
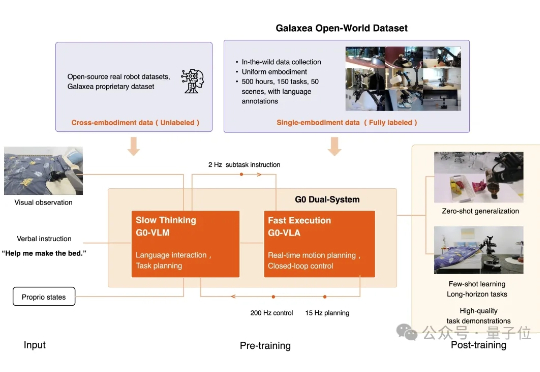
WRC整理床铺机器人背后模型曝光!端到端双系统全身智能VLA,仅凭少量微调就能get任务
WRC整理床铺机器人背后模型曝光!端到端双系统全身智能VLA,仅凭少量微调就能get任务仅凭少量后训练微调,机器人就能完全自主、连续不断地完成床铺整理任务。 而它的每一步思考与动作实时投放在大屏幕上。
来自主题: AI资讯
6988 点击 2025-08-12 11:18
仅凭少量后训练微调,机器人就能完全自主、连续不断地完成床铺整理任务。 而它的每一步思考与动作实时投放在大屏幕上。
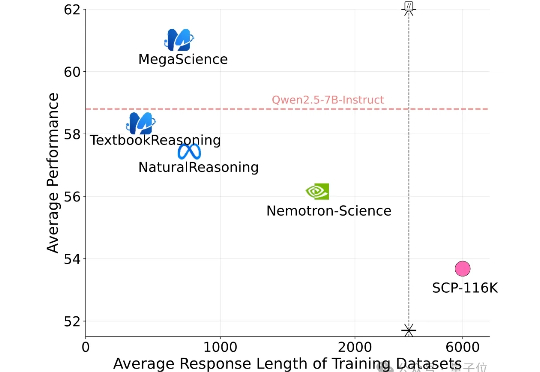
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。

尽管全球科技界正热烈庆祝 GPT-4、DeepSeek 等大模型展现出的惊艳能力,但一个根本性问题仍未被真正解决: 这些 AI 模型是否真正理解人类的指令与意图?

随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。

美国AI初创公司 Perplexity 的联合创始人兼首席执行官Aravind Srinivas今日在社交平台发文,首次公开评价中国大模型“月之暗面”Kimi K2。他表示,Kimi K2 在内部测试中表现良好,Perplexity 正在考虑在其基础上进行后训练。
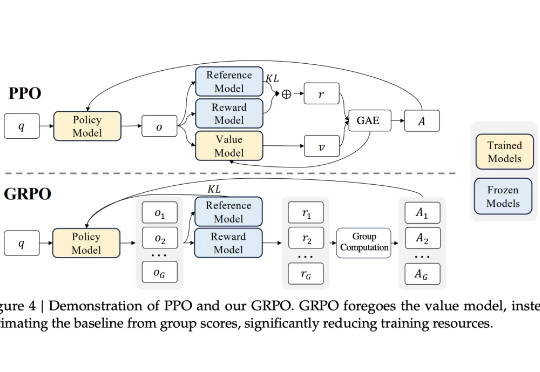
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。

扎克伯格又从奥特曼手里挖走4名顶尖AI人才,这次四位都是华人研究员。
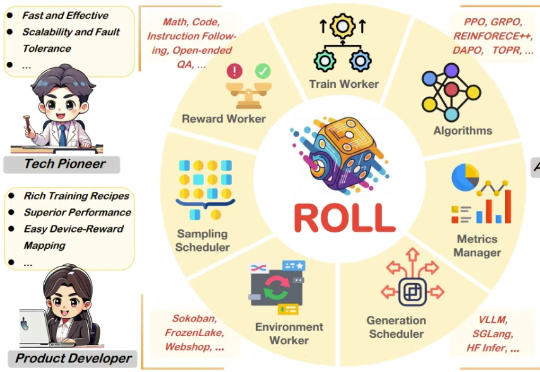
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。