是付费意愿极强的开发者,还是小白用户。

Plan Coach 创始人苏晓江的故事,是一人公司最真切的写照。他曾是大厂的技术主管,但也会因「不想刷碗」而开始拖延。当 AI 将他的拖延症状拆解成「你只要站起来就算赢」时,他通过这个微小的洞察,用一天时间做成了一个抗拖延 APP 的原型。当他将这个不完美的「雏形」扔进社区,回应是山呼海啸般的热情,在贴文下,他获得了 26 万赞,和 1000 多条用户真实反馈。用户成为了他产品的「精神股东」。

上周,Sam Altman 罕见地按下了属于 OpenAI 的核按钮——「Code Red」(红色警报)。 这不仅仅是一个战术调整,更像是一场带着血腥味的「断臂求生」。Altman 的意思很明确:Sora?先停一停。那些酷炫但不赚钱的副业?全部靠边站。在未来八周内,全公司必须死磕一件事——让 ChatGPT 重新变得不可替代。

尬住了!微软AI市场遇冷,老用户都不买账……
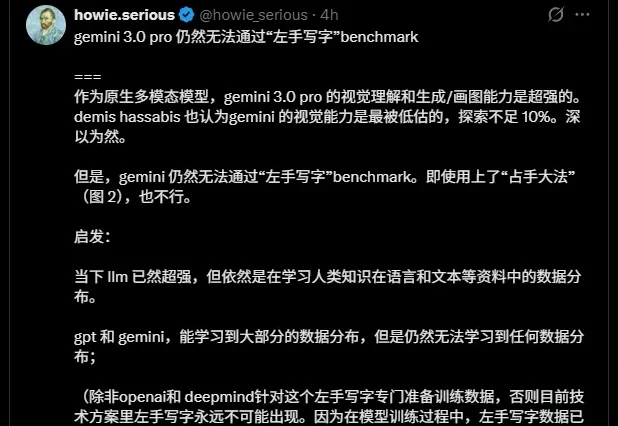
昨天刷到了一条非常有意思的推特。
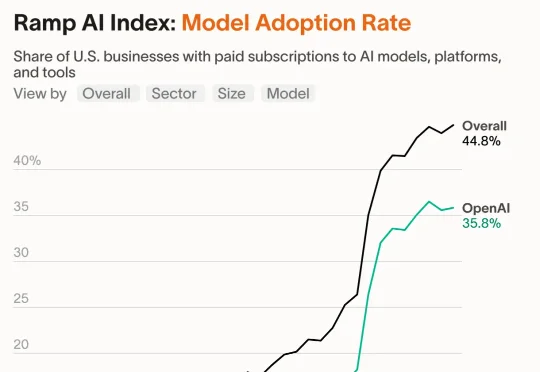
当你还在纠结要不要用一下AI时,OpenAI已经拎着8亿人的加班数据,在被谷歌和Anthropic逼到墙角的企业战场上拼命自救——到底是谁在每天白赚1小时,谁又在被时代悄悄淘汰?
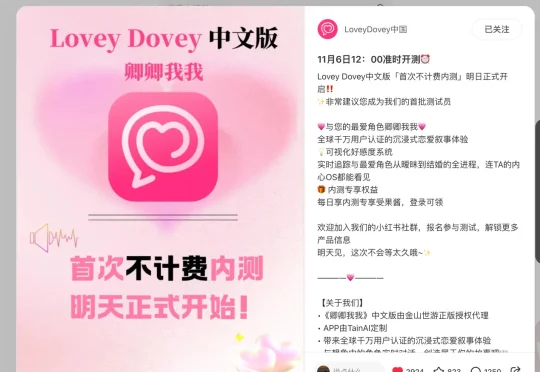
在 11 月 6 日,「LoveyDovey」宣布开启中文版本“不计费内测”,在小红书获得了超过千条积极反馈。而同样是在 11 月,小冰旗下「X Eva」、美团旗下「Wow」两款 AI 社交应用相继传出停服消息。两相对照,行业所处的分化阶段清晰可见,有的产品挣扎退场,有的产品却在全球范围继续扩张。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”

Canvas-to-Image 是一个面向组合式图像创作的全新框架。它取消了传统「分散控制」的流程,将身份参考图、空间布局、姿态线稿等不同类型的控制信息全部整合在同一个画布中。用户在画布上放置或绘制的内容,会被模型直接解释为生成指令,简化了图像生成过程中的控制流程。
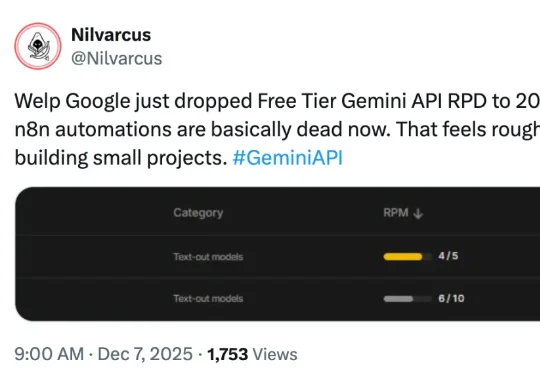
“谷歌刚把免费版 Gemini API 的每日请求次数从 250 降到了 20,我的 n8n 自动化脚本现在基本都用不了了。这对任何开发小型项目的人来说都是个打击。”网友 Nilvarcus 表示。近日,有网友曝出 Google 收紧了 Gemini API 免费层级的限制:Pro 系列已经取消,Flash 系列每天仅 20 次。这对开发者来说远远不够用。