探访北京探月学校:AI时代“超级高中生” 、大学外的第三种可能与中国创新教育
探访北京探月学校:AI时代“超级高中生” 、大学外的第三种可能与中国创新教育这几天,全国高考成绩陆续放榜。1290万考生查到了自己的分数,无数家庭的目光,再次聚焦在一张分数条、一道分数线上——在大多数人的认知里,这仍是通往未来最重要、甚至唯一的那条路。
来自主题: AI资讯
6894 点击 2026-07-01 15:42
 搜索
搜索
这几天,全国高考成绩陆续放榜。1290万考生查到了自己的分数,无数家庭的目光,再次聚焦在一张分数条、一道分数线上——在大多数人的认知里,这仍是通往未来最重要、甚至唯一的那条路。
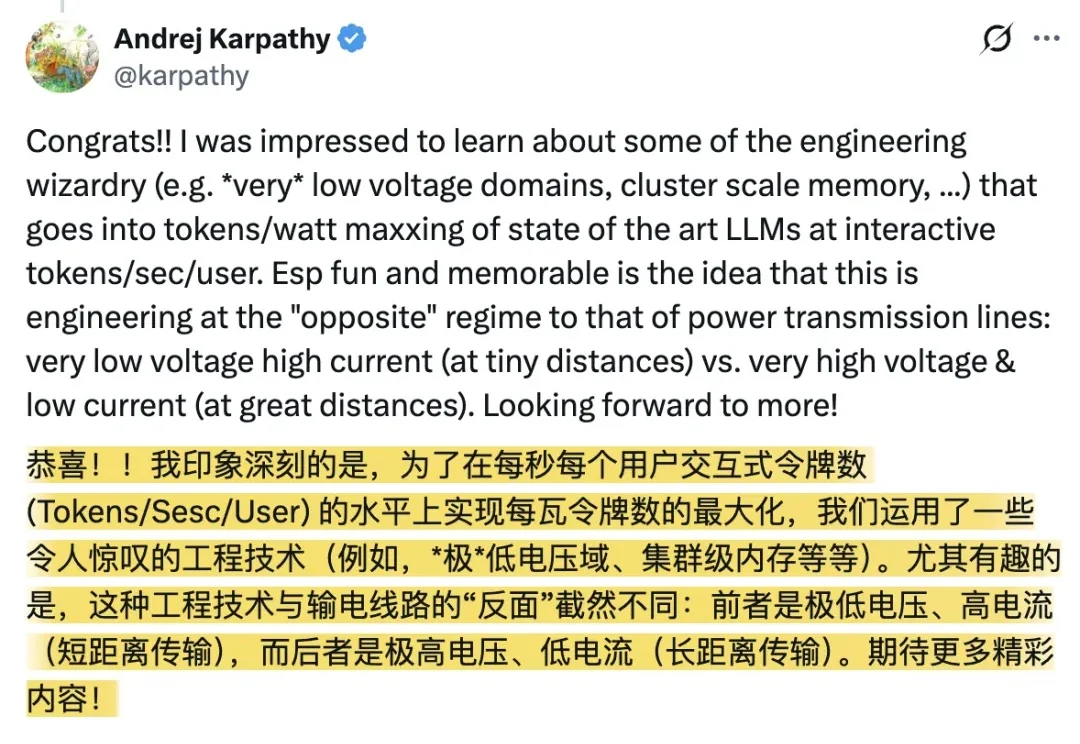
一家只做Transformer专用芯片的创业公司成功流片,连带官宣了一串大进展: 不仅筹集到了8亿美元的资金,还喜滋滋获得了10亿美元的客户大单。
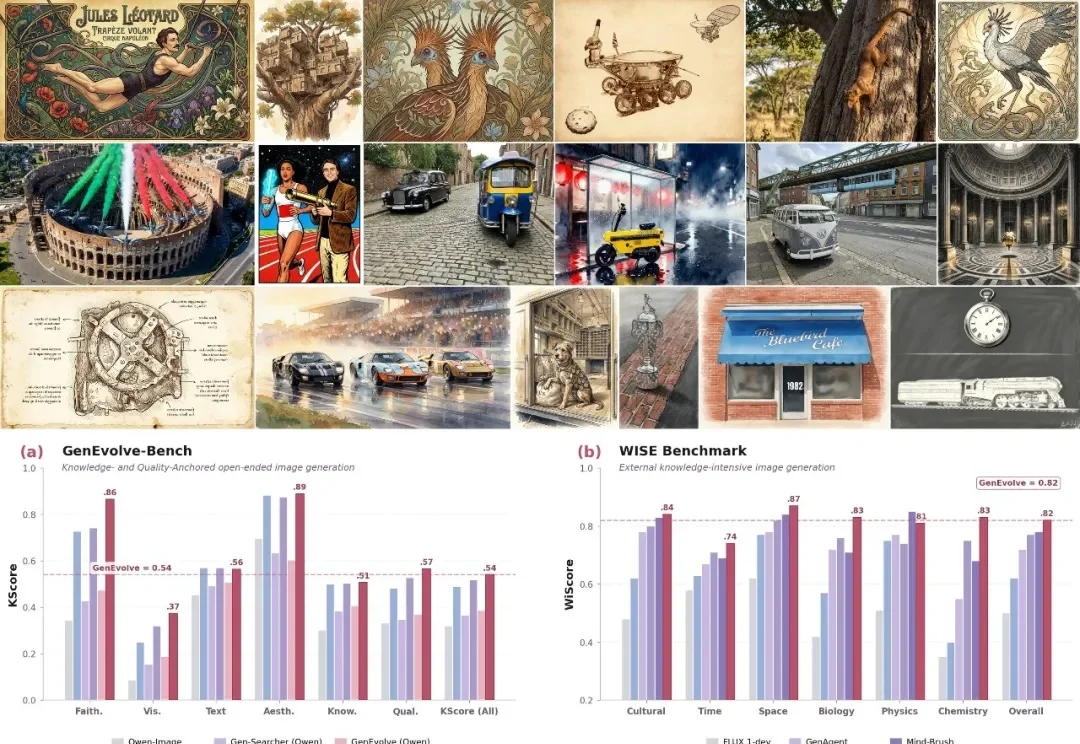
图像生成正在从「一句话生成一张图」,走向更接近真实创作流程的开放任务。
Vibe Coding 最经典的一张照片,大概就是走到哪里都要带着自己的电脑。

