# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?
当前(多模态)大模型正深陷「数据饥渴」困境:其性能高度依赖预训练阶段大量高质量(图文对齐)数据的支撑。
然而,现实世界中这类高价值数据资源正在迅速耗尽,传统依赖真实数据驱动模型能力增长的路径已难以为继。
在 NeurIPS 2024 会议上,OpenAI 联合创始人 Ilya Sutskever 明确指出:「Pre-training as we know it will end。」这一判断成为对传统预范式极限的清晰警示。
为延续性能提升,主流研究方向开始转向推理优化与后训练微调(如强化学习)。
然而,最新研究表明:此类改进极其依赖模型在预训练中所奠定的能力基础。
如果模型在早期未能系统性地习得相关能力,后续优化就如同在沙地上建高楼——进展有限,风险颇高。
不同模型在「自我进化」能力上的表现也存在巨大差异,其实质仍是「题海战术」的延伸:缺乏方法论支撑的训练,难以应对真实世界中的复杂和变化。
面对这一瓶颈,大模型的未来路在何方?
微软研究院科学家 Shital Shah 在社交媒体上指出:合成数据(synthetic data)或许是打破当前能力天花板的关键。
近日,港中文联合清华等高校提出:未来大模型性能的持续提升,需依赖「预训练、推理阶段的计算扩展、后训练优化」三者的深度协同。
这一观点打破了传统依赖单一预训练路径的范式,为下一代多模态基础大模型(Foundation MLLMs)的构建提供了全新思路。

