AI视频剪辑项目 OpenMontage 持续霸榜Github
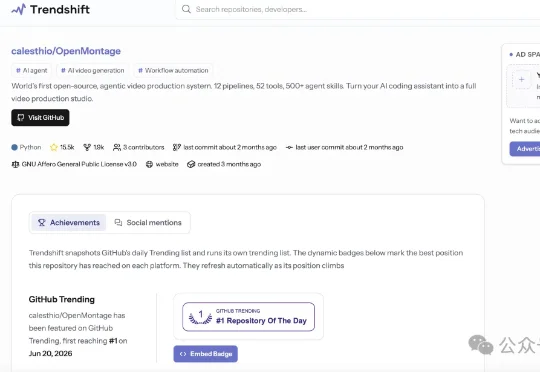
AI视频剪辑项目 OpenMontage 持续霸榜GithubGithub热榜持续屠榜,短短几天一路狂揽15.4k stars,甚至一度冲到了Top 1的位置。不是啥大厂项目,也不是啥新模型。而是一个叫OpenMontage的开源「视频制作」系统~(剪辑人狂喜.jpg)
来自主题: AI资讯
8903 点击 2026-07-04 14:13
 搜索
搜索
Github热榜持续屠榜,短短几天一路狂揽15.4k stars,甚至一度冲到了Top 1的位置。不是啥大厂项目,也不是啥新模型。而是一个叫OpenMontage的开源「视频制作」系统~(剪辑人狂喜.jpg)
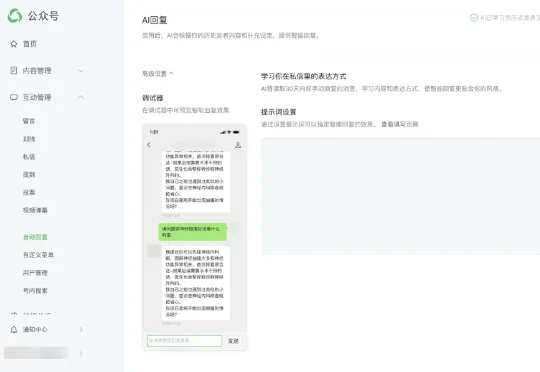
医院公众号粉丝动辄百万级,每天涌入的咨询消息600+条起步,其中大约70%是同一类问题——挂号流程、科室位置、门诊时间、报告查询……人工客服一旦下班,患者就容易被晾着。现在,微信公众号向医院开放AI分身能力,AI分身可以7×24小时在线,秒回患者问题,公众号后台一键就能开通。

独家获悉,一支北大出身、手握国际顶级超算成果的核心技术团队已完成市场化主体搭建,正式布局物理AI底层基础设施赛道。团队由北京大学杨超教授领衔,杨超是我国首位 ACM 戈登贝尔奖得主,2016 年带领团队拿下该国际超算最高荣誉,实现了我国在该奖项上零的突破;其本人也获评首届王选杰出青年学者奖,在高性能计算、数值仿真、人工智能等领域长期深耕。
Pinecone宣布 旗下 Nexus 知识引擎将与 Microsoft OneLake 实现新的集成,从根本上改变企业 AI 智能体访问和推理企业数据的方式。这项集成在 Microsoft Build 2026 大会上正式发布,允许 AI 智能体通过预构建的结构化知识工件(非传统的检索管道)查询存储在 OneLake 中的企业信息。

「不如直接数字人」 私以为,世界模型这个概念的发展经过了三个非常幽默的阶段。 第一阶段:硅谷真懂行的老登如杨立昆、李飞飞,觉得大语言模型在讲故事上没啥空间了,所以从学术圈拽了个新概念过来尝试弯道超车。
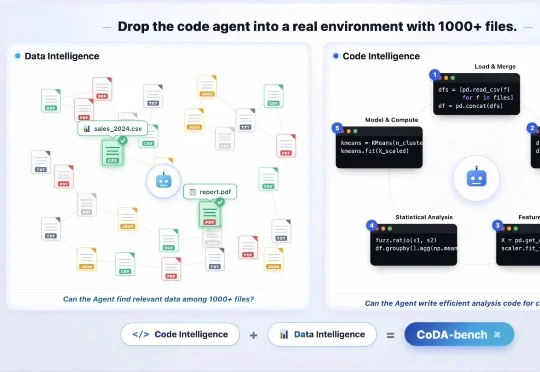
中国人民大学的研究团队提出 CoDA-Bench,联合评估 Agent 的 Code Intelligence + Data Intelligence。该基准首次把 Code Agent 放进包含 1000 + 数据文件的复杂环境下,要求模型先自主探索文件系统、找到相关数据,再编写代码完成分析。实验显示,即使当前表现最好的系统,在 CoDA-Bench 上执行准确率也只有 61.1%;

LinStereo 对应地做了三件事:PALA 换掉 ConvGRU 解决传播问题,HSCV 保留多尺度特征,DPI 用单目深度给一个靠谱的起点。PALA 做的事情说起来很直观,就是把 ConvGRU 的局部更新换成全局注意力,让每个像素每次迭代都能看到整张图。难点在于 softmax attention 是 O (N²) 的,直接用在高分辨率视差图上跑不动。
史上最严厉的一次清洗来了。就在昨天,外媒Financial Times突然曝出消息:Anthropic正在全面下狠手,疯狂清剿允许绕过限制访问Claude的所有地下通道!

刚刚,The Information爆出:Anthropic已启动自研AI芯片的早期工作,并与三星电子讨论潜在的代工合作。据知情人士称,考虑中的选项包括三星的2nm制程和先进封装。

华大智造子公司涌生智能×上海人工智能实验室,联合发布两项新成果:ProtoPilot:一款由真实实验室场景驱动的自进化多智能体系统;BioLab Bench:生命科学领域首个从用户需求到设备可执行的全流程Agent评测体系。