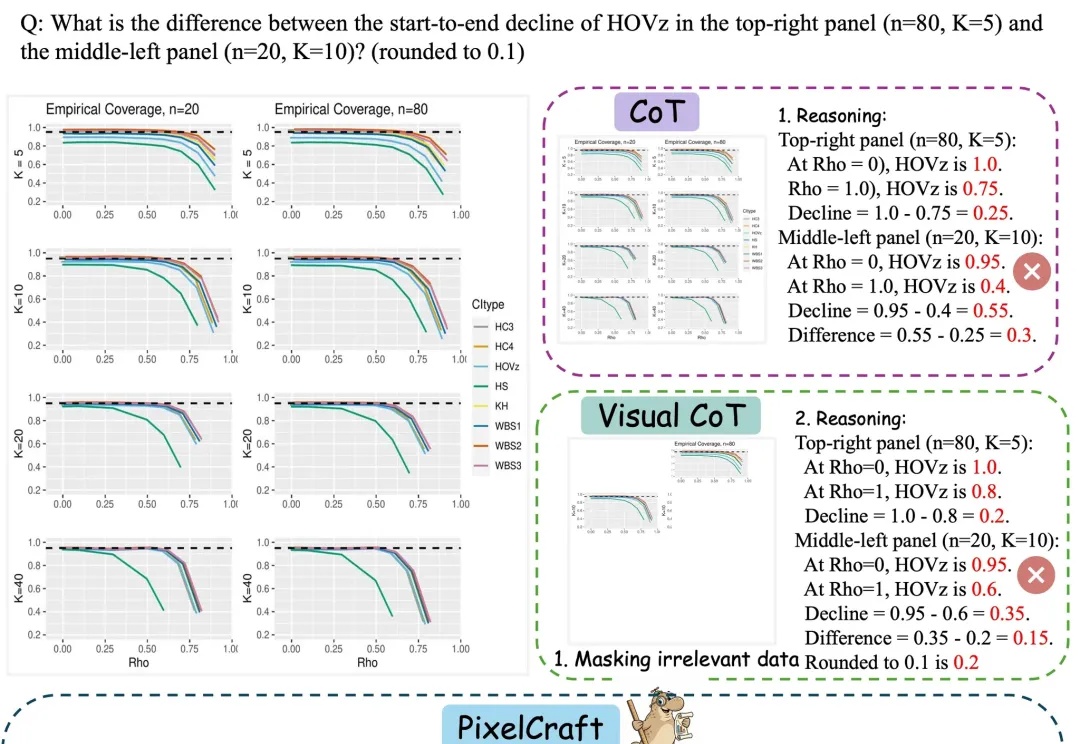
大模型如何准确读懂图表?微软亚研院教它“看、动手、推理”
大模型如何准确读懂图表?微软亚研院教它“看、动手、推理”多模态大模型(MLLM)在自然图像上已取得显著进展,但当问题落在图表、几何草图、科研绘图等结构化图像上时,细小的感知误差会迅速放大为推理偏差。
来自主题: AI技术研报
8289 点击 2025-11-03 14:20
 搜索
搜索
多模态大模型(MLLM)在自然图像上已取得显著进展,但当问题落在图表、几何草图、科研绘图等结构化图像上时,细小的感知误差会迅速放大为推理偏差。
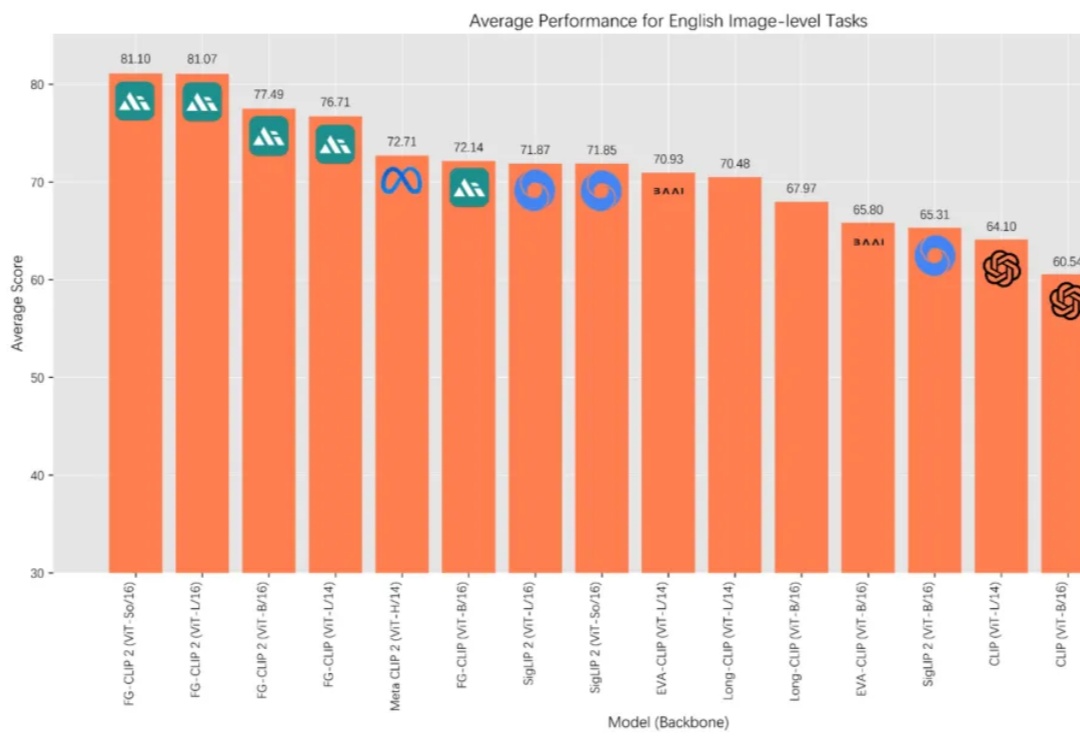
