# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

陈建宇(星动纪元创始人)、高阳(千寻智能联合创始人)、吴翼(蚂蚁集团强化学习实验室首席科学家)、许华哲(星海图联合创始人)的分享(题图从左至右),基本代表了国内具身智能领域最先进的成果展示。
7月27日,世界人工智能大会(WAIC)最“耀眼”的具身智能论坛,莫过于上海期智研究院举办的“人工智能交叉科学论坛”的主题活动。
这场论坛难得聚齐了当下国内具身智能领域的“伯克利四子”——吴翼、高阳、许华哲和陈建宇,这四位学者均毕业自加州大学伯克利分校,目前都从事具身机器人相关工作。
其中陈建宇创立了星动纪元,高阳为千寻智能联合创始人、许华哲为星海图联合创始人。吴翼则任蚂蚁集团强化学习实验室首席科学家。
这四位的罕见同台,分享内容自然离不开具身智能领域几大核心问题:
具身智能的瓶颈——“获取数据”,这个难题怎么解?
从简单任务(拿、放),到复杂任务(收拾屋子),机器人从大脑到本体该如何提升?
已经形成共识的“VLA算法”,里面又有哪些非共识的方法论?
除了创业者/大厂科学家的身份以外,吴翼、高阳、许华哲和陈建宇四位均担任上海期智研究院PI(Principal Investigator,首席研究员)。
姚期智为图灵奖得主、清华大学交叉信息研究院院长。2005年,姚期智创立“清华学堂计算机科学实验班”(姚班),以培养世界顶尖的计算机科学人才著名。上海期智研究院于2020年成立,姚期智担任院长。

△上海期智研究院院长、清华大学交叉信息研究院院长姚期智致辞 图片:上海期智研究院
以下观点来自陈建宇、高阳、吴翼、许华哲在“人工智能交叉科学论坛”的发言,由《智能涌现》总结、整理编辑:
畅想中会迎来一个与机器人有关的未来世界,我觉得达到这一愿景会有三个阶段。
第一个阶段,机器人将进入我们的生产力系统,生产手机、汽车等现在生活中所需物品。这个可能贡献超过目前一半的GDP。
第二阶段,机器人会成为最大的终端,也能够自己制造自己。
第三阶段,机器人可以帮助人类去拓展能力边界,比如马斯克说的火星移民。在长远的未来,机器人甚至能布满整个宇宙。
要实现这样的结果,我认为最短的路径是直接去学习人类的经验和数据,毕竟人类是现在世界上唯一的通用智能体。
具身智能的瓶颈,主要在于如何使数据和模型更高效。构建人形机器人,可以更方便机器人从人类的学习范式里学习。

△陈建宇和他分享的“具身智能数据金字塔” 图片:上海期智研究院
具身智能有一个数据金字塔模型,显示了具身智能训练数据的来源。
金字塔的塔尖是遥操作采集的数据,数据量大概在1万小时以内。但是我们训练语言模型的数据,如果换算成小时的话,大概是10的九次方小时,所以仅使用遥操作收集数据达不到具身智能需要的数据量。
而真正训练具身智能的数据量比语言模型所需数据量还要大一些,所以我们必须要用到人类行为的数据,这就是具身智能训练数据金字塔中间的一层。
我们可以通过VR眼镜、智能眼镜等终端采集到人类第一视角的数据。
金字塔的最底端是我们称为“一切发生在人类世界”的数据,也就是互联网上的广泛数据,比如视频网站。目前统计出Youtube上所有视频时长大概是10的十一次方小时。这类数据是现成的,而且非常非常多样化。
确实,在很多情况下我们可以用仿真,但仿真有一个致命问题,就是仿真里面没有人类这样的具身智能体去产生数据。
几乎所有的智能代码和行为数据都是由人类去产生的,而如果仿真能构建出这样一个智能体的话,实际上我们已经把这个“真”做出来了。所以这是一个鸡生蛋、蛋生鸡的问题。仿真基本上只能构建比较Passive的物理交互数据。
所以要构建人形机器人,直接去对标人类机体性能。比如星动纪元最新发布的星动L7,高度为1.7米,接近人类身高,同时它也有类人的胳膊、腰、头部以及腿部,能更好收集人类的多样性数据。
有人会关心双足机器人的成本是不是会更高,我认为不用特别担心这个问题。因为对通用机器人来说,降低价格最重要的因素在于规模化,而不是仅仅降低它的自由度。
通用人形机器人应用场景更多,随着规模起量,成本也将大幅下降;但专用或简易形态的机器人,由于可扩展的场景有限,所以也会限制规模化,所以成本的下降反而有限。
接下来,说说模型如何构建。当前主流的VLA(Vision-Language-Action,视觉语言动作模型)模型会存在一些问题,因为本质上来说它是在做纯粹的克隆。
问题一是模型只能从大量人类行为数据里克隆,缺乏举一反三能力;这也造成了第二个问题,机器人很难超越人类表现。
所以具身智能要参考人类的学习方式。
第一就是,建模整个世界,先形成物理世界的认知,类似我们说的“世界模型”。就像我们开车到十字路口会减速,即使没有经过大量的数据教学,人类也知道要防止撞到路口突然冲出来的人。
第二点就是,向人类学“强化学习”。比如学乒乓球,教练手把手教学是一个“模仿学习”的范式。但是这还不足以让人学会这么高难度的技巧,所以需要在自己训练中根据击球情况调整姿势,达到想要的效果,这就是“强化学习”。
所以我们的方法是,把VLM擅长的理解和世界模型擅长的生成进行结合,做成统一的模型,放到具身智能上。
这是我们做的融合世界模型的第一个探索PID模型,同一个模型不光做预测,同时也是做行为的生成。要找到相应的工具,最接近的工具就是类似sora基于diffusion视频生成的模型,因为它能生成非常细致的物理世界的行为环境动作。
基于Diffusion Policy,我们也有工具去很好地生成模型的行为。这样一来,具身智能就可以对视觉、以及其他模态做出预测。接下来我们提出了“Video Addiction Policy”,进一步扩大了我们的数据,运用大量的互联网和视频数据进行预训练,使得泛化性得到进一步提升。
最终,我们希望能真正把模型技术、数据通过我们不同形态的机器人,应用到现实生活中。通过一系列技术,机器人可以做出高动态全身运动,例如跳舞;除此之外可以完成操作,比如物流分拣

