
北大校友创办,AI虚拟细胞公司元示科技获上亿元融资,落地上海!
北大校友创办,AI虚拟细胞公司元示科技获上亿元融资,落地上海!近日,专注于第二代人工智能制药技术的元示科技有限公司完成近亿元最新一轮融资。公司由北京大学前沿交叉学科研究院2017级博士吴佳奇创立,核心研发方向为人工智能虚拟细胞与通用细胞大模型,是国内较早布局细胞级AI药物研发的初创团队。
来自主题: AI资讯
7948 点击 2026-07-25 11:39
 搜索
搜索
近日,专注于第二代人工智能制药技术的元示科技有限公司完成近亿元最新一轮融资。公司由北京大学前沿交叉学科研究院2017级博士吴佳奇创立,核心研发方向为人工智能虚拟细胞与通用细胞大模型,是国内较早布局细胞级AI药物研发的初创团队。

近日,新基石研究员、北京大学集成电路学院教授、深圳研究生院信息工程学院院长杨玉超团队,联合中国科学院上海微系统与信息技术研究所宋志棠研究员团队等,在国际顶级学术期刊《科学》发表最新成果,在新型神经动力学计算芯片领域取得重大突破。
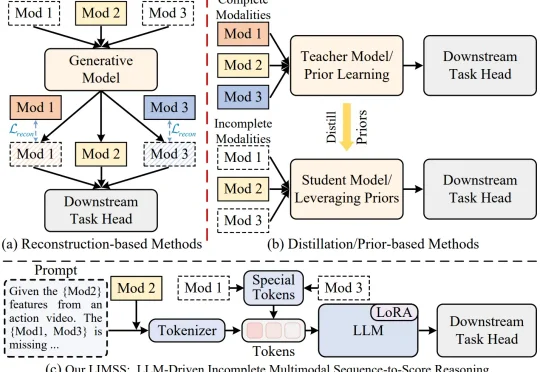
本文是北京大学彭宇新教授团队联合福州大学柯逍教授团队在细粒度多模态动作质量评价领域的最新研究成果,相关论文已被 ICML 2026 接收为 Spotlight,并已开源。真实世界中的多模态数据往往并不完整。在动作质量评价任务中,视频、光流、音频等模态能够从不同角度描述动作执行过程,但在实际采集时,传感器故障、环境噪声、隐私限制等因素都会导致模态缺失。
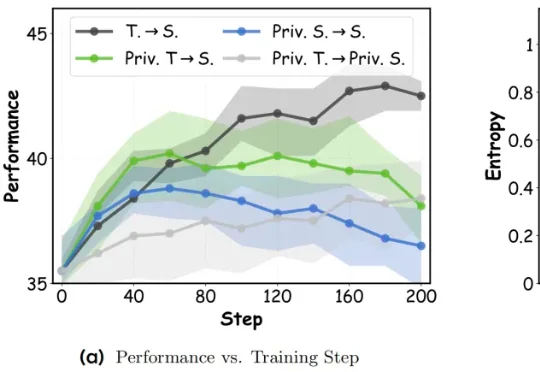
最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。

