# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

那些曾在KDD时代Kaggle上打榜刷分的老炮儿,每每提起 Bagging 与 Boosting 这两项技术嘴角都压不住笑。
如果说Ensemble Learning代表了上个时代的机器学习,那么“模型汤” (Model Soups) 就是当下大模型时代的热门:
通过把不同模型调和在一起,从而得到一个效果更佳、表现更稳的新模型。就像做一锅蔬菜汤,把各种不同的食材混合在一起,味道会比单一食材更丰富、更美味。
自 Wortsman 等研究者在 2022 年发表了一系列开创性论文以来:
https://proceedings.mlr.press/v162/wortsman22a.html,神经网络领域也开始拥抱“模型汤”这一思路。
它本质上是一种模型集成(model ensembling)技术,其核心在于将多个独立微调模型的权重进行平均。
通常训练神经网络时,为了追求最佳性能,往往需要在不同数据组合与超参数间进行大量重复实验,计算开销巨大。
模型汤同样也需要使用不同的超参数或训练数据选项,训练出好几个模型,这一点与常规过程没有区别。
其关键在于后续的融合,通过平均这些已训练模型的权重,最终得到的融合模型,通常比单个表现最佳的模型性能更优,也更稳健。
因此,尽管训练多个模型的步骤并未减少,计算成本也没有降低,但“模型汤”能让我们花一样的钱,获得一个更强大、更可靠的模型成果。
目前“模型汤”这套方法,无论是在图文多模态向量模型(text-image multimodal embedding models,Wortsman 等人,2022),
还是生成式大语言模型(generative large language models,Takuya 等人,2025)等领域,都已经被证明是行之有效的。
在 Jina AI,我们也已经开始运用这项技术来训练自家的模型了,例如 jina-embeddings-v3 和 ReaderLM-v2 这两个模型,就都融入了“模型汤”的策略。
在本文中,我们将深入探讨“模型汤”技术,并展示我们在这方面的一些实践成果。具体来说,我们想弄清楚以下几个核心问题:
1.融合不同训练阶段的模型,能否来提升模型性能?
2.融合针对不同数据集训练、或面向不同任务训练的模型,想较于训练一个大而全的通用模型,是否效果更优更高效?
这里要是搞清楚了,应用潜力非常大:
如果我们能先针对每个特定任务或数据集,都单独训练出最好的模型,然后再把它们平等地组合起来,这会是一个巨大的进步。
我们可以模块化地调整模型,一次只更新一个组分模型(component model),然后再将其与其他模型重新融合。
说起来,把多个模型的输出结果整合起来,在统计决策理论(statistical decision theory)里算是个经典老办法了。
在天气预报领域,业内的普遍做法就是创建多个预测模型,这些模型往往由不同团队基于不同的假设构建,然后采用各种机制来对这些模型的预测结果进行平均。
其背后的逻辑是:如果每个模型产生的误差是随机分布的,那么将这些模型进行平均,最终得到的答案出错的可能性就会更小。
假设你有三个模型,它们都只输出“是”或“否”这样的二元结果。
