
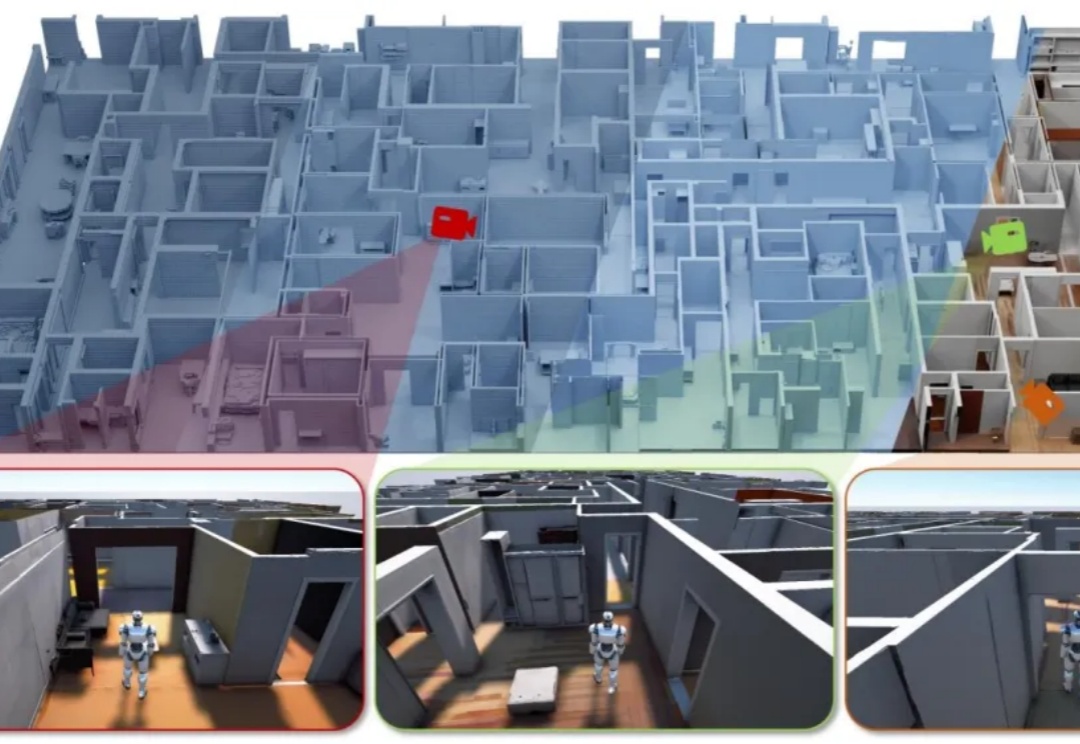
华为世界模型来了!单卡30分钟生成272㎡场景
华为世界模型来了!单卡30分钟生成272㎡场景AI大house真来了。
来自主题: AI技术研报
6818 点击 2025-10-28 15:07
AI大house真来了。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。
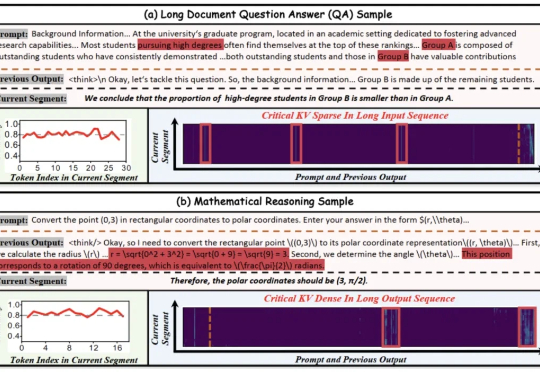
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。
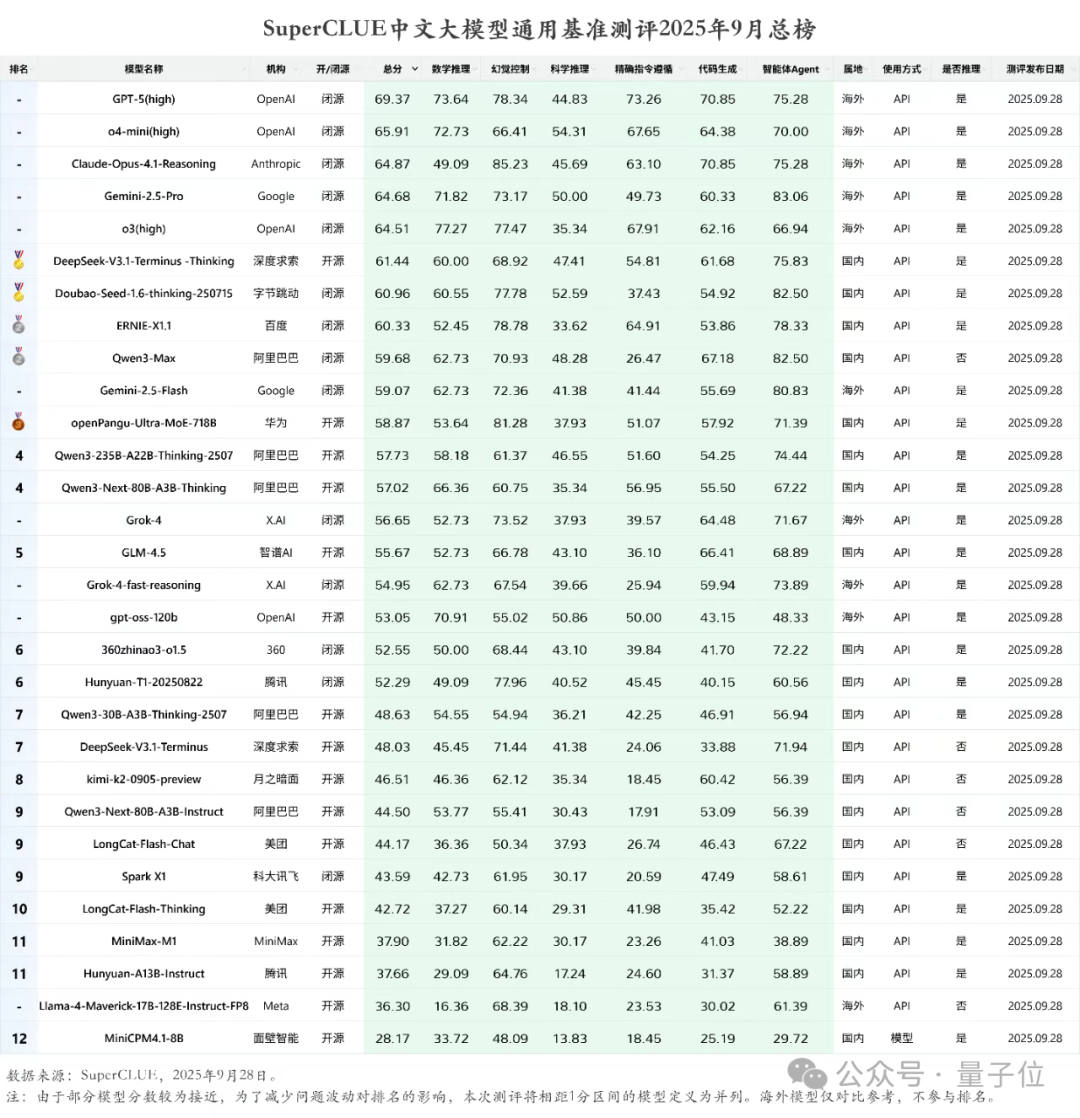
