# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
基于人工智能的数字内容生成,即 AIGC 在二维图像生成领域取得了很大的成功,但在三维生成方面仍存在挑战。智能化生成三维模型在 AR/VR、工业设计、建筑设计和游戏影视等方面都有应用价值,现有的智能化三维生成方法已经可以生成高质量的三维模型,但如何对生成结果进行精确控制,并对真实模型或生成的模型进行细节的修改,从而让用户自由定制高质量的三维模型仍然是一个待解决的问题。
近期,一篇题为《SketchDream: Sketch-based Text-to-3D Generation and Editing》的论文提出了基于线稿和文本的三维内容生成和编辑方法 SketchDream [1],论文发表在 SIGGRAPH 2024,并被收录于图形学顶级期刊 ACM Transactions on Graphics。这个 3D AIGC 工作助你成为神笔马良,通过画笔画出三维世界,已入选 SIGGRAPH 精选亮点工作宣传片。

使用该系统,即使用户不会使用复杂的三维软件,也可以基于线稿自由创作三维内容,并对真实的模型进行修改和编辑。先来看看使用 SketchDream 创作的模型的效果:

图 1 基于 SketchDream 的三维生成效果
背景
最近,AI 绘画非常火爆,基于 Stable Diffusion [2] 和 ControlNet [3] 等方法,通过指定文本可以生成高真实感的二维图像。最新的视频生成方法 Sora [4],已经可以基于文本生成高质量影视级的视频。但是,上述工作无法直接生成高质量的三维模型,更无法对现有的三维模型进行编辑和修改。
针对上述问题,DreamFusion [5] 提出了 Score Distillation Sampling (SDS) 的方法,利用二维图像的 Diffusion model 生成模型优化神经辐射场,基于文本合成任意类别的高质量的三维模型。