OpenAI塌房!Scaling law原作曝bug,万亿算力全白烧
OpenAI塌房!Scaling law原作曝bug,万亿算力全白烧OpenAI误导了整个AI圈好几年!过去五年,整个AI行业都被Scaling Law推着往前冲。现在,有人站出来说:这条曲线,一开始就错了。刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。
来自主题: AI资讯
9414 点击 2026-07-05 14:04
 搜索
搜索
OpenAI误导了整个AI圈好几年!过去五年,整个AI行业都被Scaling Law推着往前冲。现在,有人站出来说:这条曲线,一开始就错了。刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。
就我们所知,顾煜贤已经正式加入了 DeepSeek。顾煜贤还曾获得 2025 年度苹果博士奖学金以及蚂蚁 In-Tech 奖学金。个人主页显示,顾煜贤在清华大学交互式人工智能课题组(Conversational AI, CoAI)学习,师从黄民烈教授。

前些天,Gemini 核心贡献者、Blueshift 团队负责人 Adam Brown 近日在圆周理论物理研究所的长篇演讲《训练沙子思考:通用人工智能与物理学的未来》吸引了广泛关注。在该演讲中,他讲述自己如何亲眼看着 AI 从「幼儿园水平」一路狂奔到博士水平,并由此推演:如果趋势延续,物理学会变成什么。

硅谷创投哲学家纳瓦尔·拉维坎特(Naval Ravikant)有一个著名的论断,令人印象深刻:“在一个拥有无限杠杆的世界里,判断力是最重要的技能。”我们一直以来对AI的忧虑——失业、偏见、安全……,或许都只是冰山浮出水面的部分。海面之下,一个更巨大、更隐蔽的变革正在发生。

近日,上海AI Lab等团队提出了一种面向专业软件智能体的新范式——ComAct(COM-as-Action)。它的核心思想在于:不再把鼠标点击和键盘输入作为Agent的action,而是让Agent直接生成COM代码,通过软件底层对象模型操纵真实专业软件。
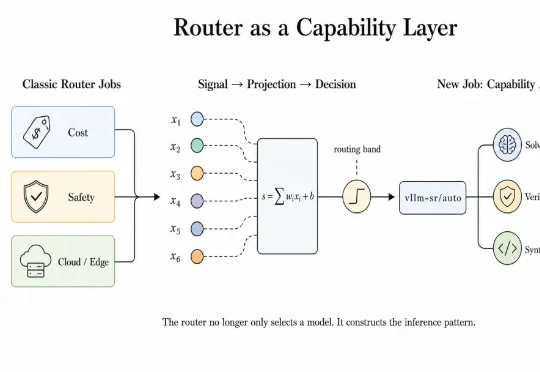
vLLM 社区推出的 Semantic Router 除了专注上面三个方向,正在更进一步:我们认为:router 不只是选择模型,还可以提升模型能力。用户不用改权重,也不用让每个 Agent 团队都自己搭一套 Graph,而是在一次普通 Model API 调用的内部,组织出一支有边界、有预算、有验证、有回退的 “小队”。

今天来好好盘点 2026 年上半年的图片与视频模型,伴随模型更新时间轴出现的,还有我一些当时的测试文章。也算是对不怎么努力也没什么收获的上半年做个总结汇报了。
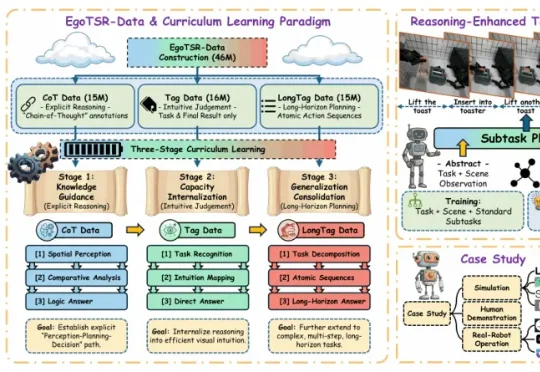
浙江大学等五所高校的研究团队提出 EgoTSR。研究从第一人称机器人视角出发,希望让 VLM 学会判断任务状态,并把这种能力进一步扩展到长程规划。团队构建了包含 4600 万条样本的 EgoTSR-Data,并设计了三阶段课程学习流程。

2026 年,风向掉头了。几个最受关注的年轻 AI 人才,开始走进大厂。罗福莉,四川宜宾乡村出身,北大硕士,DeepSeek-V2 作者之一。被雷军点名后,“天才少女”四个字在热搜上挂了很久。她去了小米,负责大模型 MiMo。
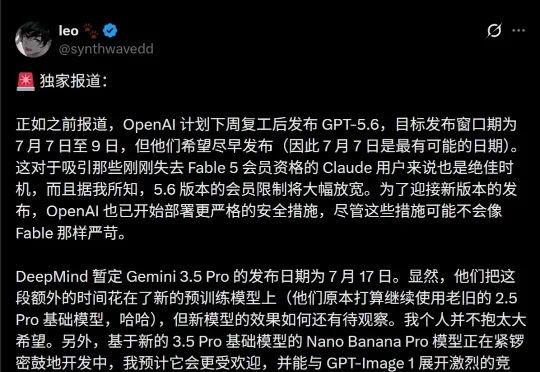
就在昨天,网友们激动发现:Codex应用的底层代码中惊现GPT-5.6 Sol、Terra和Luna三大子模型标识。更令人期待的是,一个全新的「速度拨盘」功能也出现在代码中。根据爆料,OpenAI已经在内部定下了死命令:GPT-5.6发布的目标窗口直指下周二(7月7日)至7月9日。