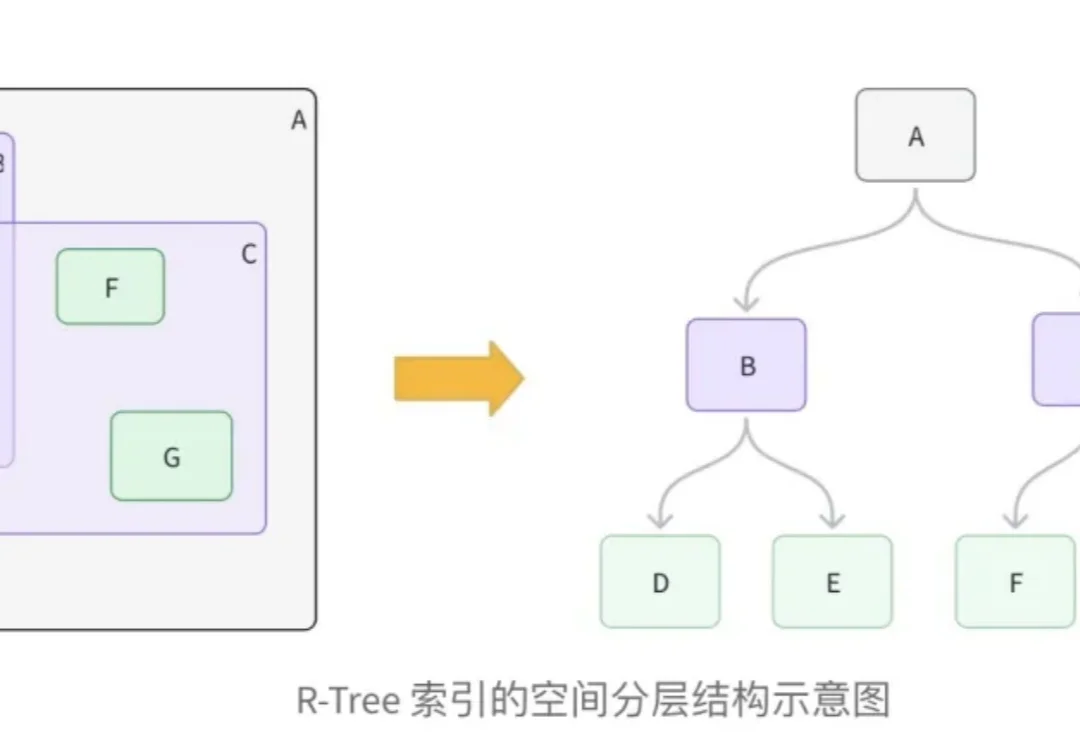
混合检索系列之:Milvus 地理几何字段与 R-Tree 索引技术详解
混合检索系列之:Milvus 地理几何字段与 R-Tree 索引技术详解在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
来自主题: AI技术研报
8581 点击 2026-01-26 10:20
 搜索
搜索
在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
做后端、大数据、分布式存储的同学,大概率都遇到过这样的问题:
故事得从我们那个行业交流群说起。
