
全球首个自主进化多模态MoE震撼登场!写真视频击败Sora,人大系团队自研底座VDT
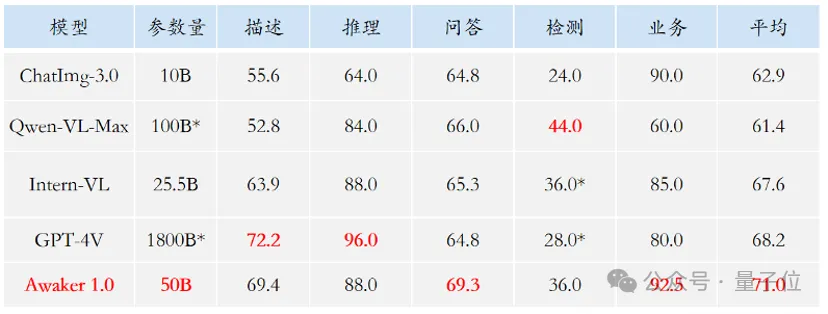
全球首个自主进化多模态MoE震撼登场!写真视频击败Sora,人大系团队自研底座VDT在4月27日召开的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型Awaker 1.0,向AGI迈出至关重要的一步。
来自主题: AI技术研报
7589 点击 2024-04-29 20:27
 搜索
搜索
在4月27日召开的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型Awaker 1.0,向AGI迈出至关重要的一步。
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。

又一个国产多模态大模型开源! XVERSE-V,来自元象,还是同样的无条件免费商用。

奔向通用人工智能,大模型又迈出一大步。
奔向通用人工智能,大模型又迈出一大步。

近期,多模态大模型 (MLLM) 在文本中心的 VQA 领域取得了显著进展,尤其是多个闭源模型,例如:GPT4V 和 Gemini,甚至在某些方面展现了超越人类能力的表现。

2023年12月,宁德时代低调宣布在香港设立国际研发中心; 2024年3月11日,作为中国科学院在香港设立的首个国家级信息研发机构,中国科学院香港创新研究院人工智能与机器人创新中心发布了医疗多模态大模型CARES Copilot 1.0;

一个可以自动分析PDF、网页、海报、Excel图表内容的大模型,对于打工人来说简直不要太方便。

近日,由DeepMind、谷歌和Meta的研究人员创立的AI初创公司Reka,推出了他们最新的多模态语言模型——Reka Core
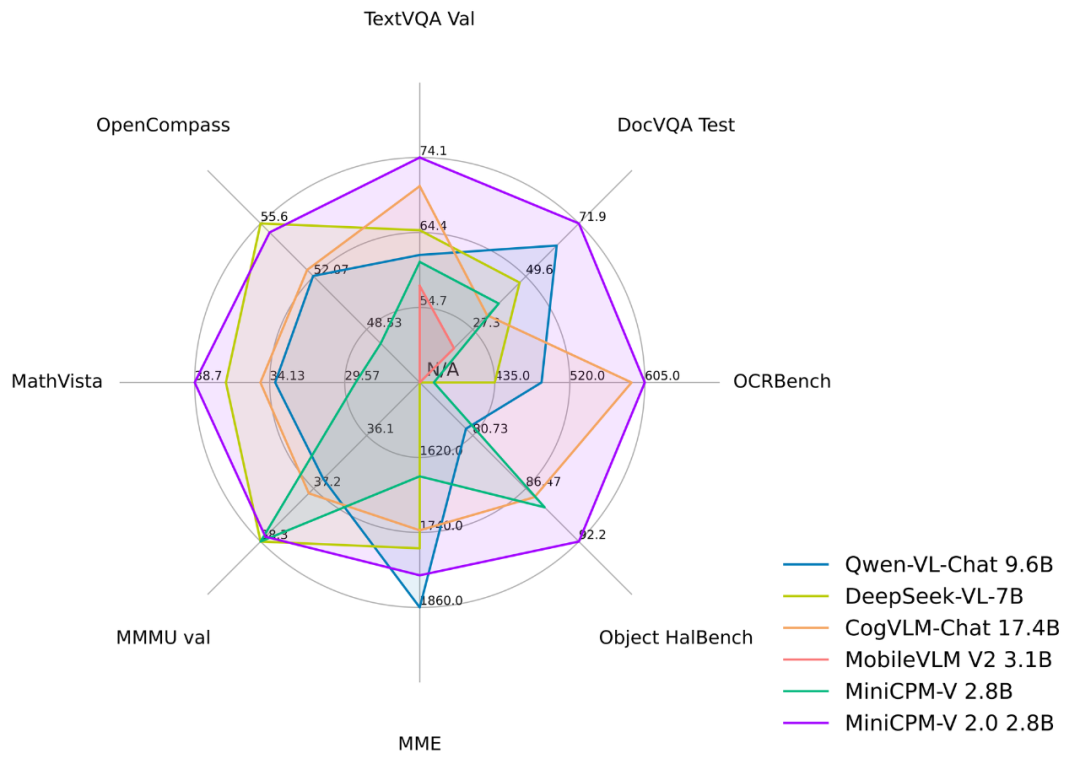
MiniCPM 系列的最新多模态版本 MiniCPM-V 2.0。该模型基于 MiniCPM 2.4B 和 SigLip-400M 构建,共拥有 2.8B 参数。MiniCPM-V 2.0 具有领先的光学字符识别(OCR)和多模态理解能力