Foundation MLLMs via Self-Improving Systematic Cognition
在此基础上,研究团队提出了创新性框架——SICOG(Self-Improving cognition),旨在重塑大模型的进化路径。
SICOG 引入了独创的「链式描述」技术,通过五步渐进式视觉解析引擎,实现模型从显著内容捕捉到细粒度关联推理的全面感知跃升。
该框架同时采用了「结构化思维链」机制,有效增强模型对多模态信息的融合处理与复杂推理能力。
更具突破性的是,SICOG 通过自生成数据闭环 + 语义一致性筛选机制,使模型在零人工标注的条件下实现认知能力的持续进化,真正迈向高效、自主的学习范式。
SICOG 的提出,不仅打破了当前模型在数据、算力与微调优化三者割裂发展的瓶颈,也为未来通用人工智能(AGI)模型的构建提供了可扩展、可迁移的新路径。
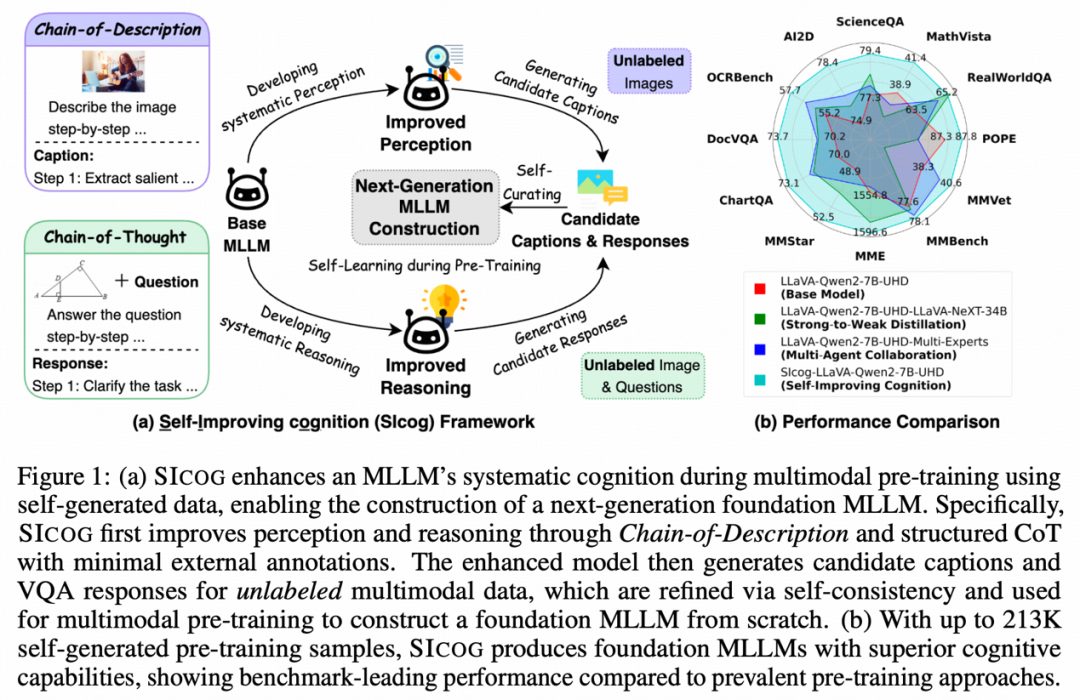
传统多模态大模型(MLLMs)依赖海量标注数据与静态预训练范式,面临数据稀缺与能力增长受限的双重瓶颈。
为突破这一困境,本文提出全新框架 SICOG(Self-Improving cognition),
首次构建了涵盖「后训练增强—推理优化—再预训练强化」的三位一体自进化机制,重新定义了预训练边界,为下一代 MLLMs 注入动态认知与持续学习能力。
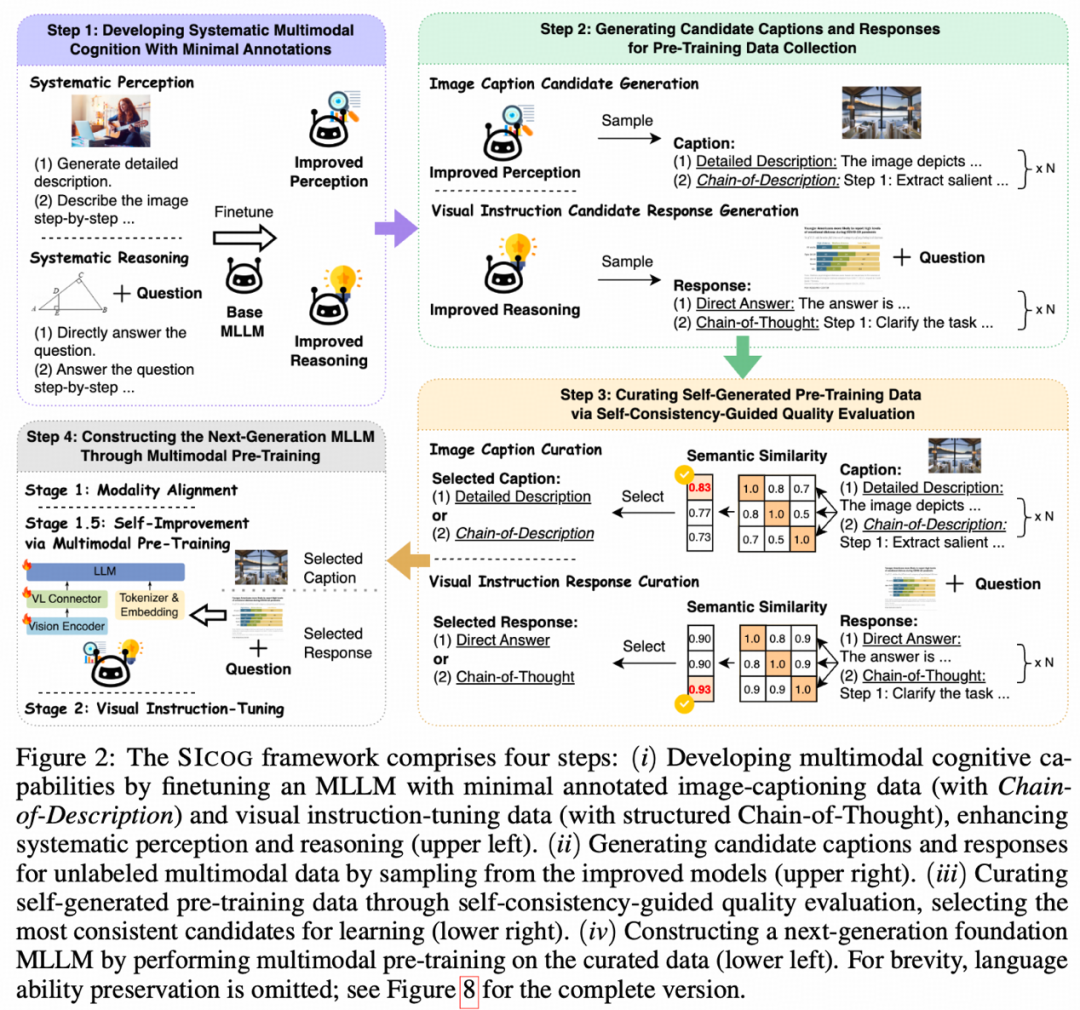
