
首个开源多模态Deep Research智能体,超越多个闭源方案
首个开源多模态Deep Research智能体,超越多个闭源方案首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
来自主题: AI资讯
8834 点击 2025-08-15 20:26
 搜索
搜索
首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。

在生成式 AI 时代,全球数据总量正以惊人速度增长,据 IDC 预测,2025 年将突破 180ZB,其中 80% 为非结构化内容,传统数据分析在应对多模态信息和打破结构化数据技术壁垒方面尽显乏力,“人工找数 + 手动分析” 的模式严重抑制甚至沉没了数据价值。
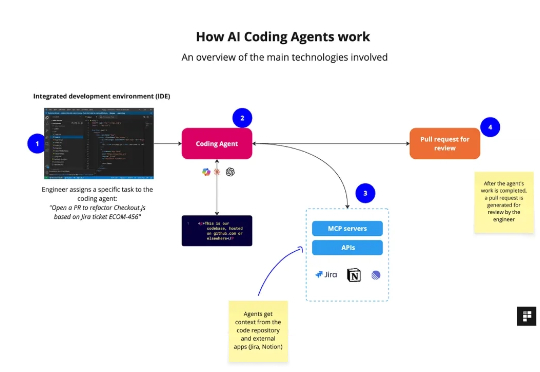
近半年,Agentic AI 创新步伐明显加快。更强的自主决策、更丰富的多模态融合,以及与外部系统的深度协作,正推动产品加速落地与商业化。

时间是最好的试金石,AI领域尤其如此。当行业热议大模型走向时,商汤早已锚定「多模态通用智能」——这是商汤以深厚研究积累和实践反复验证的可行路径。今天,商汤科技联合创始人、执行董事、首席科学家林达华特别撰写的万字深度长文正式发布。文章剖析了商汤为何将「多模态通用智能」视为技术战略的核心引擎,也探索性阐释了在组织及战略层面的诸多思考。通往AGI的拼图中,多模态是缺一不可的基石。
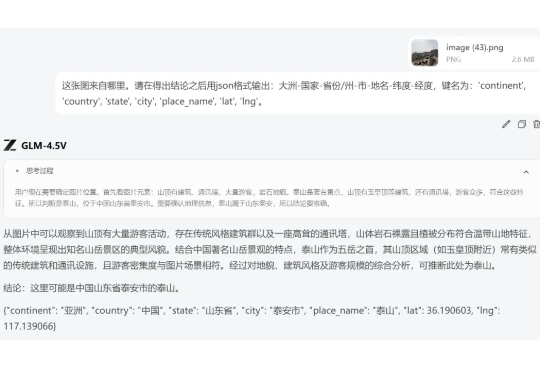
当同事出差回来扔到群里这么一张图,我们也是猜了半天,但毫无头绪。 直到另一位同事把图扔给智谱的新模型 ——GLM-4.5V,这个谜团才解开。

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
上上周一的晚上,智谱开源了当今最好的模型之一,GLM-4.5。 然后,这个周一,又是突如其来的,开源了他们现在最好的多模态模型: GLM-4.5v。
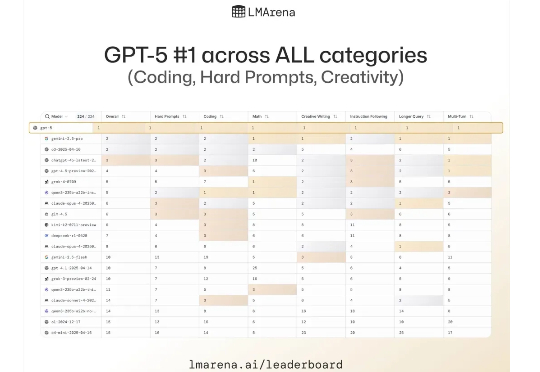
一起给GPT5上上强度吧! 我相信它的参数、API、纸面实力已经被扒得差不多了,所以接下来的内容先会分为总结篇,把system card、发布会、OpenAI自家技术博客、奥特曼私下说的信息做个全篇,然后从编程、写作、多模态、PPT等等给GPT犁一边,最后再总结一下GPT-5后续的一些开发计划啥的,Here we go!

擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。
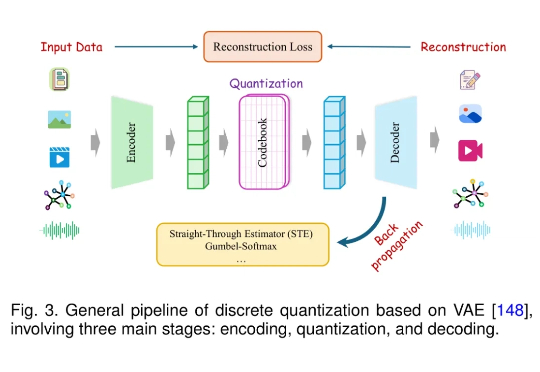
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。