如果每个模型单独判断时,有 10% 的概率会出错,那么三个模型里有两个同时出错的概率,就会降低到只有 2.8%。
如果增加到五个模型,并且采用多数表决的原则,那么它们集体出错的概率更是能降到 0.856%。
“模型平均”(Model Averaging)的原理和这个类似,但它融合的不是各个模型的输出结果,而是模型本身,也就是模型的参数。
我们这里讨论的方法,是随机权重平均(Stochastic Weight Averaging, 简称 SWA,由 Izmailov 等人在 2018 年提出)技术的一种扩展。
SWA 的核心思路,源于对神经网络“损失景观”(loss landscape)的理解。你可以把它想象成一个有很多山谷和洼地的地形图,模型训练的过程就是在寻找最低点。
SWA 的研究表明,在许多常见情况下,简单粗暴地对模型的权重进行平均,就能提升模型的泛化性能,也就是模型在未见过的新数据上的表现能力。
那么,具体怎么平均这些模型呢?操作方法简单到可能让你有点不敢相信:你只需要把多个模型的权重(weights)直接加起来求个平均就行了。

上图就是一个将不同模型融合成“模型汤”的简化示例。这个例子虽然画得很简单,但清楚地展示了核心步骤:
将各个模型的权重相加,然后除以参与合并的模型的数量。
如果这听起来太容易了,那你可要注意了:用这种方式合并模型其实是有门槛的。并不是随便抓两个神经网络,把它们的权重一平均就能成功的。
模型平均通常只对那些非常相似的模型才有效,也就是说,这些模型的权重本身在一开始就不能有太大的差异。
那怎么保证这一点呢?常见的做法是:先预训练一个基础模型,然后基于这个模型,通过使用不同的超参数或不同的数据进行微调,从而创建出多个变体。
这样得到的模型,它们之间的相似度通常就足够高,拿来做平均的效果也就比较好。
用更技术的语言来说,预训练过程通常会使模型的权重收敛到某个“损失盆地”(loss basin)的底部附近。
你可以把这个盆地理解为模型参数空间中一个误差值较低的稳定区域。而后续的微调过程,一般不太容易让模型跳出这个它已经陷入的“损失盆地”。
因此,如果要合并的所有模型,它们的权重都处在同一个“损失盆地”内,那么它们的权重值本身就会相当接近,此时对它们进行平均,成功的可能性就比较大。
当然,这也不是百分百打包票的,但从实际经验来看,这个方法相当管用。
在接下来的实验里,我们选用了 FacebookAI 开源的 xlm-roberta-base (Conneau 等人, 2020 年) 作为我们的预训练基础模型。
这个 2.8 亿参数的模型,是在一个包含了大约 100 种语言、2.5TB 大小的 Common Crawl 数据集上预训练得到的。
在正式动手实验之前,我们还特意用自己精心整理的句子对(sentence pair)训练集,对xlm-roberta-base 进行了微调,主要是为了训练模型的向量表示能力。
2. 训练数据
我们 Jina AI 维护者一套专门用于训练的数据集。在第一个实验中,我们使用了专门为对比学习准备的句子三元组,这些数据覆盖了六种语言:
英语、阿拉伯语、德语、西班牙语、日语和中文。在第二个实验中,我们使用的是针对特定任务的英文训练数据集。
3. 评估方法