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
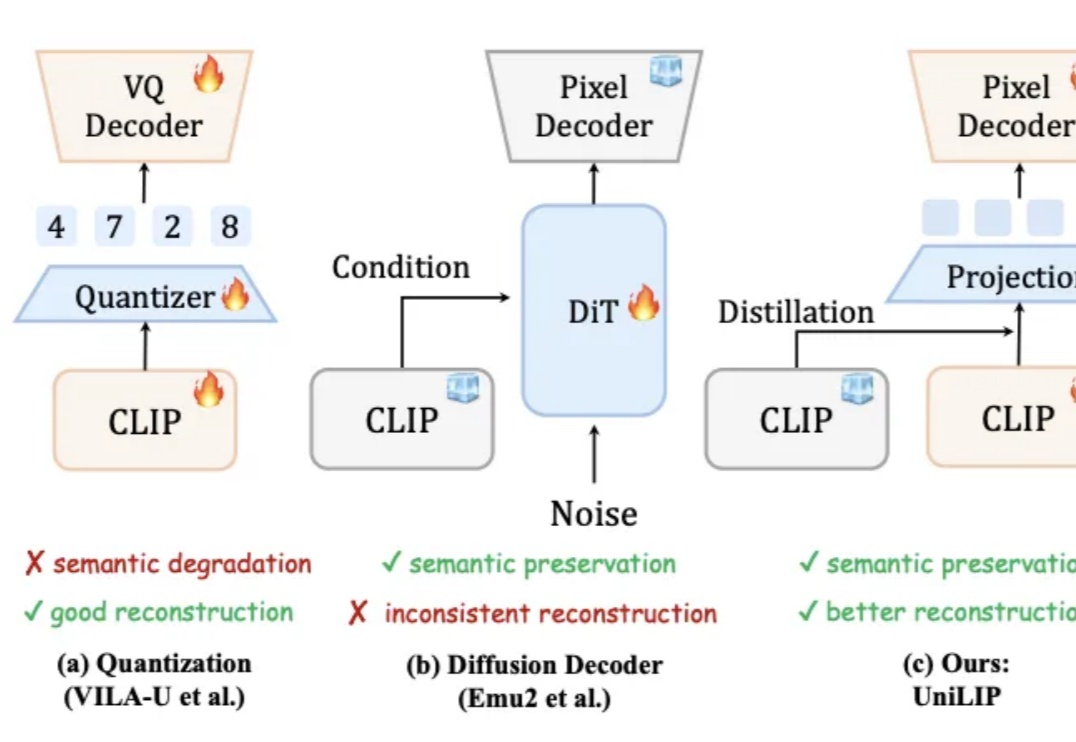
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。
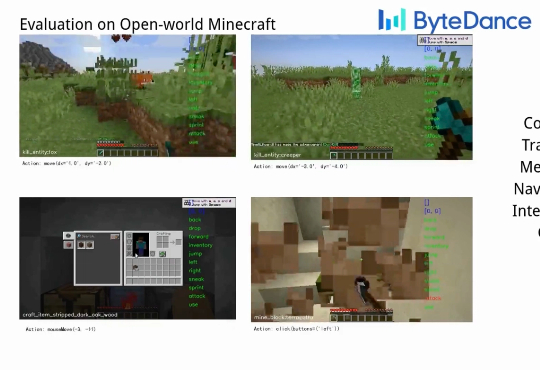
Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。

最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。