△千寻智能联合创始人高阳 图片:上海期智研究院
ChatGPT等模型取得今天的成功是基于拥有海量数据,但目前机器人的数据是非常匮乏的。当前公开最大的数据集,也才有不到100万条轨迹。相对互联网上文本、图文数据,相差好几个量级。
核心的问题是,我们到底该如何解决具身智能中的数据瓶颈,我认为最重要的方式就是“数据金字塔”。就是说我们要利用不同质量、不同来源的数据,把数据量去堆上去。
刚才陈建宇老师也提到了具身智能数据金字塔。我将具身智能数据分为上中下三层,下层是海量的互联网视频;中间层是人类操作数据;最上层是强化学习数据,也就是让机器人在会某个技能之后,与环境进行进一步交互来修正它的能力使成功率达到99%以上,所使用的数据。
我今天想说的是,在具身智能的金字塔再往后一步,就是硬件的感知层面和获取数据后的模型结构方面再做提升。
从感知层面而言,现在VLA只有视觉,但是对人类来说触觉是一个非常重要的模态,比如插U盘的动作,人并不一定需要眼睛盯着USB口。但如果机器人要盯着才能完成这个工作,姿势会非常奇怪。
现在提出的“TactileVLA”概念,就是在VLA基础上加上触觉。再举一个例子,比如机器人擦黑板,一遍没擦干净,它会用VLM尝试思考,是不是因为黑板上的字迹特别顽固,要再用更大力气再擦一遍。
通过带触觉输入,带触觉输出,以及带触觉反馈的过程,就可以把触觉非常好的融合到VLA的模型里。
有了触觉,让具身智能去拿不同的物体,可以通过预训练知识让它拿得更好。比如说拿水果和拿铁块的力不一样。
就可以结合触觉具有摩擦力等功能对擦黑板工作进行更准确判断。
在通过数字金字塔获取到丰富数据量之后,还需要一个好的数据结构,让机器人从目前的数据里面学到正确知识。就像大语言模型有Transformer架构。
当我们想让机器人做伏特加调酒的时候,面对面前巨多的瓶瓶罐罐,具身智能要把动作分解成若干可以去执行的原子动作。但如果只用VLA做反思性思考,或者我们常说的System1思考模式(一种大脑处理信息做决策的方式,更偏直觉、速度快)成功率会非常低。
我们提出了OneTwoVLA,是一种把System1和System2(大脑的系统性思考,速度更慢),做结合的模型。这个模型在接到任务之后会自主判断,当前的任务是需要进行分析还是只完成当前的动作路径。
具体而言,比如一个涮火锅机器人机器人面前有很多食材。你让它涮牛肉,它就涮牛肉;你让它涮蔬菜,它会发现面前有很多种类蔬菜,于是停下来问用户涮哪一种。通过这个模型,可以把任务在结构的层面上进行分解,达到更好的效果。

