
中国医疗AI拿下全球第一!14亿人的微信「私人医生」重磅升级
中国医疗AI拿下全球第一!14亿人的微信「私人医生」重磅升级过去十年,医疗AI经历了两次范式跃迁。
来自主题: AI资讯
7116 点击 2026-07-28 15:15
 搜索
搜索
过去十年,医疗AI经历了两次范式跃迁。

2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。

刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
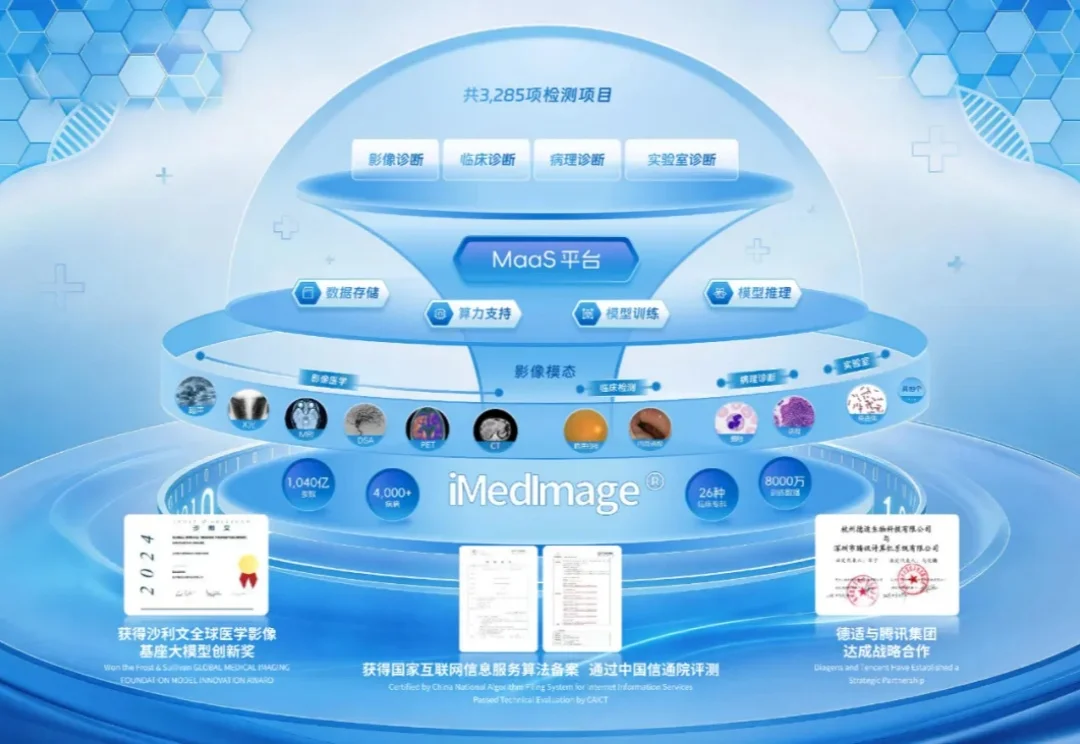
德适AI获三类医疗器械证,医疗AI产业化迎来新突破。
一家估值超5000亿美元的币圈富豪公司,秀出了性能碾压谷歌的AI医疗大模型。

火爆全网的Harness架构,终于在最难的医疗圈落地了!从单次问诊到全天候赛博名医盯盘,大健康赛道彻底变天。

近日,预防医疗AI公司睿禾健康(ReHealth AI)宣布完成400万元人民币种子轮融资,投后估值2500万元,投资方未披露。
最近,一家医疗AI公司给出了更「系统级」的解法。刚刚,智诊科技(WiseDiag)正式发布企业级医疗健康行业智能体平台WiseClaw!它的产品底座,正是来自OpenClaw架构。

医疗AI终于走出了「只会聊天」的舒适区。今天,斯坦福与普林斯顿联手NVIDIA发布MedOS。这不是一个单纯的手术机器人,而是全球首个通用医疗具身世界模型。从临床诊断到治疗,从外科手术到药物研发,MedOS正在让AI真正读懂「生老病死」的物理现实。
基于真实居民健康档案构建的MedLLM-EHR-EVAL-V2评测集显示,星火医疗大模型在智能健康分析、报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,得分均显著超越国内外主流大模型。