SICOG 的三阶段协同机制包括:
1.后训练增强:利用少量高质量标注数据,提升模型的系统性认知与基础推理能力;
2.推理优化:在大规模无标签多模态数据上进行自主推理,通过「自我一致性投票机制」筛选出高置信度答案,自动生成伪标签;
3.再预训练强化:将筛选后的高质量伪标注数据反馈用于预训练,实现模型能力的持续进化。
SICOG 的关键创新在于实现了模型的「学中实践、实践中进化」:
从少量种子数据出发,模型通过「看图总结 + 解题推理」主动构建多任务样本,实现数据生成与学习闭环。
无需大规模人工标注,即可高效扩展预训练数据,根本性缓解当前高质量多模态数据稀缺的问题。

描述链(Chain-of-Description, CoD):让模型「看图像像人一样」
CoD(描述链)是一种结构化分步感知方法,使模型像侦探一样逐层观察图像,从主体到细节、从关系到背景,构建出完整、逻辑严密的图像理解过程。
以「一位女孩弹吉他」的图像为例,传统模型可能仅生成「女生在弹吉他」的粗略描述,而 CoD 会分为五个有序阶段,逐步深化理解:
1.提取主体内容
2.分析细节信息
捕捉纹理、颜色、光影等低层信息,增强描述的丰富性与精度。
3.考虑关系属性
4.检查边缘/背景内容
5.整合为连贯描述
通过 CoD,模型能够逐步「构建图像语义结构」,实现从感知到理解的飞跃,显著提升图文对齐的质量与逻辑性。
结构化解题思路(Structured Chain-of-Thought, CoT):让模型「解题像学霸一样」
