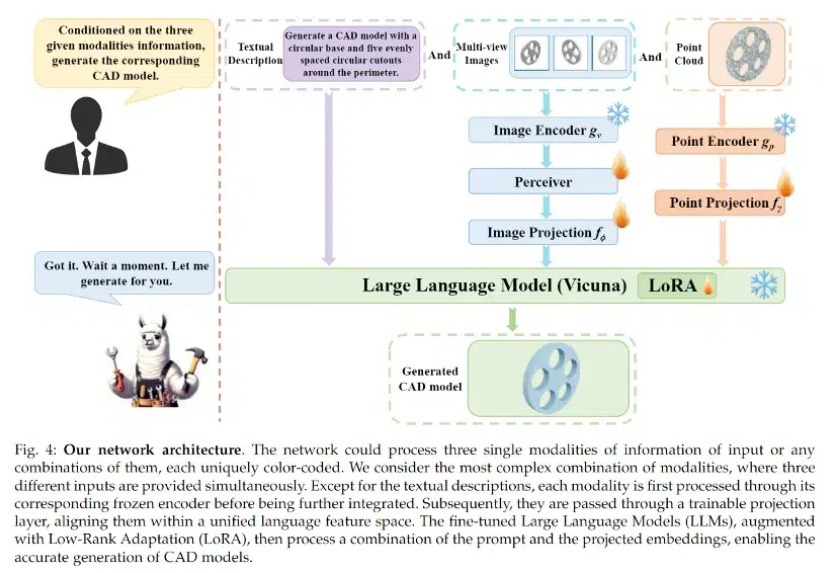
文本、图像、点云任意模态输入,AI能够一键生成高质量CAD模型了
文本、图像、点云任意模态输入,AI能够一键生成高质量CAD模型了该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
来自主题: AI技术研报
9501 点击 2024-11-25 15:51
 搜索
搜索
该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
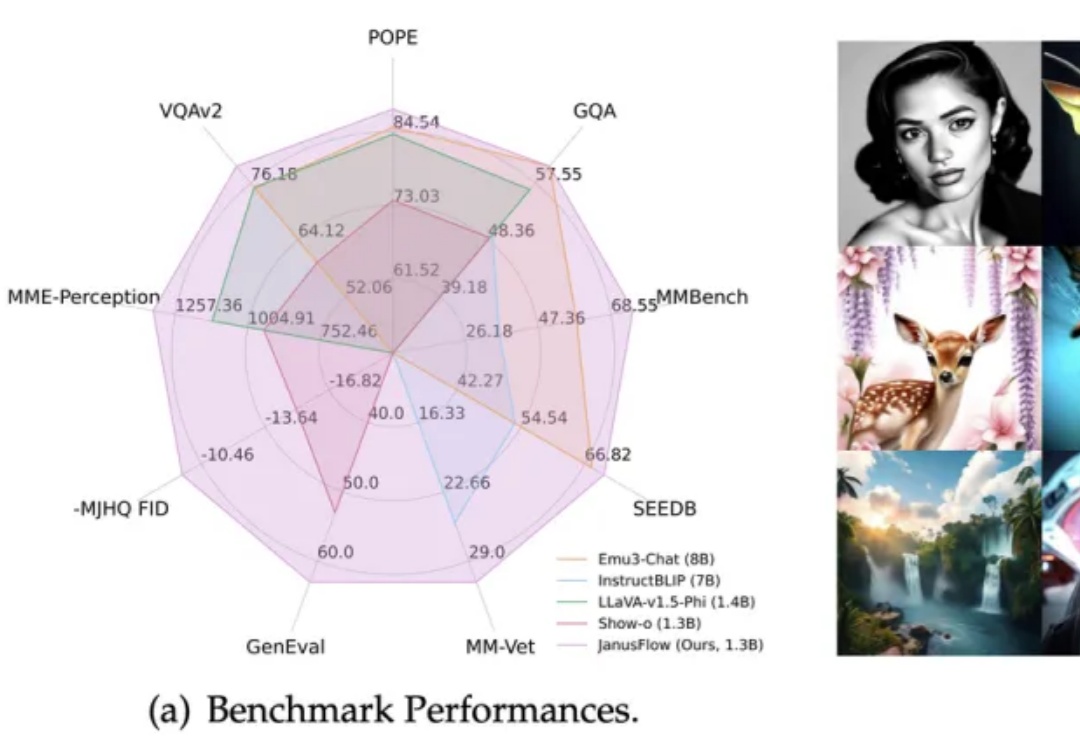