独家获悉,一支北大出身、手握国际顶级超算成果的核心技术团队已完成市场化主体搭建,正式布局物理AI底层基础设施赛道。团队由北京大学杨超教授领衔,杨超是我国首位 ACM 戈登贝尔奖得主,2016 年带领团队拿下该国际超算最高荣誉,实现了我国在该奖项上零的突破;其本人也获评首届王选杰出青年学者奖,在高性能计算、数值仿真、人工智能等领域长期深耕。
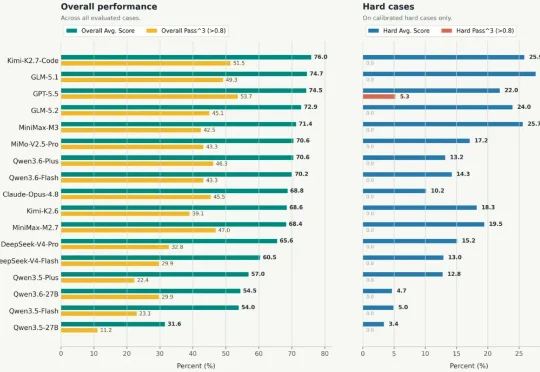
三星大模型团队联合北京大学、香港城市大学、香港科技大学等科研机构,共同发布了面向 AI Agent 的基准测试 LiveClawBench。它关注的并不是「谁的 Agent 更强」,而是一个更基础、也更关键的问题:为什么同一个 AI Agent,在一些任务中已经接近可用,而在另一些任务中却会突然失稳?
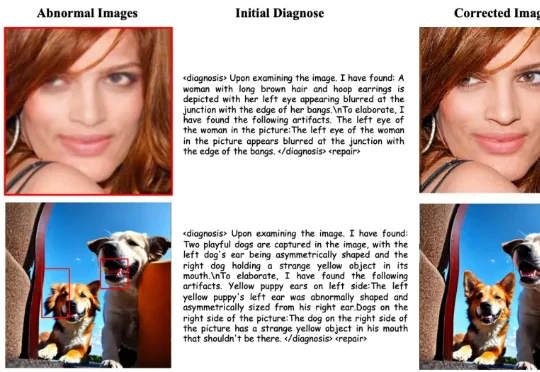
对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

近日,北京大学 EvoPhys 团队推出首个以 “人” 为中心的 “场景级万物可控” 5D 世界模型 EvoPhys-World,基于摩尔线程全国产算力底座,团队首次将 AI 生成世界从 “可观看、可漫游,浅交互” 的阶段,推进到 “可操纵、深交互、自进化” 的新阶段。
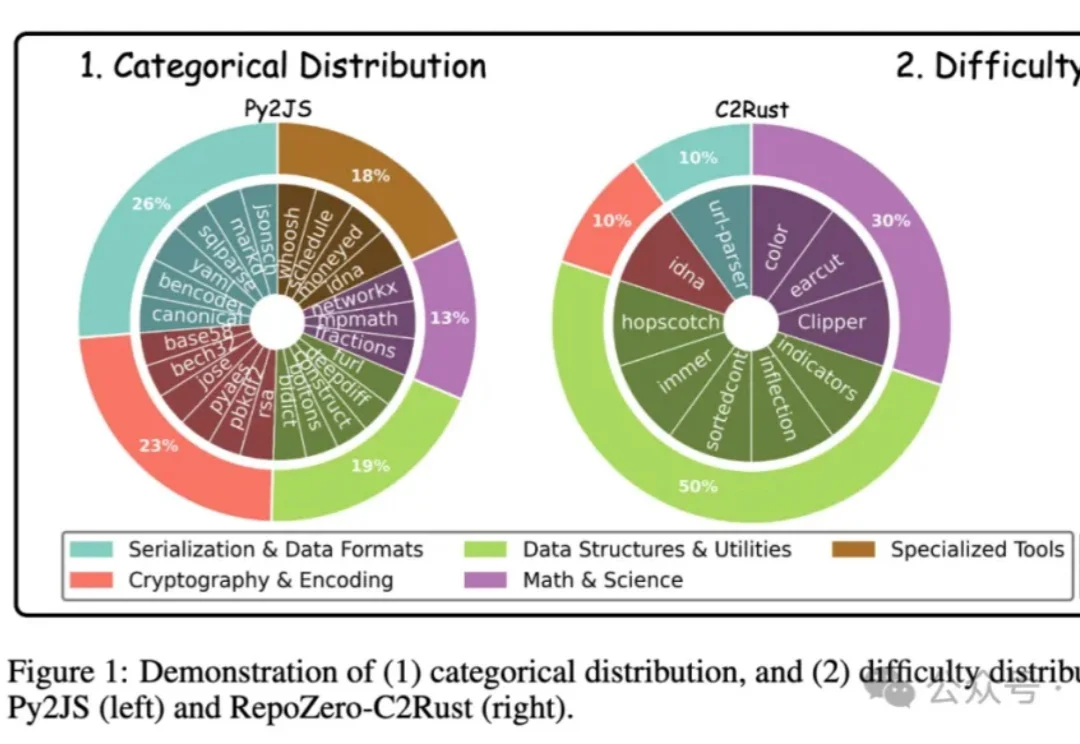
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。