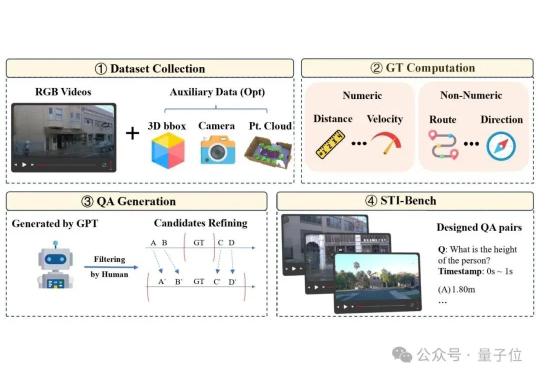
AI能看懂图像却算不好距离,上交时间-空间智能基准难倒9大顶尖多模态模型
AI能看懂图像却算不好距离,上交时间-空间智能基准难倒9大顶尖多模态模型多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
来自主题: AI技术研报
9949 点击 2025-04-15 14:56
 搜索
搜索
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
从 ChatGPT 引发认知革命到 GPT-4o 实现多模态跨越,AI 技术的每次跃迁都在印证一个底层逻辑 —— 数据质量决定智能高度。而今,这场 AI 浪潮正在反哺数据库领域,推动其从幕后走向台前,完成智能时代的华丽转身。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

前些天,GPT-4o的多模态生图上线之后,引发全球AI社区广泛的关注,吉卜力图画全网风靡。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

商汤最新升级的日日新SenseNova V6解锁的新能力—— 原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3:

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

今天,我们正式发布jina-reranker-m0。这是一款多模态、多语言重排器(reranker),其核心能力在于 对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。

多模态视频异常理解任务,又有新突破!
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。