![10秒生成4K图像,细节堪比摄影:FLUX1.1 [Pro] 的Ultra/Raw模式震撼发布](https://www.aitntnews.com/pictures/2024/11/11/caa5aef4-9fd4-11ef-8bd0-fa163e4b35c9.png)
10秒生成4K图像,细节堪比摄影:FLUX1.1 [Pro] 的Ultra/Raw模式震撼发布
10秒生成4K图像,细节堪比摄影:FLUX1.1 [Pro] 的Ultra/Raw模式震撼发布黑森林实验室(Black Forest Labs)最近推出了FLUX1.1 [pro]的Ultra模式和Raw模式,为图像生成工具带来突破性升级,让创作者在AI生成图像领域有了前所未有的选择。
来自主题: AI资讯
5801 点击 2024-11-11 10:31
 搜索
搜索
黑森林实验室(Black Forest Labs)最近推出了FLUX1.1 [pro]的Ultra模式和Raw模式,为图像生成工具带来突破性升级,让创作者在AI生成图像领域有了前所未有的选择。
最近,一个名叫 Osmo 的初创公司宣布,他们成功地将气味数字化了。第一个成功的案例是「新鲜的夏季李子」,而且复现出的味道「闻起来」很不错。整个过程依靠 AI 技术来完成,不需要人工干预。有了这项技术,你就可以像下载音乐一样下载香水了。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。

MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。

多模态模型,统一图像生成。

LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!
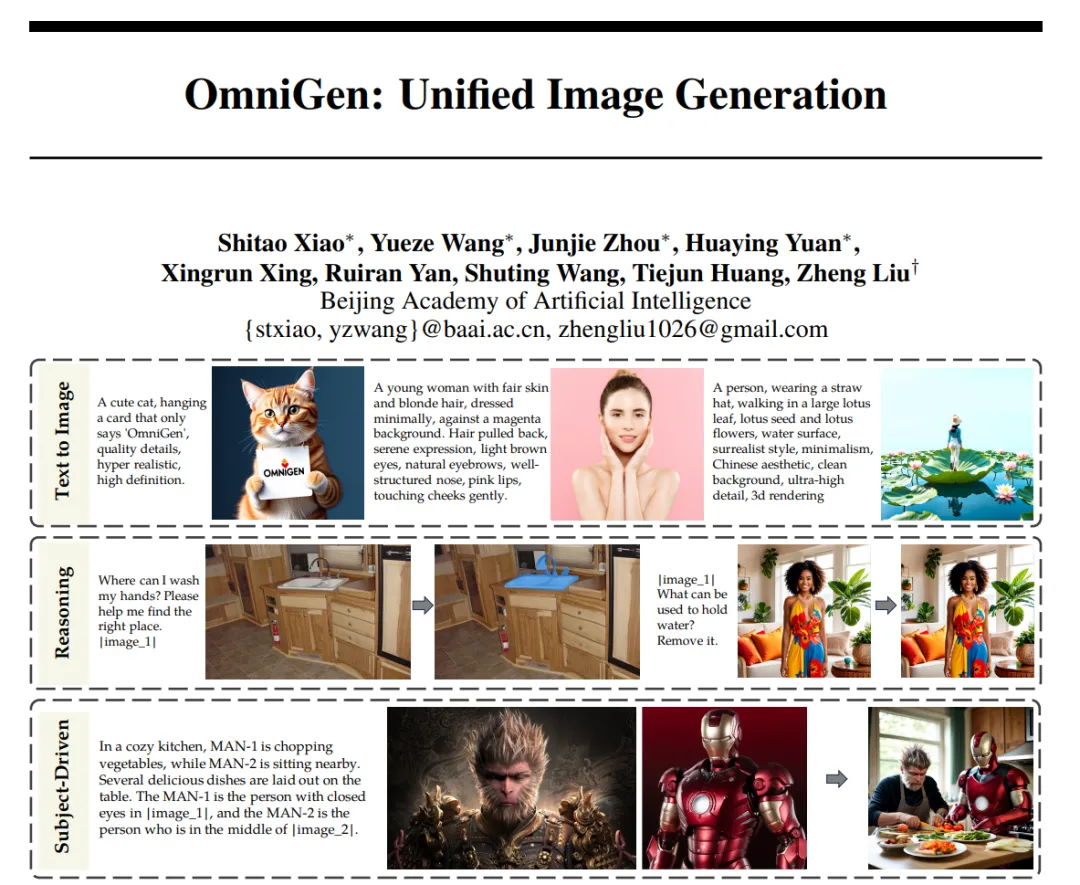
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

扩散模型(Diffusion Models, DMs)已经成为文本到图像生成领域的核心技术之一。凭借其卓越的性能,这些模型可以生成高质量的图像,广泛应用于各类创作场景,如艺术设计、广告生成等。

一台4090笔记本,秒生1K质量高清图。英伟达联合MIT清华团队提出的Sana架构,得益于核心架构创新,具备了惊人的图像生成速度,而且最高能实现4k分辨率。

自去年以来,文本到图像生成模型取得了巨大进展,模型的架构从传统的基于UNet逐渐转变为基于Transformer的模型。