Structured CoT (结构化思维链)是一种任务驱动的推理框架,
支持模型在面对复杂问题时进行分步推理、信息整合与因果判断,广泛应用于数学计算、逻辑问答、跨模态推理等任务。
例如,在一道几何题中,传统模型可能直接尝试「猜测答案」,而 Structured CoT 的解题过程如下:
1.明确任务目标
2.提取关键信息
3.逻辑推理分析
4.总结计算得解
Structured CoT 让模型具备类人的「解题能力」,不仅能处理复杂的数理任务,还能支持跨模态因果推断,奠定模型认知系统化的基础。
能力全面跃升:SICOG 的三大关键优势
借助 CoD 和 Structured CoT,SICOG 不仅构建了结构化的感知与推理流程,更在训练范式上实现了根本性突破,具备以下三大核心优势:
1.显著降低对高质量数据的依赖
2.实现动态认知进化
3.感知与推理一体优化
实验验证:SICOG 实现模型能力全面提升
为了验证 SICOG 框架的有效性,研究在 12 个主流多模态评测集上进行了系统性评估,涵盖图表理解、数学推理、抗幻觉能力等多个关键维度。
实验结果表明,SICOG 能显著提升模型的综合表现,具体成果如下:
综合性能稳步提升
幻觉控制能力增强
自生成数据推动持续进化
超越主流预训练方法
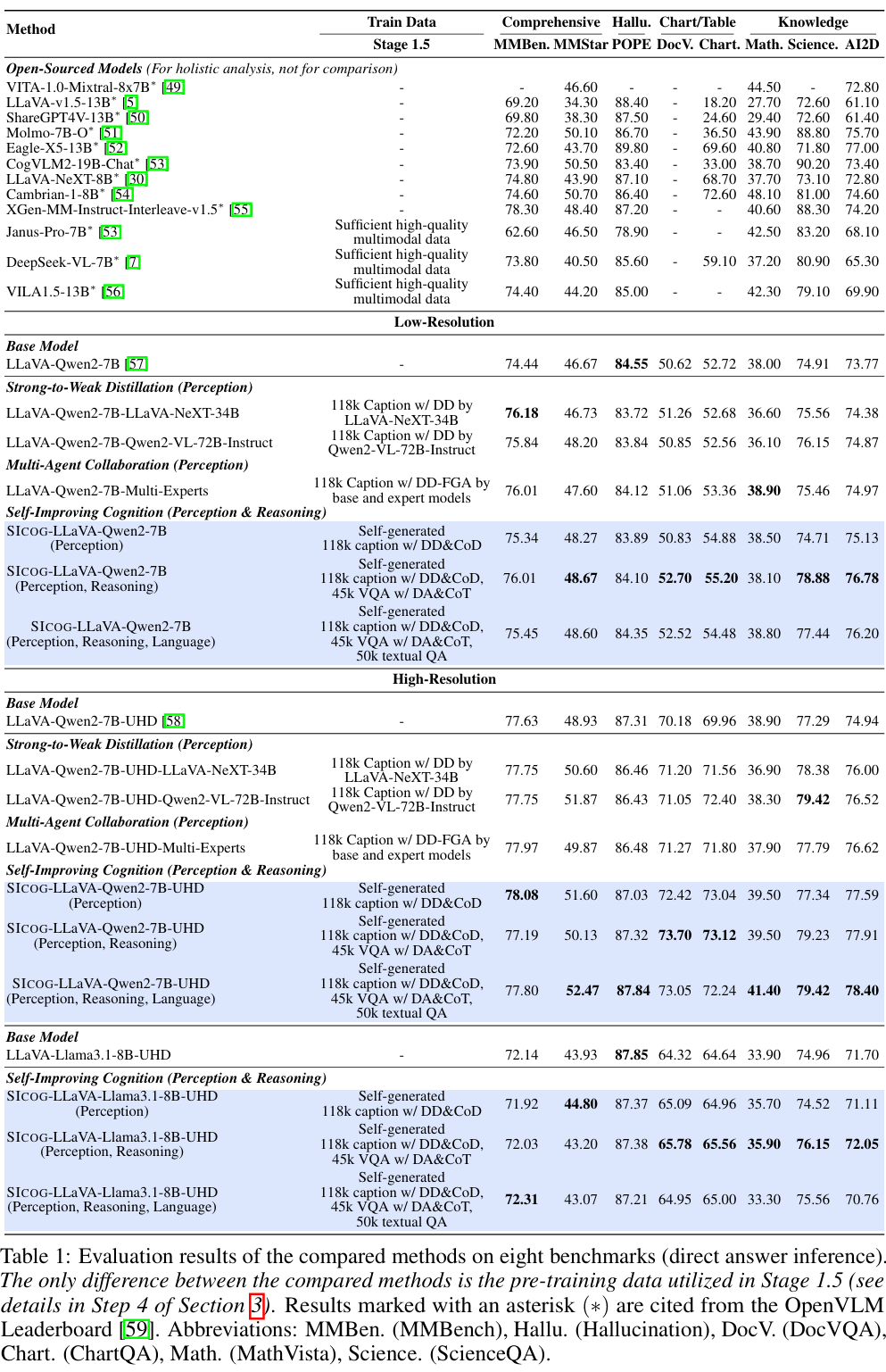
实验还表明,基础模型性能越强,其在自我进化过程中的能力提升也越显著。