先说个数字:2026 年第二季度,通过 Stripe Atlas 注册的美国 C corp 里,63% 是一个人创办的。历史新高。

200 亿元估值已经成了头部具身智能公司的新标杆。

6月30号,《科创板日报》独家报了个消息:Kimi上一轮融资刚交割完,新一轮已经启动了。上一轮投后估值200亿美元,新一轮投前315亿美元。今天的中国一级市场,已经默认了一件事,Kimi应该继续融资,OpenAI和Anthropic也应该继续融资。

三位哈佛辍学生创办。
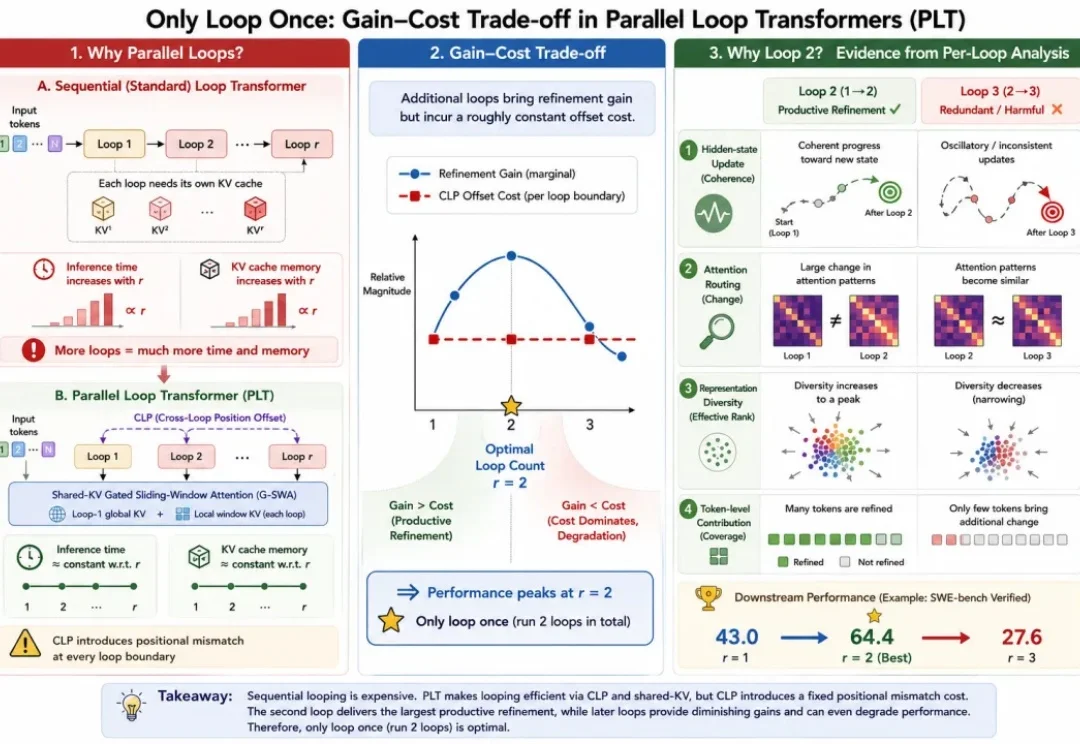
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

“浪已经来了,能做的就是尽量游在前面。”