后续一系列工作 [6][7][8] 对该方法进行了改进,提升了生成的三维模型的质量,并使生成的过程更加稳定。但是,仅仅基于文本,难以实现对几何细节的控制,例如物体的形状和轮廓,不同的组件的形状和位置等。为了提高可控性,许多方法 [9][10] 使用额外的图像作为输入,生成高质量的模型,但用户依然需要提前获取合适的图像。
除了三维内容生成,如何对已有的三维模型进行再创作,即对真实的三维模型进行修改和编辑也是非常重要的问题。Vox-e [11] 和 DreamEditor [12] 根据文本自适应的确定三维编辑区域,再实现基于文本的编辑效果。为了实现更精细的控制,SKED [13] 使用线稿编辑三维模型,但如何处理复杂编辑情景仍然较为困难。
线稿作为一种用户友好的交互方法,被广泛用于三维建模。艺术家们通常会先绘制物体的线稿,再进一步使用专业软件进行建模。然而,直接使用线稿生成高质量的三维物体存在下述挑战:首先,线稿风格多样且过于稀疏,很难使用单视角的线稿约束三维物体的生成;其次,二维线稿只包含了单视角的信息,如何解决歧义性,生成侧面和背面区域较为困难。基于线稿的模型编辑则更具挑战性,如何分析并处理不同组件的关系,如何保证编辑区域的生成质量,如何保持非编辑区域不变,都是需要解决的问题。
SketchDream 算法原理

图 3 SketchDream 的网络架构图,生成和编辑流程
基于线稿的多视角图像生成网络
给定单视角的手绘线稿后,仅在线稿对应的视角添加约束,无法生成合理的三维模型。因此,需要将线稿的信息有效地传播到三维空间中的新视角,从而合成与线稿对应的高质量的模型。SketchDream 算法构建了基于线稿的多视角图像生成的扩散模型。具体而言,算法在多视角图像生成网络 MVDream [8] 的基础上,添加了与 ControlNet 结构类似的控制网络,基于线稿控制多视角图像的特征。网络使用了 3D Self-Attention,在不同视角之间共享 Q,K,V 特征,从而生成三维一致的结果。