我们使用了 MMTEB 基准测试集 (Enevoldsen 等人, 2025 年) 和 MIRACL 基准测试集 (Zhang 等人, 2023 年) 中的相关部分,
来评估我们通过训练和融合得到的模型的性能。
在这个实验中,我们将前面提到的六种语言的对比学习句子三元组混合在一起进行训练,
总共训练了 6000 个训练步(training steps),每个批次的大小(batch size)为 1024 个样本。
在训练过程中,每隔 2000 步,我们就保存一次模型的当前状态(也称为模型快照,checkpoint),留着后面做平均用。
这样一来,我们就得到了 3 个模型,分别反映了训练过程中的不同阶段。
然后,我们将这三个模型进行平均,生成一个最终的融合模型。
接着,我们使用 MMTEB-STS 和 MIRACL 这两个基准测试集,分别对这个融合模型以及之前保存的三个模型快照进行了性能测试。
我们的实验结果汇总在下表中:
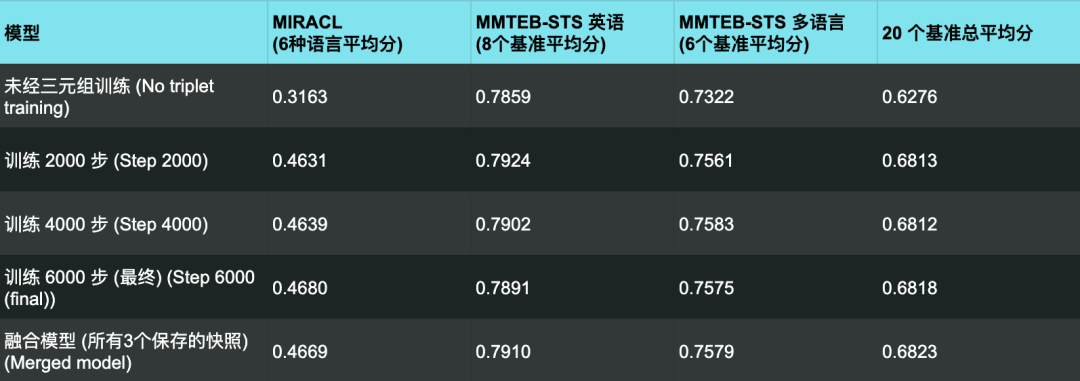
从结果来看,要是比较单个的基准测试,融合模型并没有快照里最好的那个模型好。
但是,如果我们把所有基准测试的得分都综合起来看平均值,那融合模型反而是表现最抢眼的那个。
而且具体到每一个单独的基准测试,融合模型和表现最好的那个快照之间的性能差距,基本上都小到可以忽略不计(小于 0.01)。
这不光是对上面表格里的平均分成立,对每一项单独的测试结果也都一样。
这就说明,通过融合不同训练阶段的检查点,我们能用非常小的性能代价,换来一个更加稳健的模型。
而且,通过融合不同阶段的检查点,我们还能有效地防止模型出现过拟合(overtraining)。
过拟合是近年来神经网络圈子里的热门话题 (Springer 等人, 2025 年, https://arxiv.org/abs/2503.19206v2)。
有时候,模型训练过度,反而会导致其在后续的微调中变得更难处理,性能甚至不升反降。
在咱们的实验里,表现最好的那个检查点,往往并不是训练到最后的那个。
这很可能就意味着,我们的模型在训练到 6000 步的时候,已经有那么点儿过拟合的苗头了。
而融合得到的模型,在所有测试中的表现都跟最好的那个检查点非常接近,这就在一定程度上把过拟合带来的那些负面影响给消除了。
在这个实验中,我们针对三种常见的向量化任务,分别训练了三个模型:
想一次性训练出一个能同时胜任这三个任务的模型是相当困难的,因为这些任务的目标差异很大。我们希望“模型汤”技术能够改善这一局面。
根据我们以往的经验,这三种任务需要的训练轮次(epochs)是不同的,具体的训练设置总结如下:

这样,我们得到了三个分别针对不同任务训练的模型。然后,我们将它们融合成一个单一的模型。
我们使用 MMTEB 基准测试集中与这三个任务相关的部分,
即 MIRACL、NanoBEIR 和 STSEval(包括 MMTEB 的英语和多语言部分)来评估这个融合模型的性能。
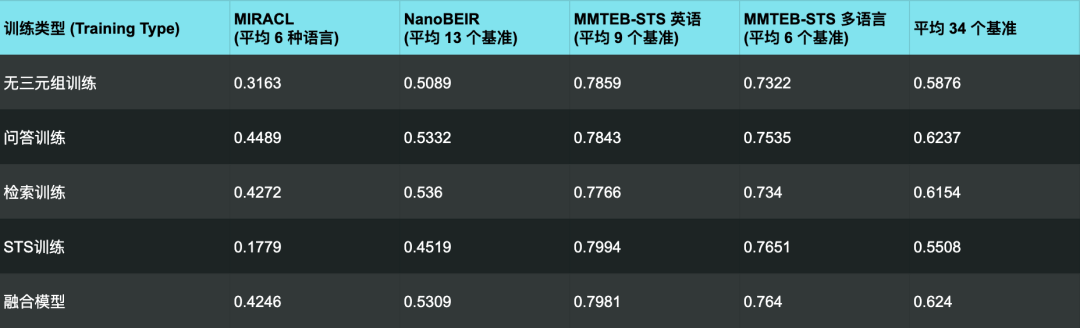
从这里我们可以看到,那些专门为特定任务训练的模型,在它们各自擅长的领域里表现是最好的。
MIRACL 主要是考量问答能力的,所以专门为 QA 训练的那个模型在它上面的表现,把其他所有模型(包括融合模型)都甩在了后面。
