
vercel-labs/skills 狂揽2.4万星标:一行命令,AI会自己找技能了
vercel-labs/skills 狂揽2.4万星标:一行命令,AI会自己找技能了这个官方仓库vercel-labs/skills,发布仅五个月,GitHub星标就冲到了2.4万。凭什么这么火?简单到只有一行命令:npx skills add <package>。说白了,它就是AI智能体(AI agent)的包管理器。
来自主题: AI资讯
10051 点击 2026-07-06 10:41
 搜索
搜索
这个官方仓库vercel-labs/skills,发布仅五个月,GitHub星标就冲到了2.4万。凭什么这么火?简单到只有一行命令:npx skills add <package>。说白了,它就是AI智能体(AI agent)的包管理器。
这个周末,可能是我最戏剧性的周末了。 周五发完Claude Fable 5的文章之后,看的人还是蛮多的,大家反馈也都不错。但是呢,我也不知道触动了谁,也有可能是某些大佬,可能想让我长长教训,或者想让我知道,Vibe Coding的网站就是狗屎,是有无数的安全隐患的。

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。

2026年6月,硅谷。Anthropic的年化营收在过去12个月里翻了五倍多,达到470亿美元。四大科技巨头今年的AI资本开支指引合计超过7000亿美元,接近全球电信行业总投入的两倍。

我老把一句话挂在嘴边:小而 AI 的团队,会把又大又慢的团队干掉。可这话说久了,自己都觉得像句口号。直到我读到这篇——而且它偏偏来自律师业,那个最讲资历、最堆人头、最保守的行业。作者 Zack Shapiro,前 Davis Polk 律师、耶鲁法学院出身。他讲了一个晚上。

数据中心新秀 Crusoe 与 Meta 和 Oracle 等公司签有为其提供人工智能计算能力的合同,据知情人士称,Crusoe 正就一轮约 30 亿美元的融资进行谈判,此次融资可能使公司的估值翻三倍。
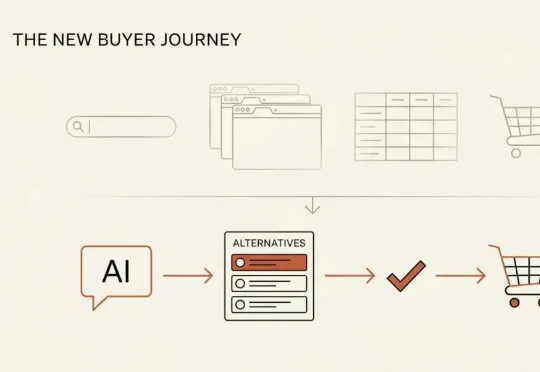
以前:搜 Google → 开 8 个标签页 → 对比功能 → 约演示 → 买。现在:搜那个默认大牌 → 再搜「某某大牌 的替代品」→ 从冒出来的 3 个名字里挑一个 → 约演示 → 买。整条对比研究,被 AI 一次答复压缩成了「三选一」

北大团队雪梦未来(SnowOrigin)获龚虹嘉、陆奇及海外机构投资。公司以神经腕带、全景头环等可穿戴设备为入口,结合自研NMH(Neural Math Hybrid)AI 解码模型,试图将人类真实操作过程中的意图、姿态、发力趋势、微控制及环境上下文,转化为可用于机器人、世界模型和具身智能训练的结构化数据。

ElevenLabs 已与投资者就让员工在二级市场出售股份进行早期洽谈,据知情人士称,这项要约将把这家人工智能初创公司的估值定在约 220 亿美元。两位知情人士补充说,这次要约收购可能会在二月一轮融资后将公司的估值翻一番,预计将在九月之前进行。知情人士表示,这些谈判仍处于早期阶段,且可能会发生变化;他们要求在讨论私人信息时不被点名。
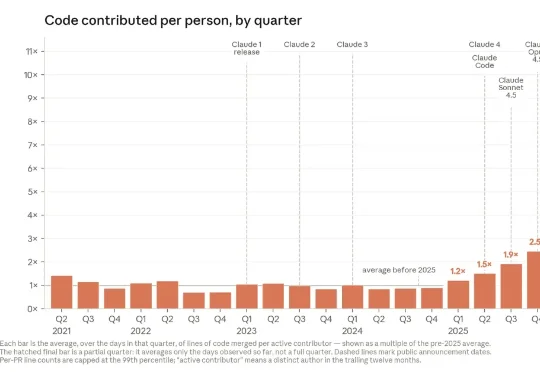
Anthropic 工程师人均每个季度产出的代码量,是 2025 年同期的 8 倍。这可不是某个孤立团队的战绩,而是一整条从「稳定」直接拉升到「起飞」的曲线:过去几年几乎持平的产出量,在过去一年里近乎垂直上升。