直接使用单视角二维线稿作为多视角图像控制网络的输入,由于缺乏三维信息和空间对应,难以实现有效的线稿控制。因此,算法使用扩散模型生成线稿对应的深度图,补充稀疏线稿缺失的几何信息。进一步,基于深度对线稿变形,从而将线稿显式地变换到相邻的新视角,其他视角则直接输入空白图像。尽管其他视角输入了空白图像,但 3D Self-Attention 保证了视角间的信息交换,从而实现对多视角图像的有效控制。
基于线稿的三维生成
为了实现高质量的三维生成,算法基于线稿的多视角图像扩散模型,反向优化神经辐射场。优化过程中,每一个迭代的步骤,使用不同的相机参数渲染模型并计算梯度,反向优化三维模型。算法基于多视角图像生成网络计算 SDS Loss,保证三维模型的几何合理性。并且,为了提升纹理细节的质量,算法基于 2D 的图像生成网络,计算 ISM Loss [14],提高模型生成质量。算法额外添加蒙版约束和正则化项,提高线稿的对应性和模型的合理性。
基于线稿的三维编辑
为了实现精细化的编辑,算法提出了两阶段编辑方法:粗粒度编辑阶段,算法分析组件的交互关系,生成初始的编辑结果,并基于此获取更精确的三维蒙版;细粒度编辑阶段,算法对局部编辑区域进行渲染优化,并保持非编辑区域的特征,实现高质量的局部编辑效果。
具体而言,在粗粒度编辑阶段,将手绘的 2D 蒙版转换为 3D 空间中的圆柱网格模型,粗略标记编辑的区域。优化过程中,使用与生成相同的损失函数进行优化,但在非编辑区域额外添加与原始模型的 L2 损失,保持原始模型的特征。进一步,从粗略编辑的 NeRF 结果中提取网格模型,标记 3D 网格的局部区域表示待编辑的区域,获取精细化的 3D 蒙版。在细粒度编辑阶段,为了提升编辑区域的质量,算法对局部编辑区域进行渲染,添加基于线稿的 SDS 约束,并添加更精细的非编辑区域的约束,生成更高质量的编辑效果。
效果展示
如图 4 所示,给定手绘线稿和文本描述,该方法可以生成高质量的三维模型。算法生成的结果没有类别限制,结果具备合理的几何属性和高质量的纹理属性。用户可以自由变换视角,都能得到非常真实的渲染结果。

图 4 基于线稿生成的三维模型