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507

我想聊个反向操作:咱们普通人,如何用有限的资源,轻松驯服一个 AI 模型,让它变成我们专属的垂直领域小能手?主角,就是最近华为刚刚开源的一个大小仅为 1B 的模型 openPangu-Embedded-1B,它不仅全面领先同规格模型,甚至与更大规模的 Qwen3-1.7B 也难分伯仲。
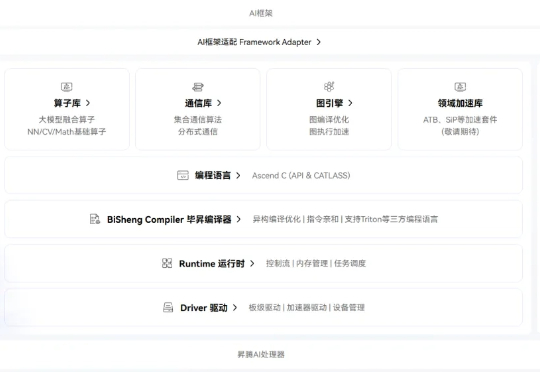
AI 行业很多人相信,我们正在或已经进入所谓的「AI 下半场」。在这一轮 AI 的浪潮中,硬件的竞争早已不再是单纯的算力比拼,而是一场围绕软件、开发者与生态的「护城河」之战。