Struct Array 如何让多向量检索返回完整实体?知识库、电商、视频通用|Milvus Week
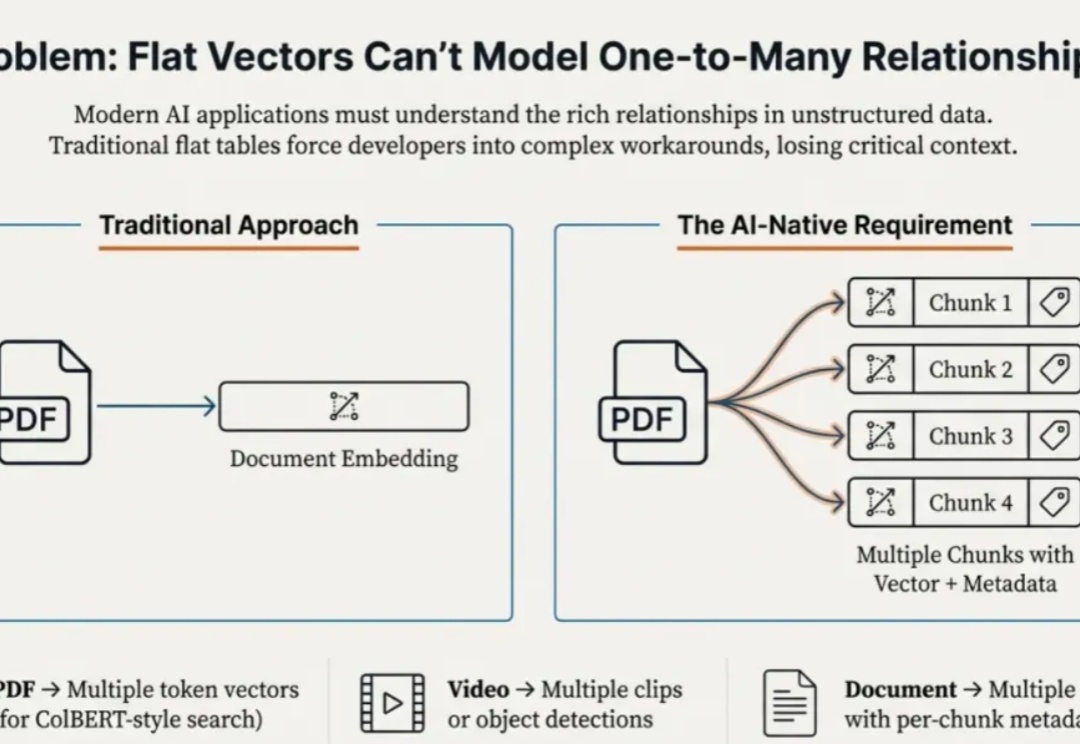
Struct Array 如何让多向量检索返回完整实体?知识库、电商、视频通用|Milvus Week本文为Milvus Week系列第二篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY2内容划重点: Struct Array + MAX_SIM ,能够让数据库看懂 “多向量组成一个实体” 的逻辑,进而原生返回业务要的完整结果
来自主题: AI技术研报
10381 点击 2025-12-03 10:43