
特斯拉OpenAI数据路线遇挫!8千平具身「兵工厂」+ego众包狂飙
特斯拉OpenAI数据路线遇挫!8千平具身「兵工厂」+ego众包狂飙质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。
来自主题: AI技术研报
10687 点击 2026-04-16 16:25
 搜索
搜索
质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。

前华为自动驾驶CTO、天才少年创办。

GTC 大会上人人都在谈 Agent 和具身智能,但真正让我理解 AI 如何进入物理世界的,是在一台极氪 9X 里发生的两场对话。

4月11日晚,常州奥体中心,苏超开幕式。雨一直下。

近日,北京德塔源创智能科技有限公司(简称:德塔智能 Delta Intelligence)宣布完成三轮超亿元融资,由高瓴创投等加注,并引入乐聚、智元、星海图等头部主机厂商战略入局。
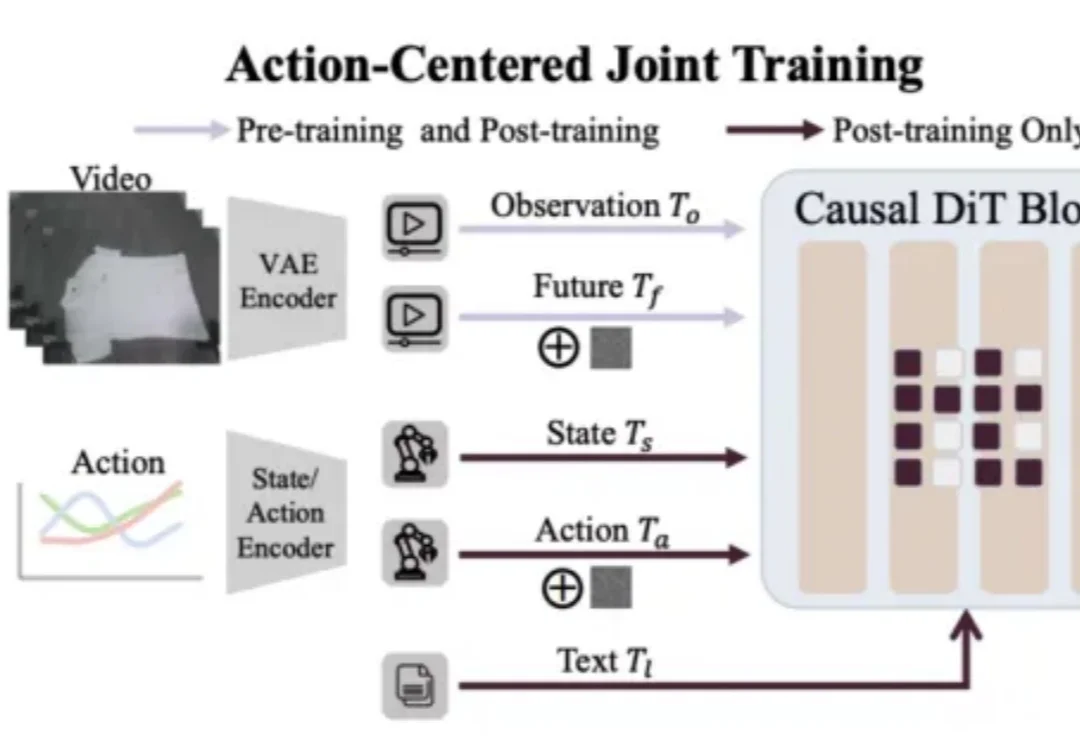
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。