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
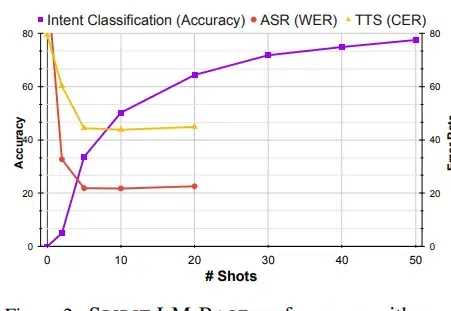
Meta最近开源了一个7B尺寸的Spirit LM的多模态语言模型,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。
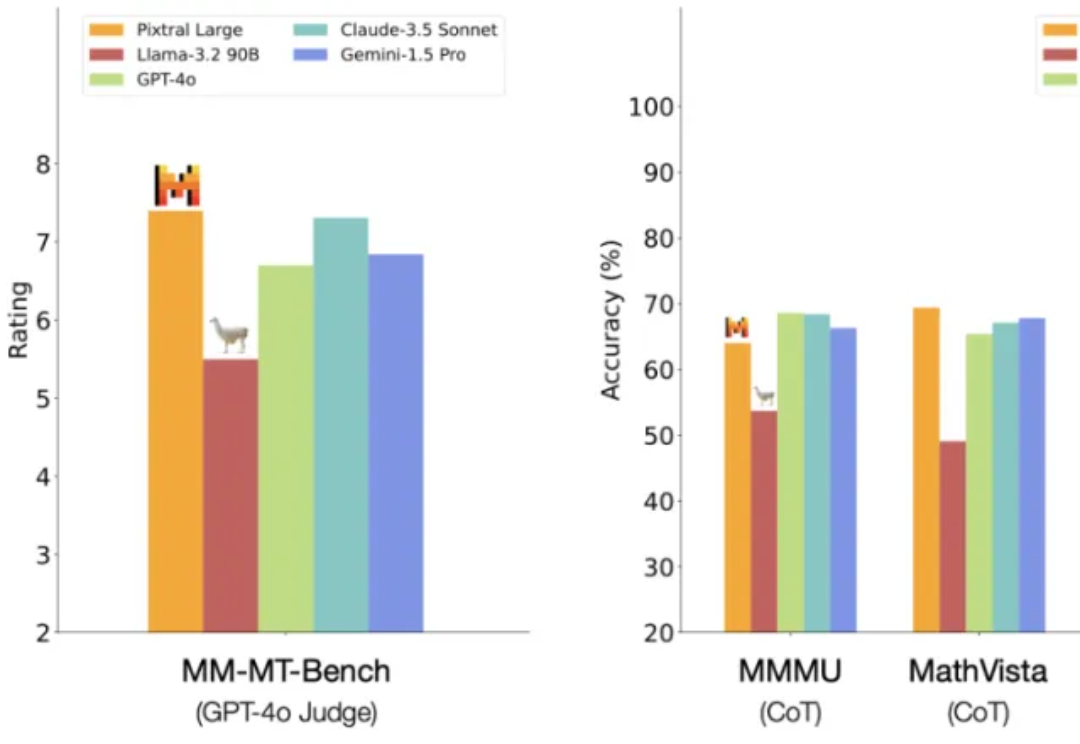
一觉醒来,Mistral AI 又发力了。 就在今天,Mistral AI 多模态家族迎来了第二位成员:一个名为 Pixtral Large 的超大杯基础模型。