今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。
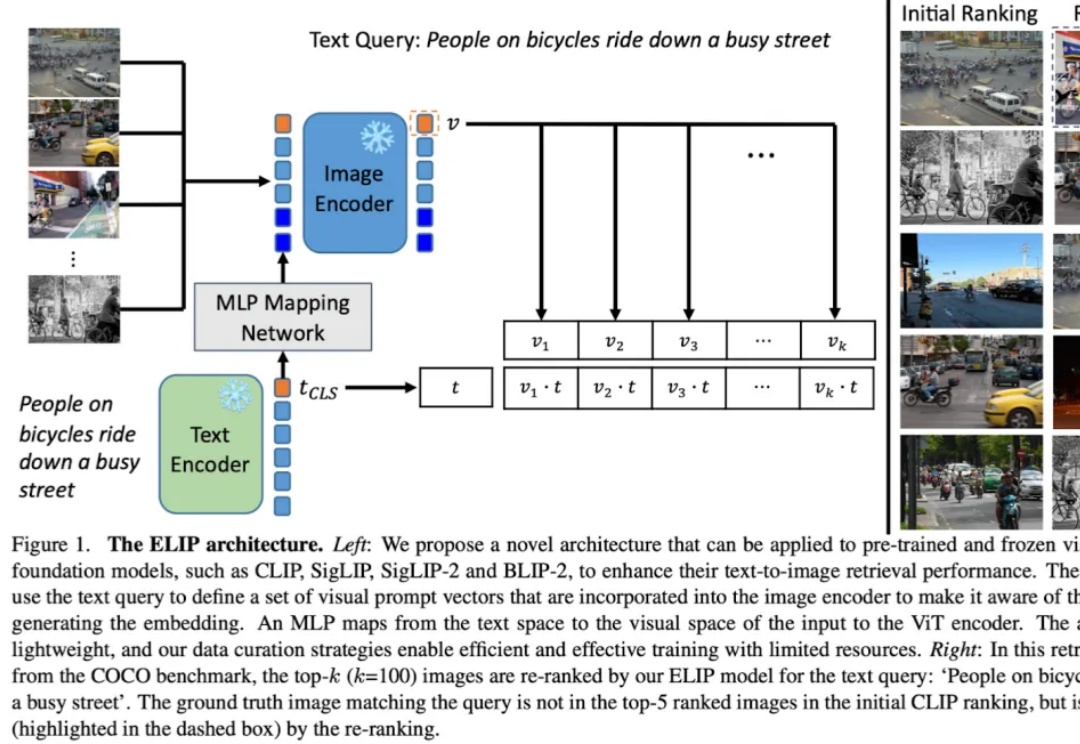
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。

生数科技前产品副总裁廖谦创业了。在此之前,他还先后担任过字节剪映与火山引擎前AIGC产品负责人。8月底从老东家离职后,公司成立仅半个月,就已经拿下了硅谷美元基金HT Investment与BV百度风投的数百万美元投资。

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。