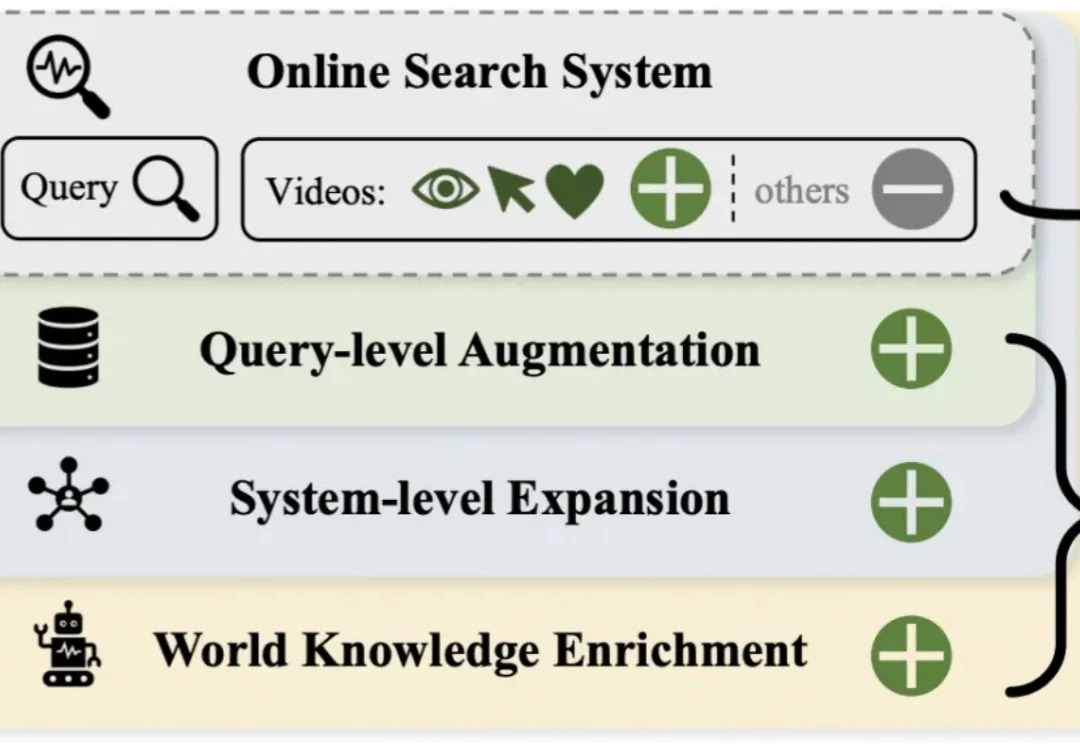
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
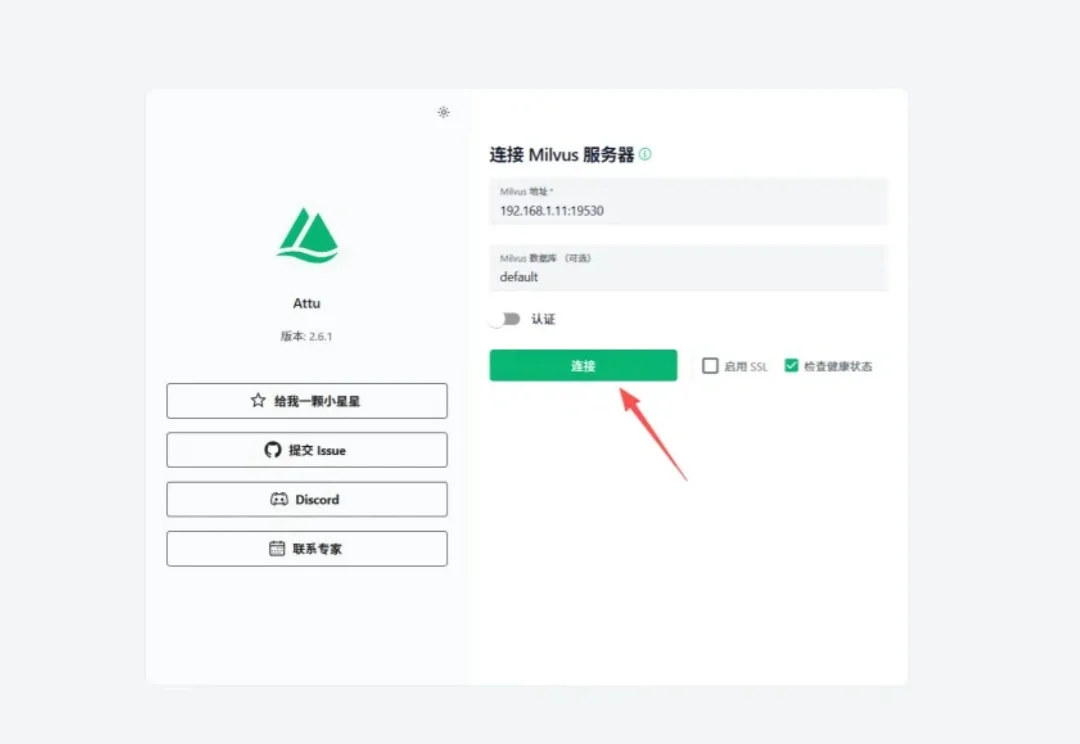
今天在讲Milvus的Attu之前,我们先来唠一段计算机行业的八卦。

不久前,Zilliz 研发VP栾小凡受邀做客英文播客节目Innovator Coffee,深度分享了 Zilliz 的创业历程、Milvus 产品的构建逻辑与核心设计思路,以下为本次分享的重点内容摘编。
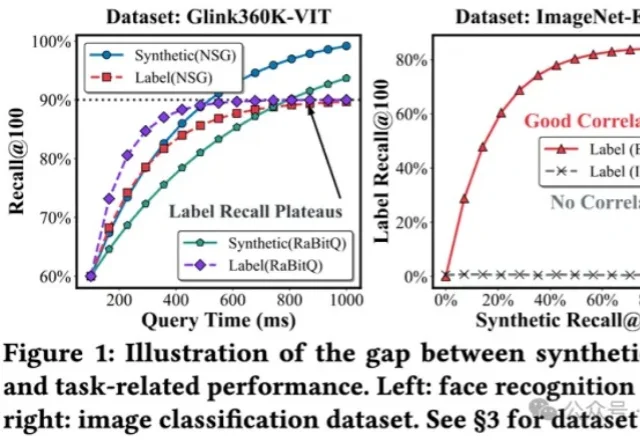
