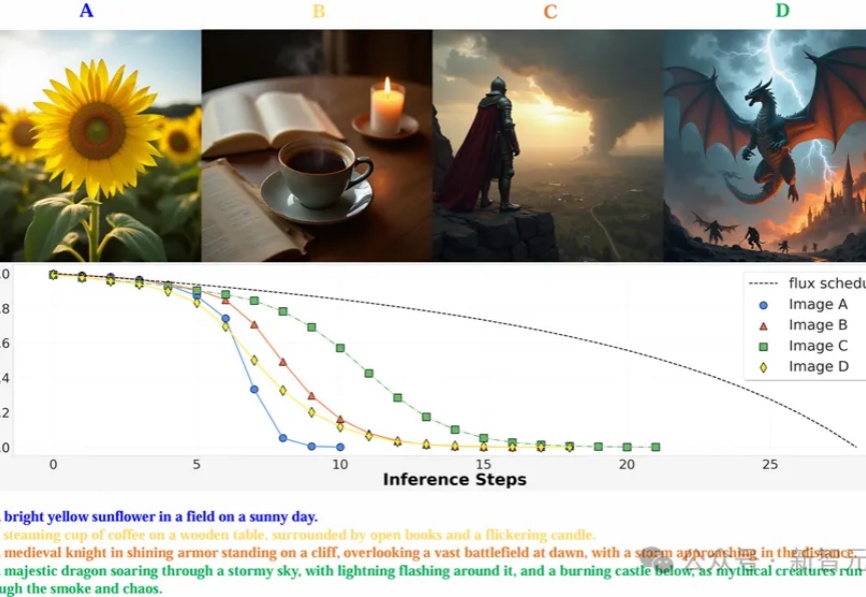
终于等来能塞进手机的文生图模型!十分之一体量,SnapGen实现百分百的效果
终于等来能塞进手机的文生图模型!十分之一体量,SnapGen实现百分百的效果近些年来,以 Stable Diffusion 为代表的扩散模型为文生图(T2I)任务树立了新的标准,PixArt,LUMINA,Hunyuan-DiT 以及 Sana 等工作进一步提高了图像生成的质量和效率。然而,目前的这些文生图(T2I)扩散模型受限于模型尺寸和运行时间,仍然很难直接部署到移动设备上。
来自主题: AI技术研报
9329 点击 2024-12-25 14:02