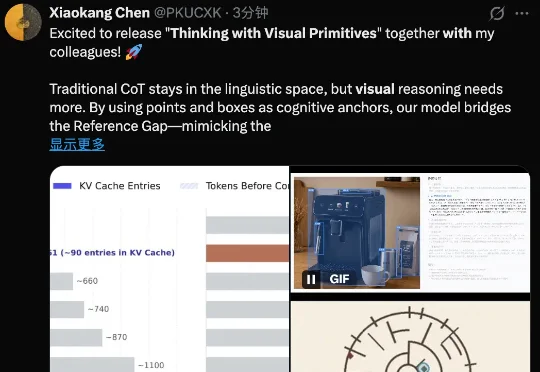
刚刚,DeepSeek多模态技术范式公布,以视觉原语思考
刚刚,DeepSeek多模态技术范式公布,以视觉原语思考刚刚,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。实打实的新鲜出炉!而且是开创性的推理范式。下面我们就基于 DeepSeek 这篇技术报告,具体看看 DeepSeek、北京大学、清华大学又创造了怎样的奇迹。
来自主题: AI技术研报
9871 点击 2026-04-30 20:24
 搜索
搜索
刚刚,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。实打实的新鲜出炉!而且是开创性的推理范式。下面我们就基于 DeepSeek 这篇技术报告,具体看看 DeepSeek、北京大学、清华大学又创造了怎样的奇迹。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
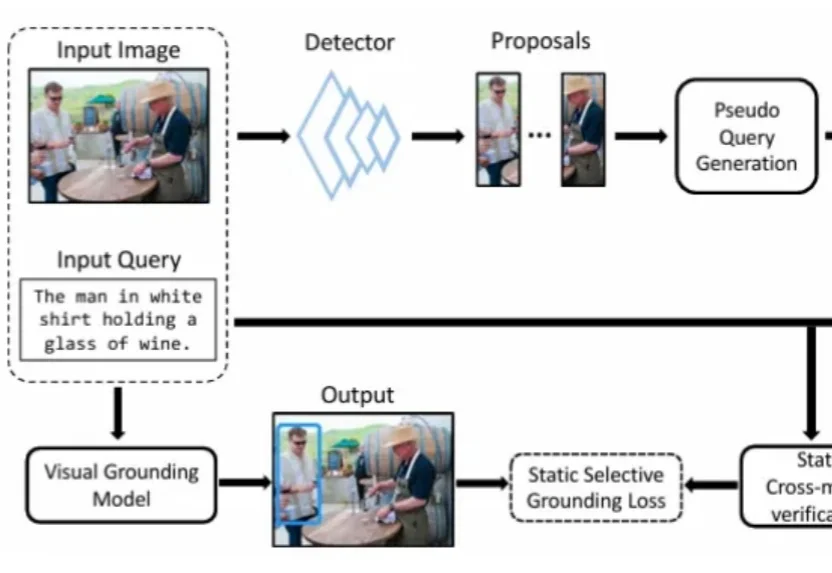
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。
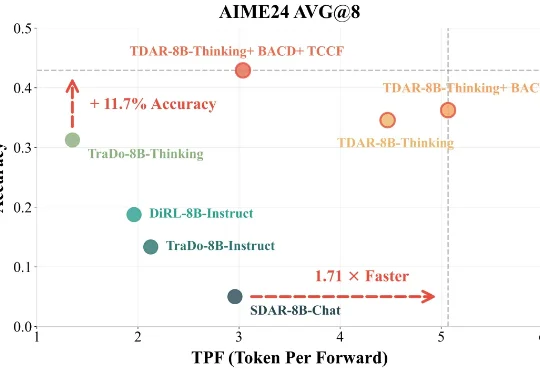
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
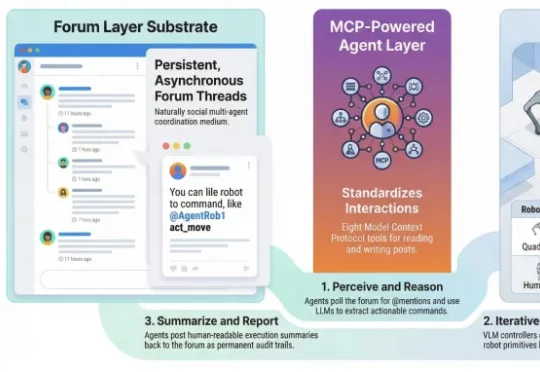
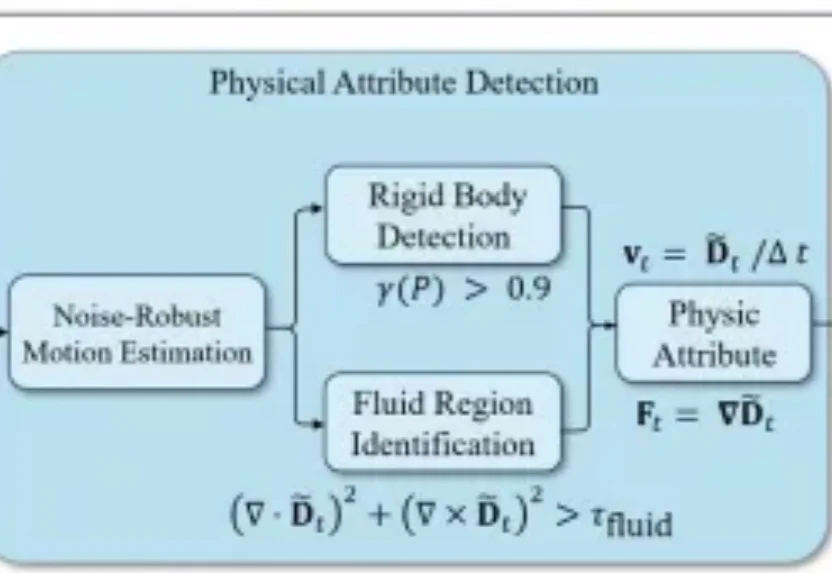
公元前47年,凯撒在泽拉战役速胜后给罗马元老院写了三个词的战报:「Veni, Vidi, Vici」——我来了,我看见了,我征服了。 两千多年后,北京大学杨仝教授团队也用三步定义了一种全新的AI范式:降临论坛、接管指令、统治物理世界。

来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混