如图 5 所示,给定真实的三维模型,用户可以选择任意的视角,对渲染出的线稿进行修改,从而编辑三维模型。该方法可以对已有模型的部件进行替换,例如左侧的修改狮子头部、更换裙子等,也可以添加新的部件,例如右侧的添加新的房间、添加翅膀等。

图 5 基于线稿的三维模型编辑结果
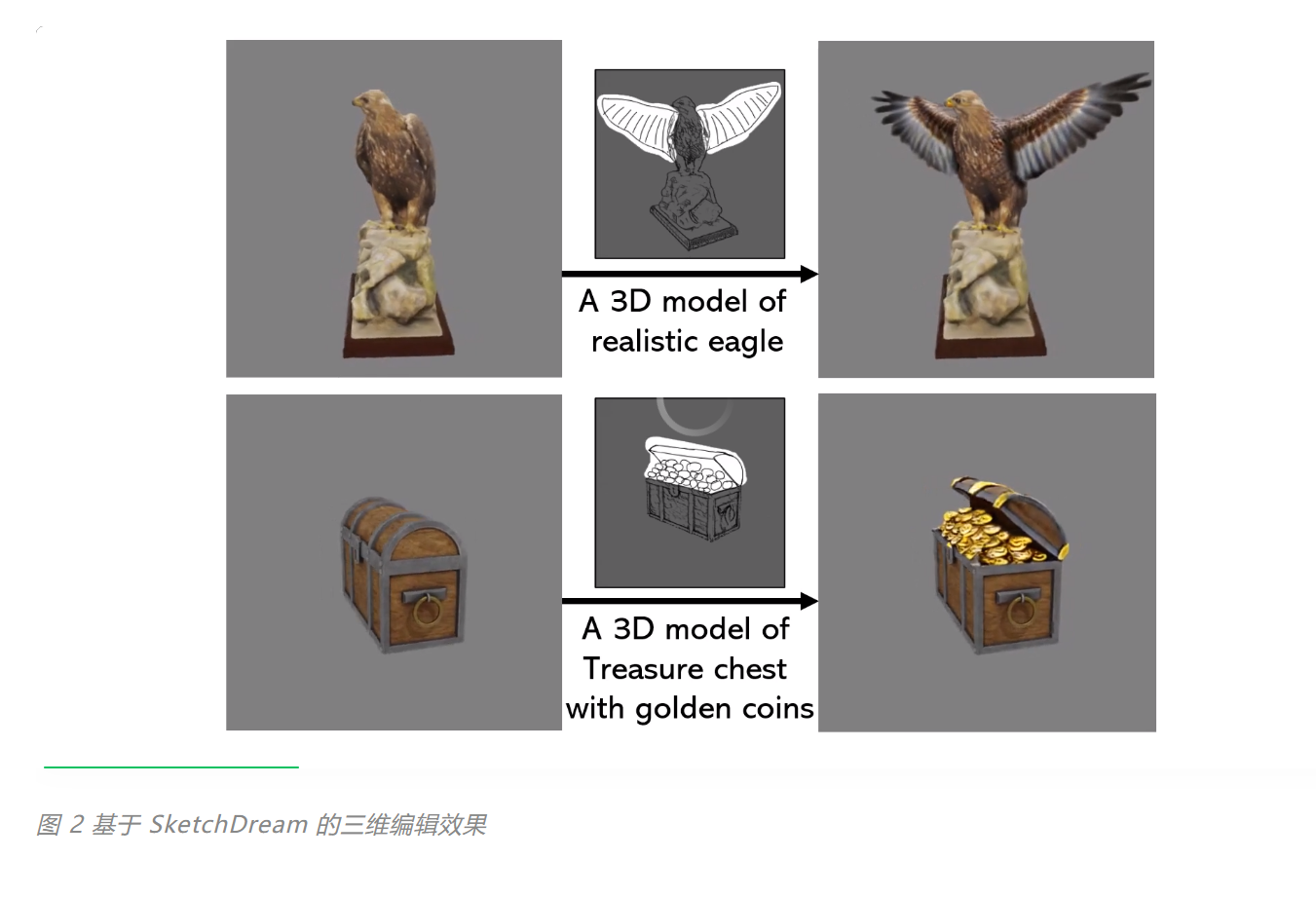
如图 6 所示,给定线稿和文本描述,该方法可以对应的三维模型。进一步,用户可以旋转到新的视角,对局部区域进行修改,实现三维模型的精细化定制。
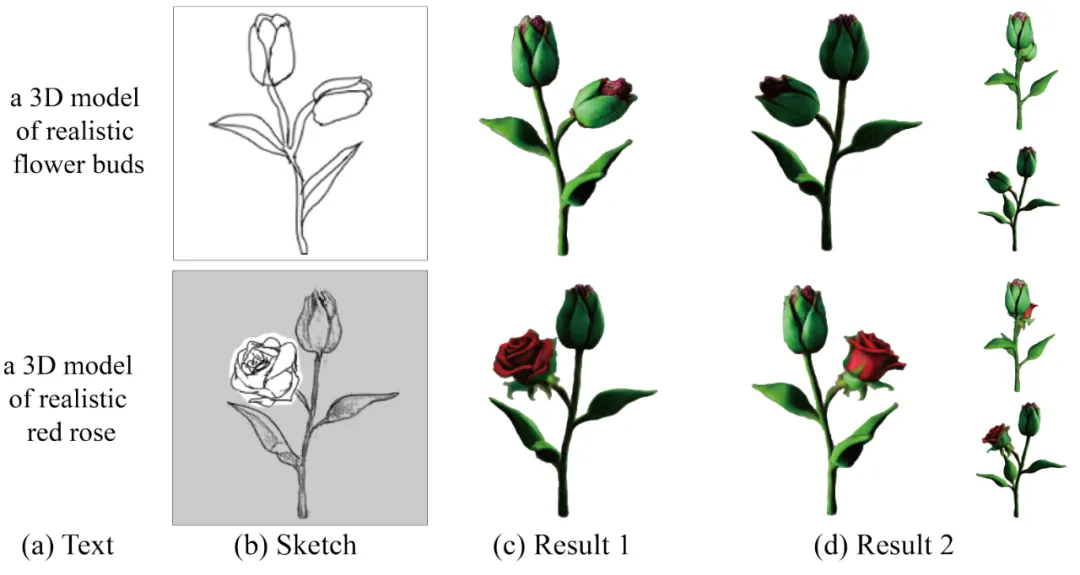
图 6 基于线稿的生成和编辑效果
如图 7 所示,针对同一个三维模型,用户可以绘制不同的线稿,从而生成具备多样性的结果。线稿也实现了较为精细化的控制,实现了对鸵鸟不同颈部姿态的控制效果。
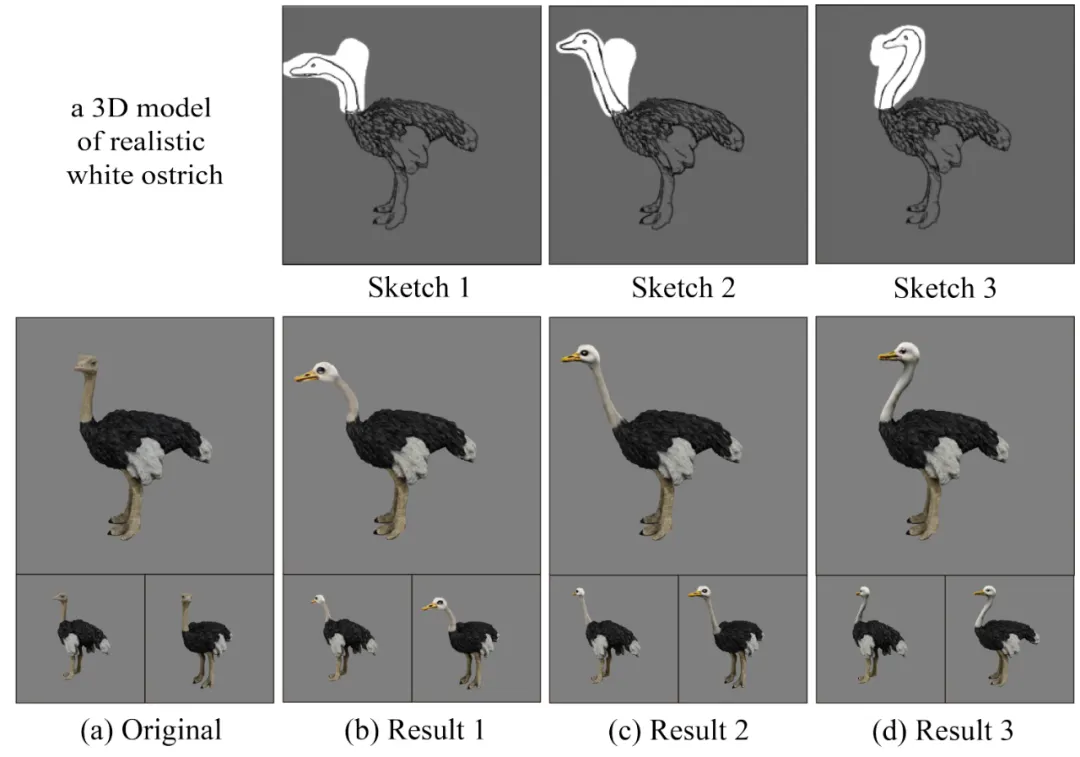
图 7 基于线稿的多样化的编辑效果
如图 8 所示,针对同一个三维模型,用户可以指定不同的文本,从而生成具备纹理多样性的结果。在给定相同线稿的情况下,可以生成黄金、铜制和石头质感的狮子头,并保持其他区域不变。

图 8 基于文本的多样化的编辑效果
结语
基于人工智能的数字内容生成技术蓬勃发展,在很多领域已经有广泛的应用。针对三维内容生成,除了保证高真实感的生成质量,如何提高用户的可控性是重要的问题。SketchDream 提供了一种可行的解决方案,基于手绘线稿,用户可以生成高质量的三维模型,并支持对真实模型的可控编辑。
基于该系统,我们无需安装繁杂的三维建模软件并学习复杂的技能,也不需要花费数个小时时间精力,仅仅通过勾勒简单的线条,普通用户也能轻松构建心中完美的三维模型,并得到高质量的渲染结果。SketchDream 已经被 ACM SIGGRAPH 2024 接收,并将刊登在期刊 ACM Transactions on Graphics 上,已入选 SIGGRAPH 精选亮点工作宣传片。
文章来源于“机器之心”