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。
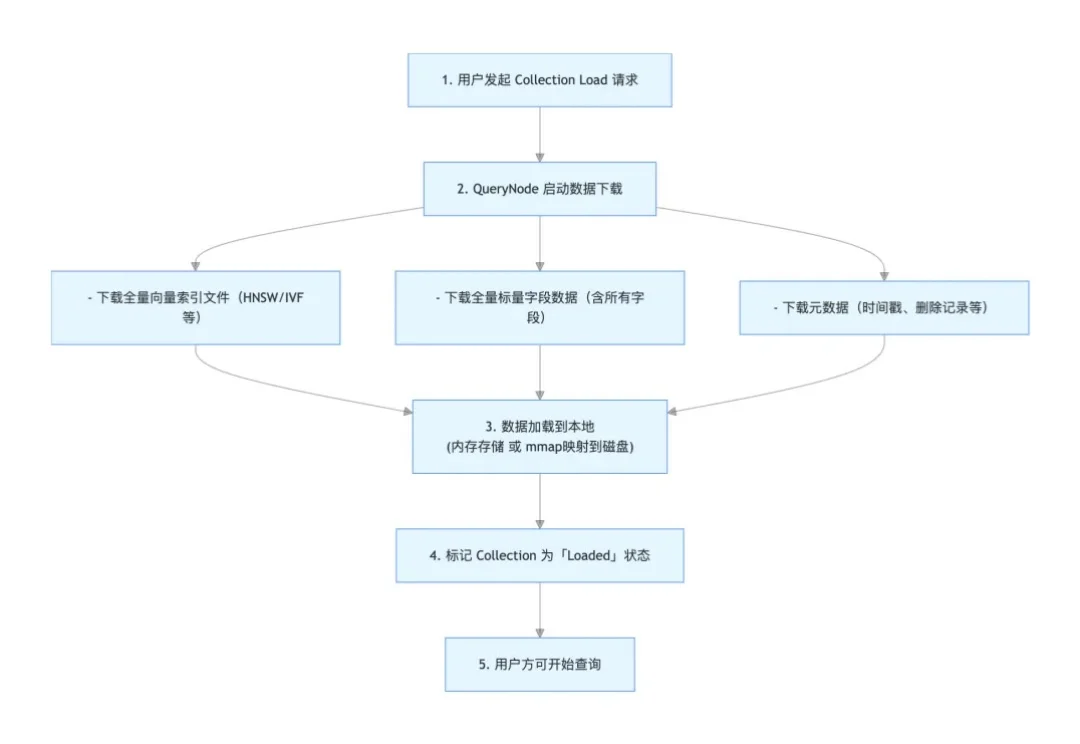
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
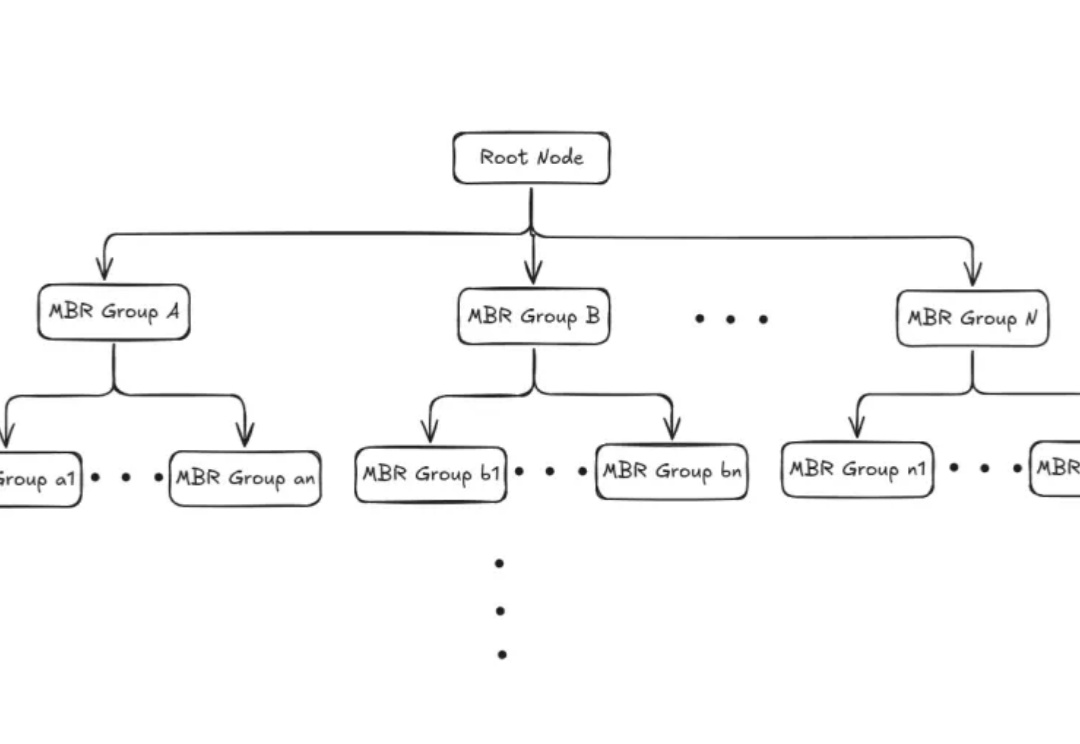
本文为Milvus Week系列第三篇,该系列旨在分享Milvus的创新与实践成果,以下是DAY3内容划重点: Milvus2.6中,Zilliz借助Geolocation Index for Milvus,首次将地理空间数据与向量检索融合,使 AI 可以在理解语义的同时,理解空间。