未来我们到底需要什么样的家庭服务机器人,这家公司给了些许答案

4 月 14 日,智在无界发布第三代旗舰模型 Being-H0.7,该模型将数据规模扩展至 20 万小时人类视频,并提出一种全新的范式 —— 基于潜空间推理的世界模型。在 6 项国际性权威评测中,H0.7 综合排名全球第一(其中 4 项登顶),同时也是首个覆盖跨本体、跨场景、连续动态、流体、柔性物体、物理规律与上下文推理等七大关键维度的通用世界模型。
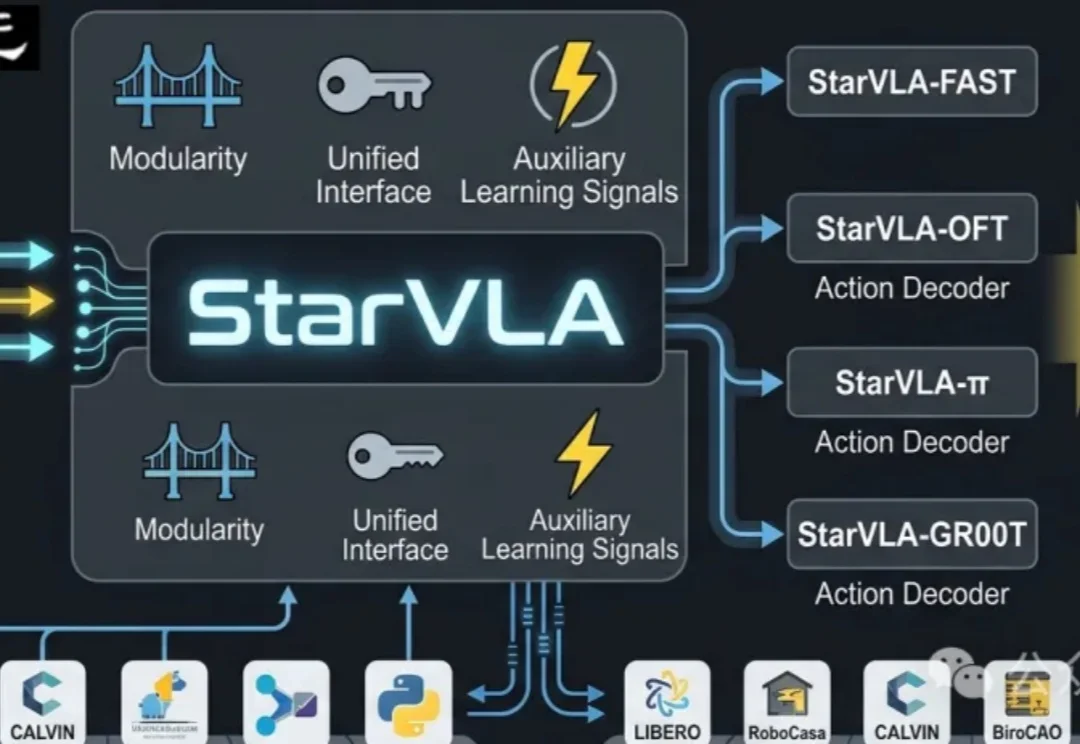
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
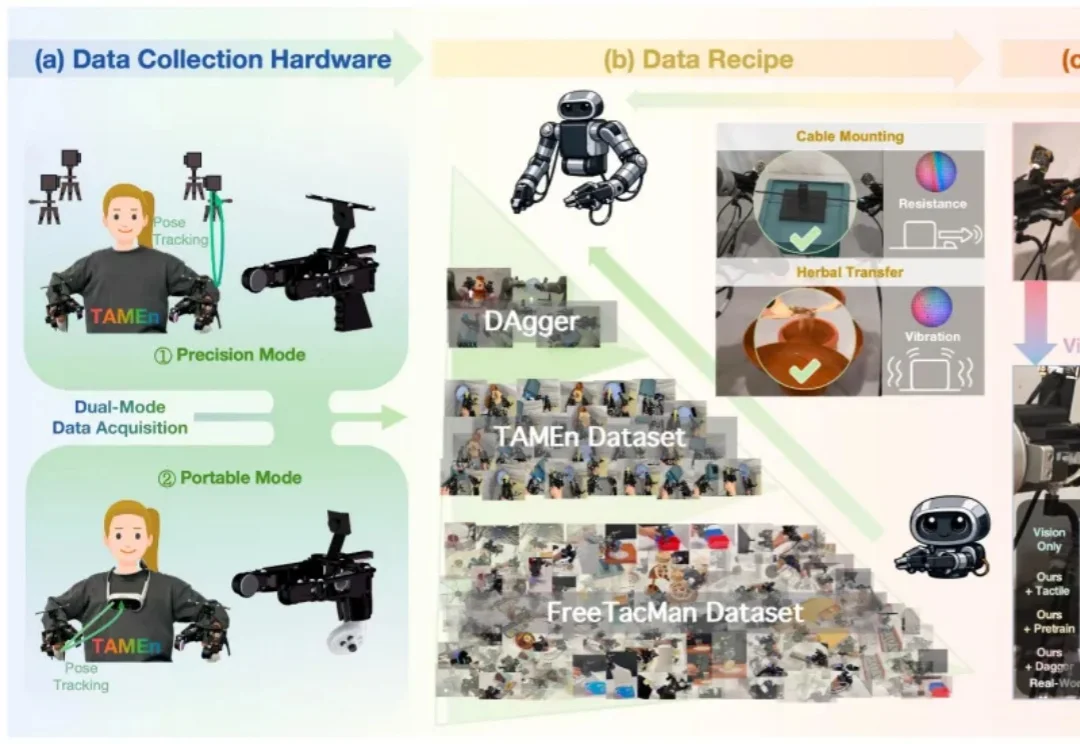
在具身智能快速发展的今天,高质量数据已成为驱动能力提升的关键基础,然而一个核心问题也随之而来: 如何让机器人数据采集更快、更稳、更有效?