

当 AI 从试点进入规模化,华为数字金融的长期选择
当 AI 从试点进入规模化,华为数字金融的长期选择作为华为服务金融客户的窗口,华为数字金融军团不仅在全联接大会上回顾了过往案例,更重点推出了应对 AI 落地挑战的 FAB(FinAgent Booster)金融智能体加速器。帮助客户快速建立自己的 Agent 能力,缩短开发周期,让 AI 加速融入业务流程。
来自主题: AI资讯
8312 点击 2025-09-23 23:21
作为华为服务金融客户的窗口,华为数字金融军团不仅在全联接大会上回顾了过往案例,更重点推出了应对 AI 落地挑战的 FAB(FinAgent Booster)金融智能体加速器。帮助客户快速建立自己的 Agent 能力,缩短开发周期,让 AI 加速融入业务流程。

AI浪潮席卷全球,金融行业正迎来深刻变革。华为以全栈技术为依托,携手金融机构打造高效算力底座,重磅发布「金融智能体加速器FAB」,让AI智能体加速在金融落地生根。

在华为全联接大会2025上,鸿蒙操作系统5展示了其更强大的AI全场景能力,包括“小艺任务空间”“情绪感知”以及“小艺大脑”等一系列更高阶的AI全场景体验。无论是出差订票、日程安排,还是多设备联动播放音乐,AI助手小艺都能听得懂、做得到。
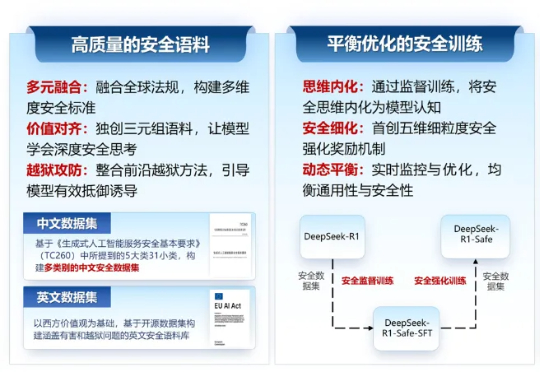
2025年9月18日,由浙江大学计算机科学与技术学院院长、区块链与数据安全全国重点实验室常务副主任任奎教授团队联合华为技术有限公司计算产品线共同研发的国内首个基于昇腾千卡算力平台的DeepSeek-R1-Safe基础大模型在“华为全联接大会2025”正式发布。

继余承东三折叠手机发布会上亮相麒麟芯片后,AI算力芯片也有了最新进展。就在华为全联接大会上,轮值董事长徐直军,带来了全球最强算力超节点和集群!Atlas 950 SuperPoD和Atlas 960 SuperPoD超节点,分别支持8192及15488张昇腾卡。

近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。
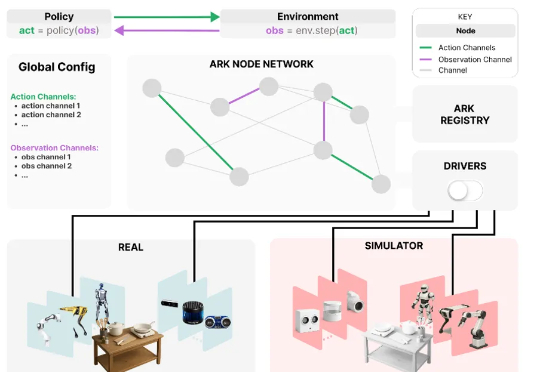
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
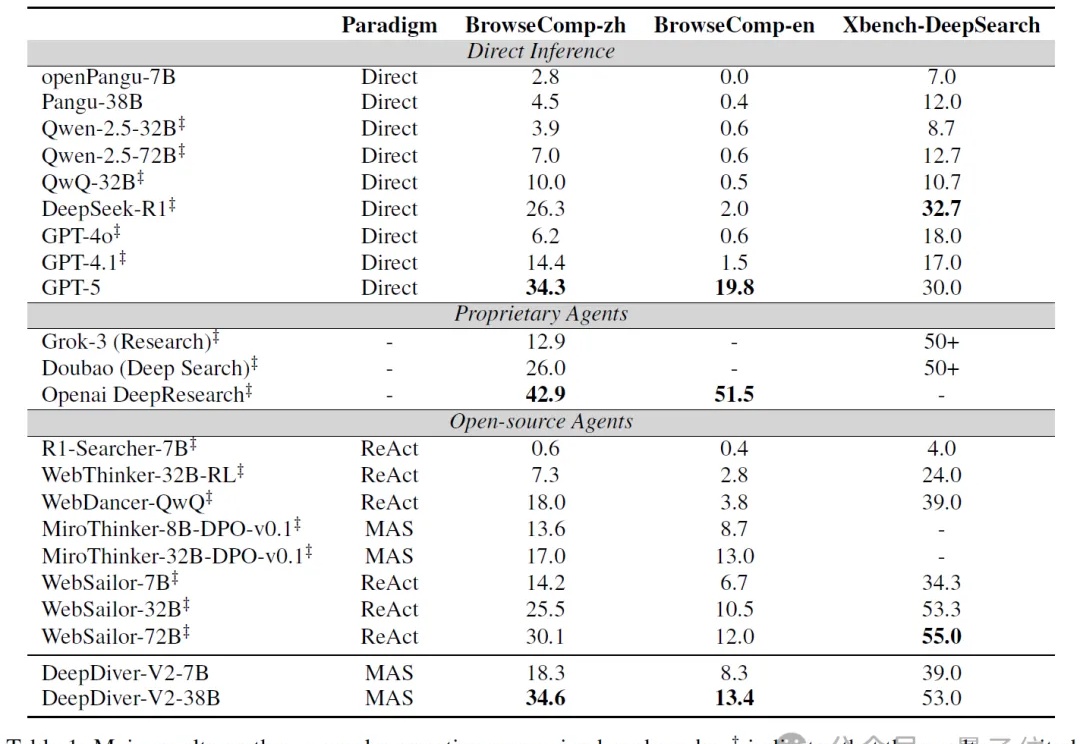
让智能体组团搞深度研究,效果爆表!

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!
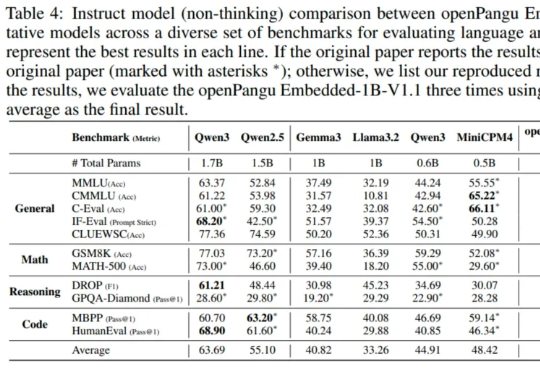
在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。