例如,LLaVA-Qwen2-7B-UHD 相较于 LLaVA-Llama3.1-8B-UHD,性能提升幅度高出约 50%。
这表明:强大的基础能力不仅决定模型的初始表现,更显著增强其后续自学习与优化能力。
这一现象类似于人类学习中的「马太效应」——「学霸更会自学」。
具备更优初始结构与知识表示的模型,能够更高效地利用数据、激发潜力,在持续进化中取得更大进步。
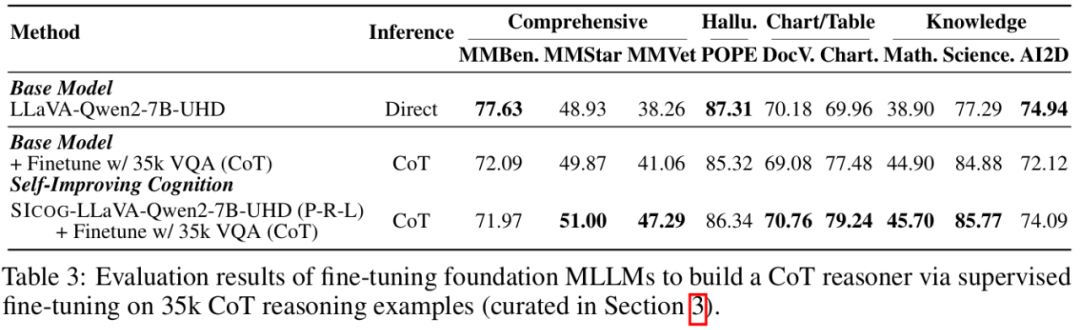
研究进一步表明,基于合成数据的预训练显著提升了模型的基础认知能力,从而强化了后续微调效果。
这一结果再次验证了:预训练、推理阶段的计算扩展与后训练优化三者之间存在高度协同关系。只有打通这三环节,才能实现模型能力的持续跃升与高效进化。
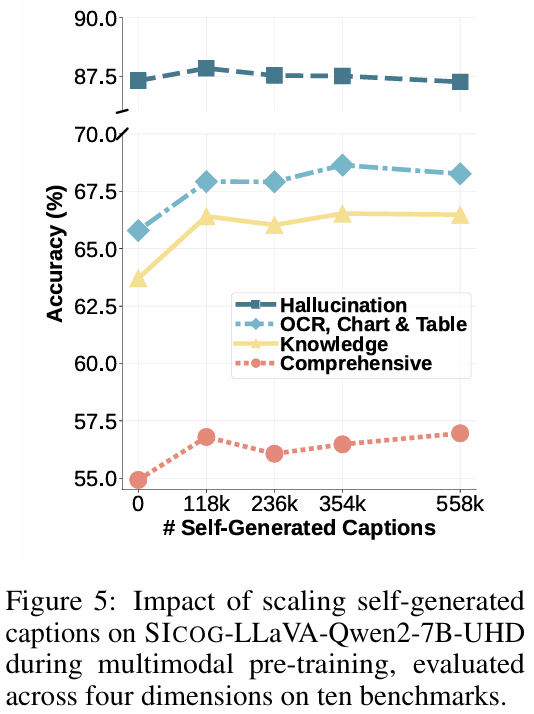
此外,研究发现,SICOG 生成的合成数据同样遵循规模法则(scaling law):模型能力随着数据量的增加持续提升。
这进一步证明了自生成数据在模型进化过程中的有效性与可扩展性。
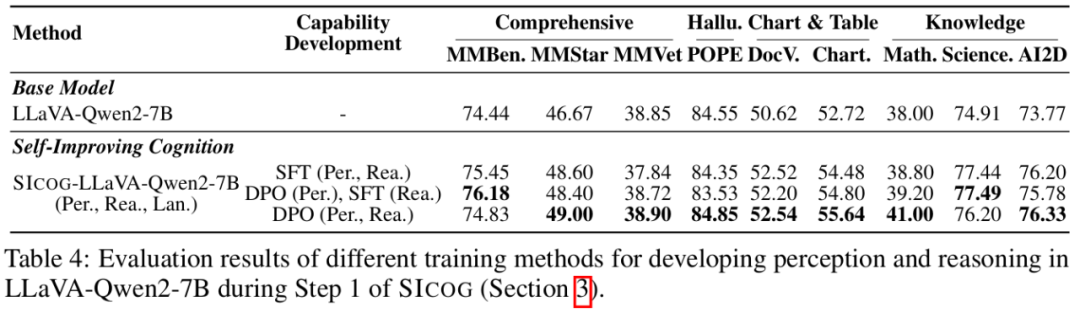
作者提出了一种变体方法:在第一阶段的后训练增强中,以偏好学习(Preference Learning)替代传统的监督微调(SFT),以进一步强化模型的基础能力。
实验结果表明,偏好学习在提升模型泛化能力方面优于 SFT,尤其在处理复杂任务时表现更为稳健。这一结果从实证层面验证了长期以来的观点:
强化学习范式在特定任务中相较于监督微调更具优势。

细粒度图像感知能力显著增强,在细节识别与关系属性捕捉方面表现出更高的准确性与鲁棒性。
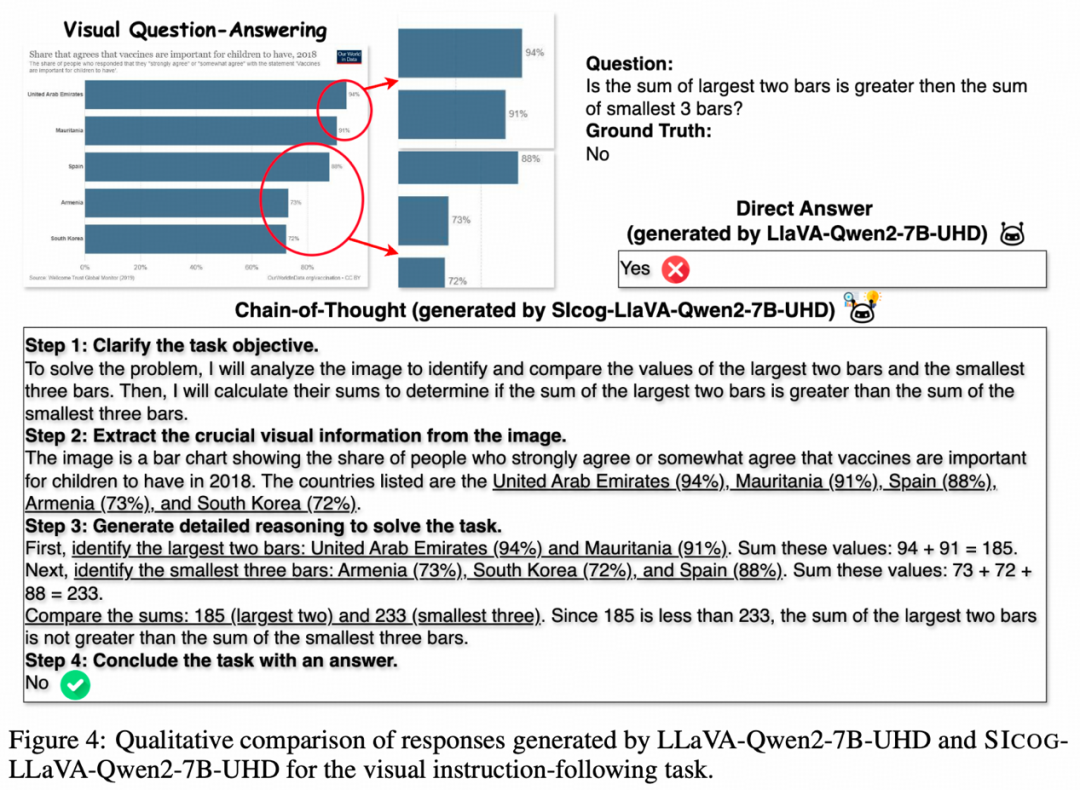
多模态理解与推理能力显著提升。
展望:预训练的新边疆 —— 从静态训练到动态进化
SICOG 通过构建一个涵盖「数据生成 → 模型训练 → 能力进化」的闭环体系,突破了传统预训练对高质量人工标注数据的依赖,展现出类人认知发展的潜力。
该框架不仅实现了模型的自我学习与持续优化,也为迈向真正自主学习型智能体奠定了坚实基础。
在当前研究中,SICOG 通过引入 Chain-of-Description(CoD)并配合 Structured Chain-of-Thought(Structured CoT)的推理机制,
显著增强了多模态模型的感知与推理能力。然而,这一进展仍只是通向完全自主学习的起点。
未来,若能进一步引入环境反馈机制(如具身智能场景)与持续优化机制,模型将有望具备终身学习的能力,实现从「被动学习」向「主动成长」的跃迁。
在与环境的持续交互中,模型不仅可以利用自身生成的数据进行自我优化,
更能够主动识别知识盲区、动态调整学习策略,从而在复杂任务与多变环境中不断进化、持续提升。
文章来自于 “机器之心”,作者 :机器之心




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