△蚂蚁集团强化学习实验室首席科学家吴翼 图片:上海期智研究院
我们的终极目标是要让机器人走进千家万户,做很复杂的任务。
但是即使我们实现了当前所有的技术,可能还是未必达到这个愿景。那这个过程中我们是不是漏掉了什么?
从2022年ChatGPT开始,当时大模型可以基于人类指令,被动回答问题;到2025年退出Agent智能体,可以回答非常复杂的、宏观且抽象的问题,主动做很多工作。三年间,大语言模型的发展非常迅速。
机器人领域,我想也会有这样一个过程。比如有一天我告诉“它把屋子进行打扫”这样一个抽象的任务,它会自己调用工具完成。所以这就是一个具身智能体(Embodied Agent),像Agent一样工作,但有物理的身体。
我们也可以从Agent的构建上,去寻找具身智能体的启发。
一个AGI智能体需要有三个能力:规划、记忆调整、使用工具。我们希望具身智能体也有这样的三种能力。
Agent是Function Call(工具调用)智能体,同理,具身智能体也可以调用不同的Function。具体而言,具身智能体会先做逻辑推理,然后写代码,然后具身智能体会做代码执行。
我们可以想象家里有一条四足机器狗,现在想让它关灯,但是它的高度距离开关有一定差距,需要踩着一个箱子,完成这个动作。
在和物理世界交互时机器狗发现,踩着一开始的箱子仍然达不到灯开关的高度,那从这个出错的地方往后的代码都没有用了。大模型会从这里开始重新思考,写一段新代码去换一个高度合适的箱子,然后机器狗去执行新的代码。
这个过程中,有一个软件智能体在执行,还有一个硬件和现实世界做交互。
总结一下,就像大模型可以从ChatGPT可以进化成Agent,希望具身智能也可以从机器人进化成具身智能体。
再往后展望一下,我们希望未来不只是一个具身智能体,而是很多具身智能体交互,也就是所说的Multi-agent的概念。比如一个机器狗足球队,多个机器狗一起踢球,会有竞争和合作;人和机器狗之间也可以有类似的人机交互。
最后对未来做一个展望,我觉得未来世界会是一个具身智能体的世界,有很多聪明机器人,做很复杂的任务;人也可以和机器狗交互,牵机器狗着上街。
最后推荐一下我的AReaL开源项目,希望通过这个开源框架帮助大家做更好的智能体。

△星海图联合创始人许华哲;图片:上海期智研究院
一个机器人,从它看一张图,做一件事开始,最后它的行为形成了规模定律。这中间有怎样的故事线呢?
我和一些观点倾向认为,具身智能在小规模数据的情况下,是一场背诵的游戏。
比如模型看到一个图片,是桌面上有多个工具,它可以背下来这几个工具的使用方法、在不同方向放置的情况下如何进行最好的拿取。但很显然,这样的模型是很难有好的泛化性。
所以,真正的挑战,如果这个图片里的空间非常巨大,模型就不能靠纯背诵做好工作。这就产生了对泛化和规模化的需求。
所以还是要有足够多的训练数据,覆盖范围足够广,这样机器在非常大量的数据中可以学到一些本质的东西。比如说在世界各地的人都能看到不同的物体从高处落下,最后总结出了本质“牛顿定律”。
但是现在采集数据的技术路线或多或少都有一定的问题。我个人怀疑,现在的数据采集永远都到不了我们想要的规模。
目前我们有人类数据,也有仿真数据,他们虽然很便宜、也可以大量提供,但是如果数据里是一些与现实世界有冲突的内容,那就未必能学到本质的东西。
如何把有偏移的“牛顿定律”挪回正确“牛顿定律”的位置,这是一个未解之谜。这也是为什么具身智能现在不能像大模型一样立刻很好地干活,简而言之问题就是数据不够好。
多的数据不好,好的数据不多。但不能“放弃治疗”,我有一个解决方法。
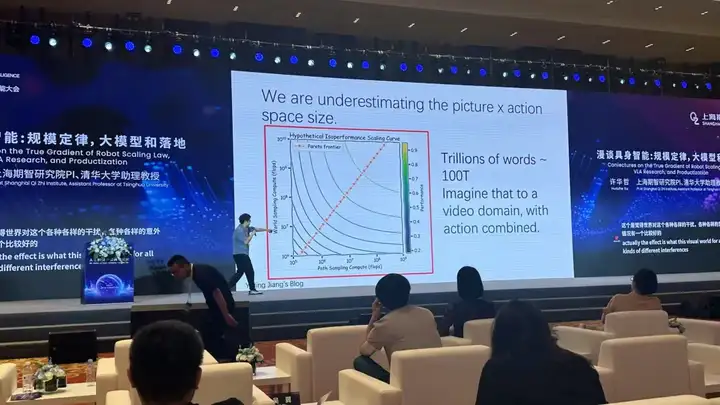
△许华哲提出的具身智能数据Scaling坐标包括横轴Path Sampling,和纵轴World Sampling,单边提升也可以对Scaling形成促进 图片:作者拍摄
就是我们在谈具身智能数据Scaling的时候,有横轴、纵轴两个坐标可以影响它,一个叫World Sampling,另一个叫Path Sampling。
举一个例子,就像是让具身智能学习倒水这个动作,World Sampling是它在不同的“世界”里倒水的案例。比如在办公室倒水、在家里倒水、在酒吧倒水;而Path Sampling是说先不用管它的位置,可以在家里这一个场景用不同动作路径实现倒水。
现在我的组里也在沿着Coodinate(坐标)这一方向去做研究。
所以我的非常粗糙的猜想是,具身智能很难在这个坐标里,沿着一个理想的上升斜线往右上角行进。因为它需要的数据量太大,而我们现在拿不到。
所以我们或许可以先沿着其中一个轴做得好一些,再沿着另一个轴做突破。而不是一开始就在World Sampling这条轴上采集很多很多数据,这样所需要覆盖的空间就会太大了,工作量也会太大。
文章来自于“智能涌现”,作者“富充”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