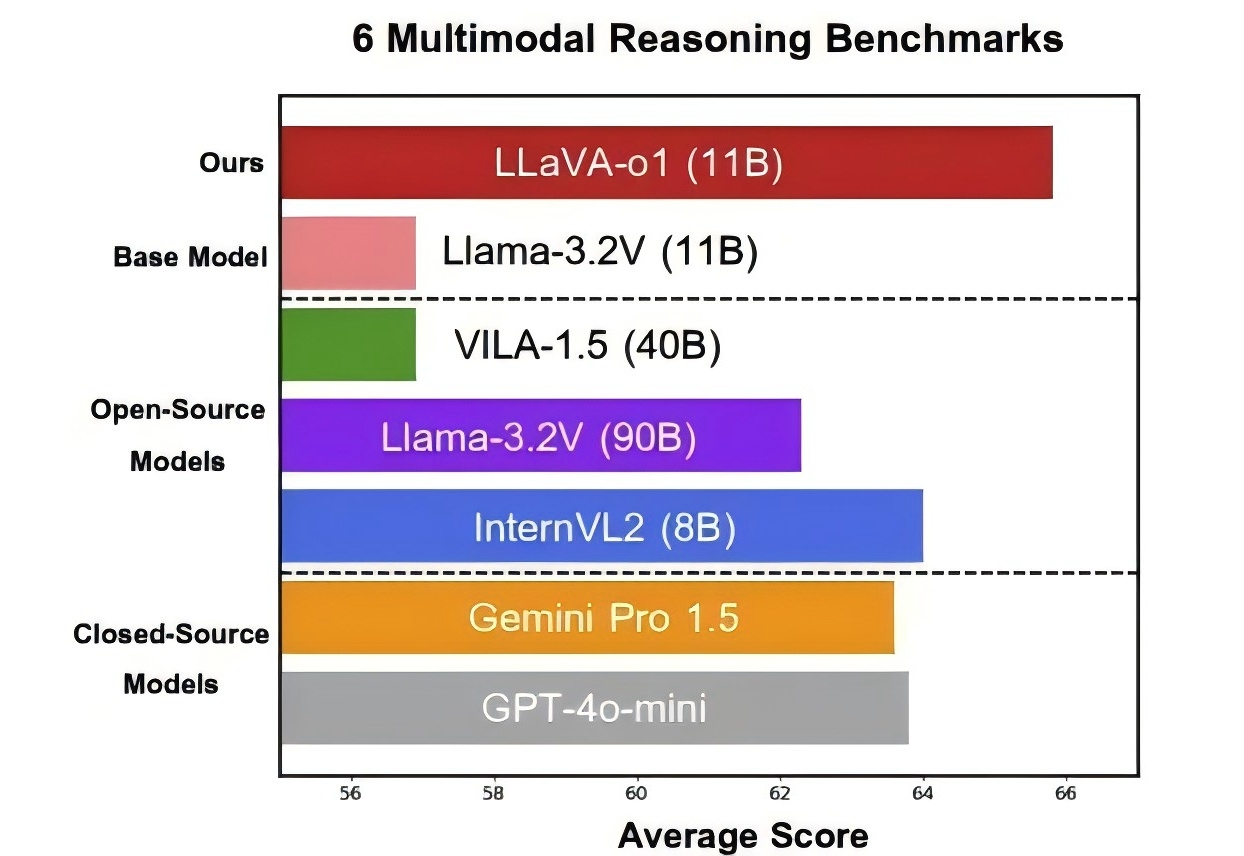
北大等出品,首个多模态版o1开源模型来了—— 代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。
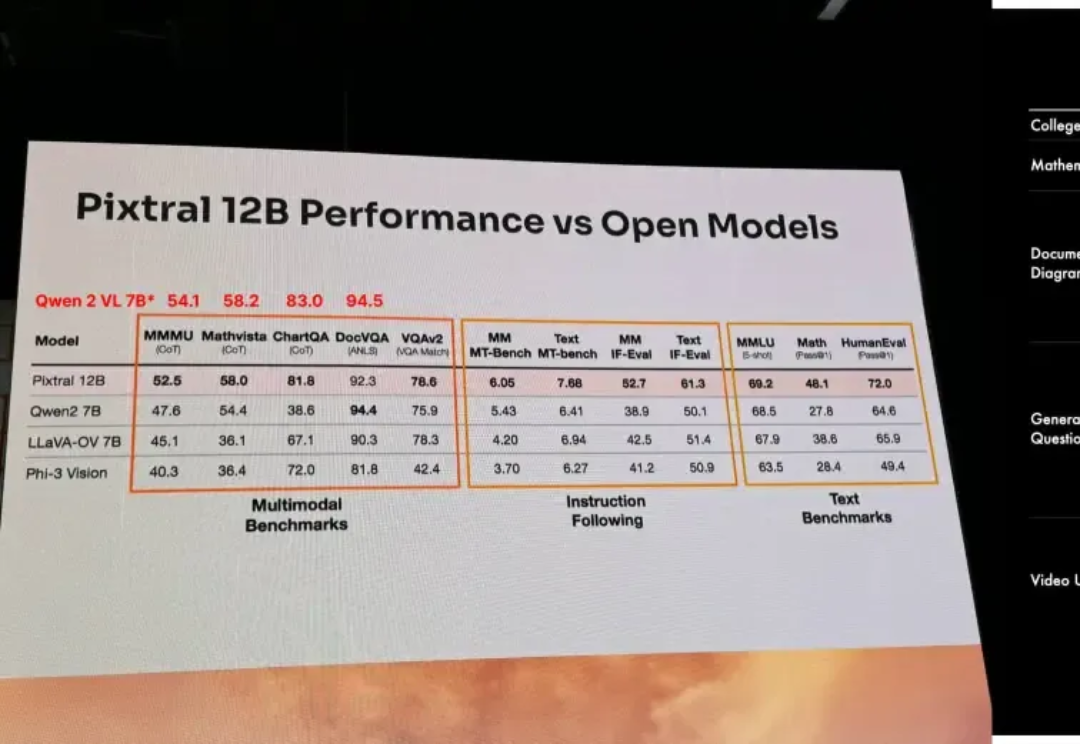
以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。

在闭着眼睛听一首歌的时候,你有没有在脑海里想象过,应该搭配什么画面? Kimi 内测的最新功能「创作音乐视频」,就是奔着当 MV 导演去的。长文本领先的 Kimi,默不作声地「跨界」了。APPSO 也受邀首批体验了这一新功能。