当国产 AI 生态的转型成为科技领域的时代呼声,华为昇腾及其异构计算架构 CANN 正站在了这场变革的聚光灯下。
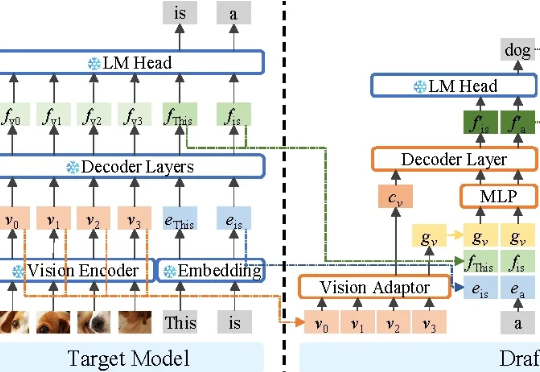
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。
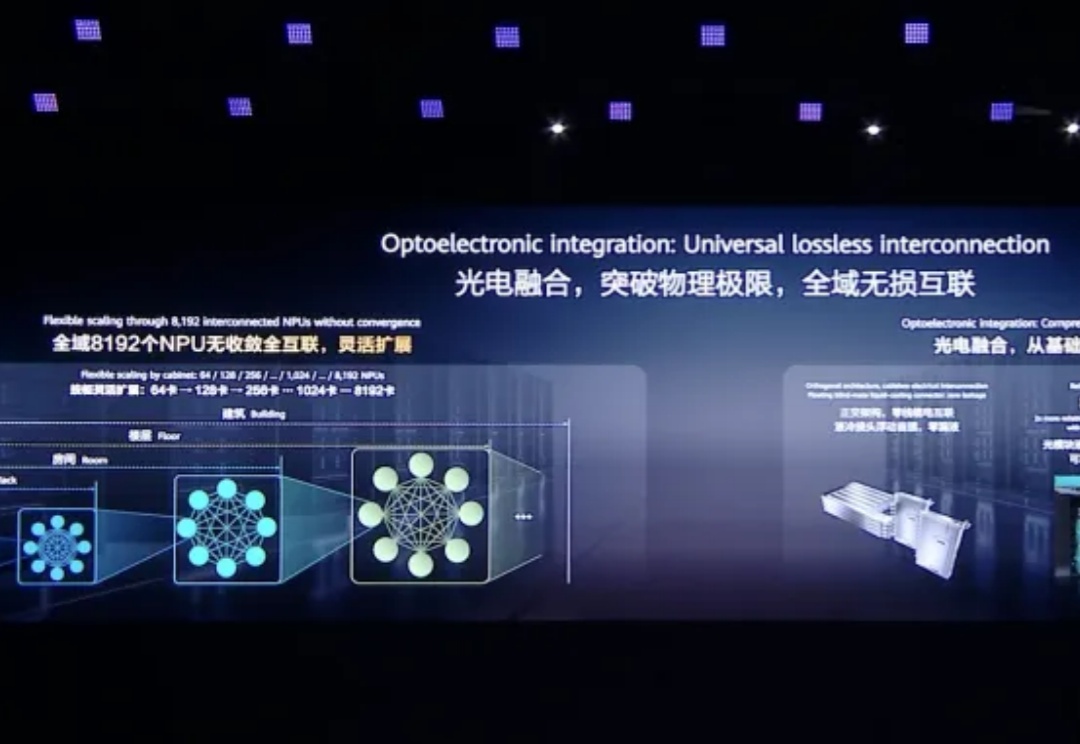
上周,华为全联接大会集中展示了华为最新最强的一系列创新。

在运营端,技术融合破解管理痛点:深圳明源云与华为共建 “业务-数据-AI” 三层平台,支撑建设、招商、运营、资管等四大AI场景落地,助力推动不动产投建营业务AI时代的变革。