NanoBEIR 是一个传统的信息检索基准测试集,我们可以看到专门为检索训练的那个模型在它上面表现最优。
而那个专门搞语义相似度 (STS) 的模型呢,在前面这两个基准上的得分就相当低了,但在专门考查 STS 能力的任务上,它又能把其他模型比下去。
总的来说,对于每个特定的任务类别,融合模型的表现都不如那些专门为该任务训练的单一模型。
但是,如果我们再次把眼光放到所有基准测试的平均得分上,那融合模型又一次表现更优。
虽然它的总分只比专门为 QA 训练的那个模型高了那么一丢丢,而且它在 STS 任务上的表现也确实不怎么样。
我们还试了另外一种做法:只把 QA 模型和检索模型这两个拿来融合,然后用同样的基准来评估这个新出炉的模型的性能:
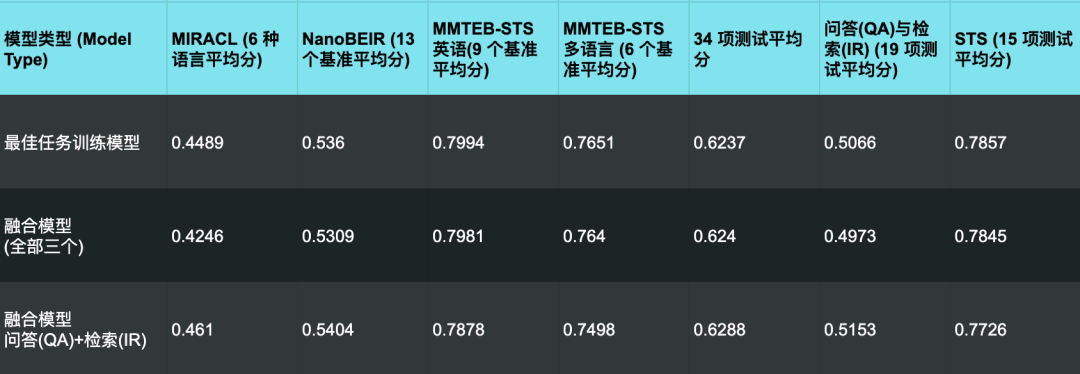
从这里的结果来看,虽然把专门为问答任务和检索任务训练的模型融合起来,确实能让它们在这两个任务上的综合表现都有所提升,
但是,一旦把那个为语义相似度(STS)训练的模型也加进来,反而会在所有任务类别上都把特定任务的性能给拉低了。
这就说明,语义相似度这个任务,在某些很重要的方面,跟问答和检索任务确实不太一样,因此为 STS 训练的模型不适合与其他两种任务的模型进行融合。
这背后的原因很可能是:问答和检索任务,通常都涉及到把比较短的文本(比如问题和查询语句)跟比较长的文档进行匹配;
而语义相似度任务呢,则更侧重于比较那些长度更为接近的文档。
Wortsman 等人在 2022 年还提出了一种被他们称为“贪婪”融合(greedy merging)的选择性平均方法:https://proceedings.mlr.press/v162/wortsman22a.html。
这种方法的具体做法大致是:先挑一个模型(通常是一组模型里表现最好的那个),然后只把那些加进来之后能让整体性能实打实提升的模型,才逐个地跟它融合。
因为我们这个实验里总共就三个模型,所以用不用“贪婪”融合其实意义不大。
但是,我们可以想象,如果手头有更多的模型,那就可以利用类似这样的技术来判断不同任务之间的相似程度了。
比如,在这次实验里,我们就发现语义相似度任务跟另外两个任务确实不太一样。
基于这类发现,我们就能进一步评估,到底在什么情况下让一个模型去处理多个任务是划算的,又在什么情况下用不同的专用模型性价比更高。
“模型汤”的妙处在于其“1+1>2”的融合效应,它能够在不增加额外训练成本的前提下,让模型表现得更稳定、更可靠,并且还能有效防止模型过拟合。
我们的实验结果也证明了,
无论是合并不同训练阶段的检查点,还是融合针对特定任务训练的模型,都能够提升模型的整体性能,即便有时会牺牲掉在某些特定任务上的峰值表现。
总而言之,“模型汤”为我们提供了一种实用且操作异常简单的方法,来构建适应性更强的模型。
当然,它也不是万能,而且只适用于那些本身已经非常相似的模型。具体效果因场景而异,但好在实践起来门槛很低,既不费钱也不费事,何乐而不为呢?
文章来自于微信公众号 “Jina Al”,作者 :Jina Al




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