MEGA-Bench是一个包含500多个真实世界任务的多模态评测套件,为全面评估AI模型提供了高效工具。研究人员发现,尽管顶级AI模型在多个任务中表现出色,但在复杂推理和跨模态理解方面仍有提升空间。
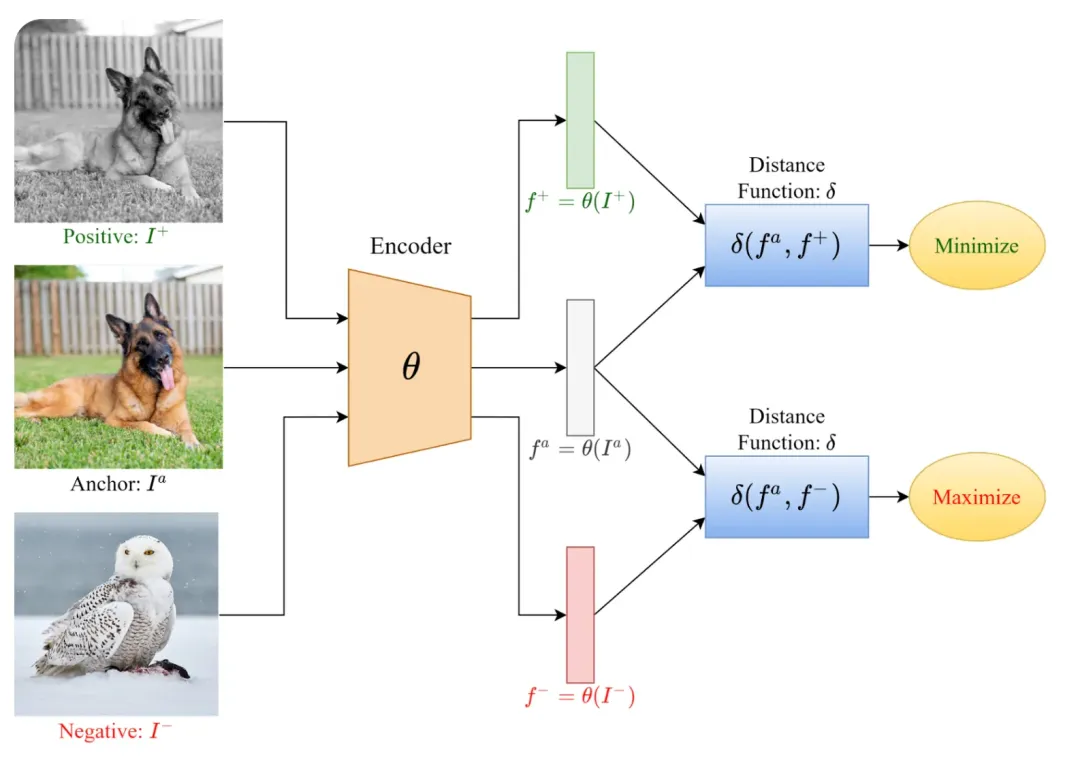
「多模态」这个词,相信各位开发者已经比较熟悉了,多模态的含义是让 AI 同时理解包含如图像和文本在内的多种类型的数据。

全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。