小红书引擎架构团队OSDI 2026新成果:HELMSMAN重塑大规模向量检索基础设施
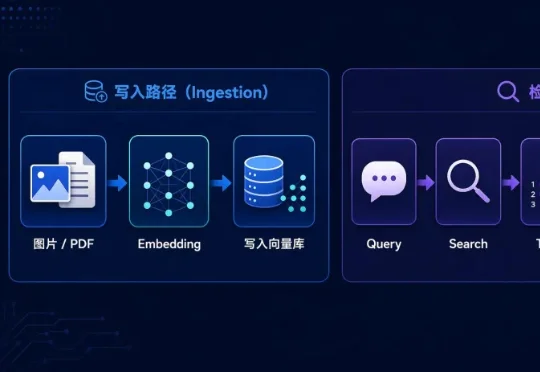
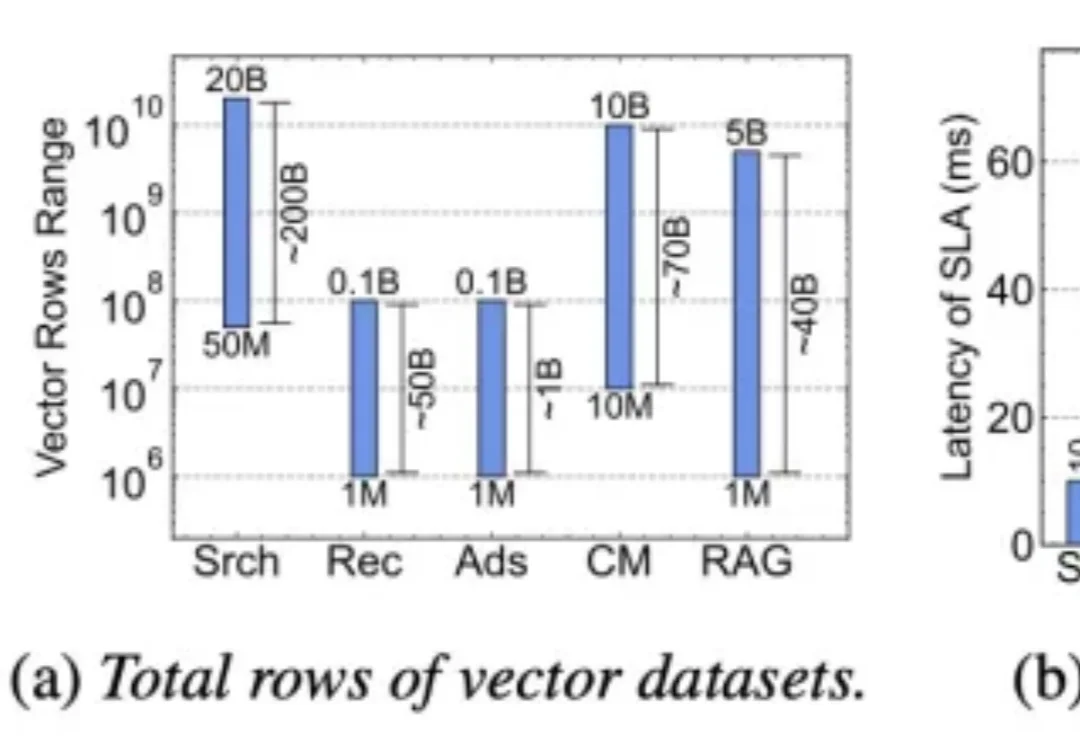
小红书引擎架构团队OSDI 2026新成果:HELMSMAN重塑大规模向量检索基础设施近日,围绕搜索、推荐、广告等核心业务中的大规模向量检索成本与性能问题,小红书引擎架构团队在 OSDI 2026 会议上发表了论文《The Clustering Strikes Back: Building Cost-Effective and High-Performance ANNS at Scale with HELMSMAN》。
来自主题: AI技术研报
9733 点击 2026-07-22 10:35