

刚刚!华为首个开源大模型来了
刚刚!华为首个开源大模型来了刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。
来自主题: AI资讯
10780 点击 2025-06-30 09:19
刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
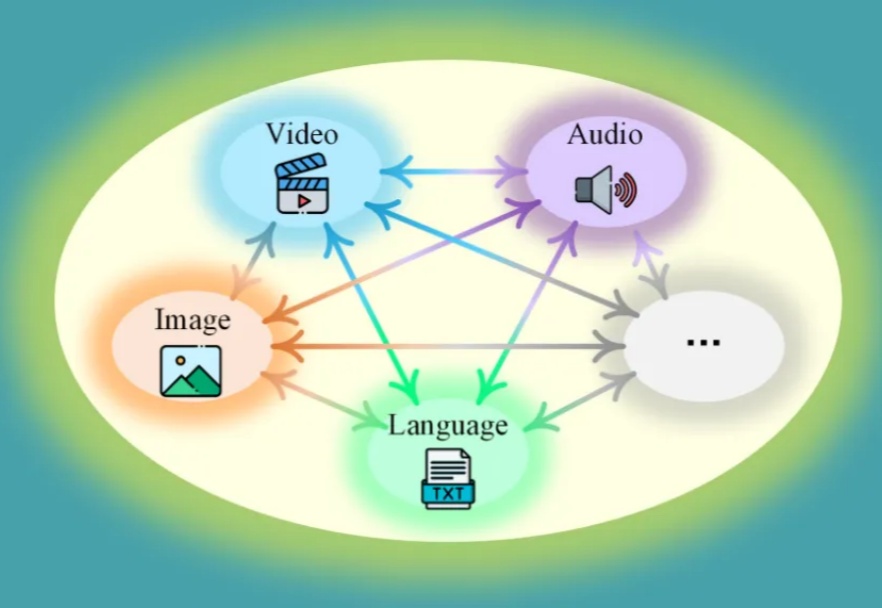
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
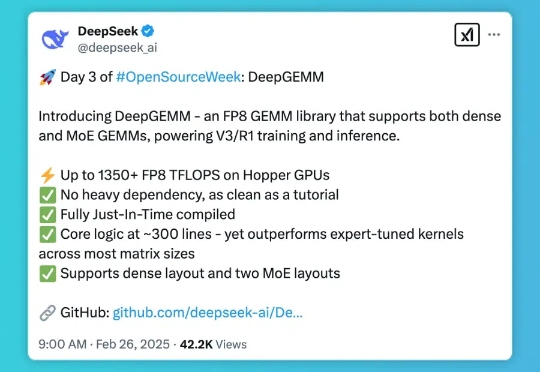
DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。

DeepSeek 本周正在连续 5 天发布开源项目,今天是第 2 天,带来了专为混合专家模型(MoE)和专家并行(EP)打造的高效通信库 — DeepEP。就在半小时前,官方对此进行了发布,以下是由赛博禅心带来的详解。
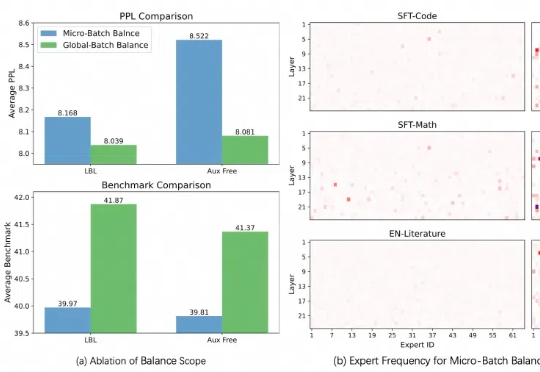
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。
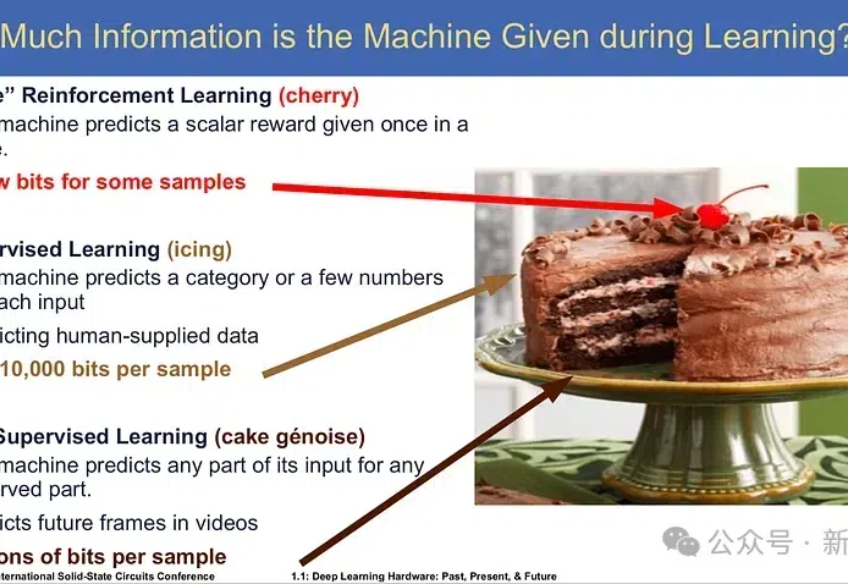
只需几十个样本即可训练专家模型,强化微调RLF能掀起强化学习热潮吗?具体技术实现尚不清楚,AI2此前开源的RLVR或许在技术思路上存在相似之处。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。

强化微调可以轻松创建具备强大推理能力的专家模型。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。