
90后养老就靠它?清华系机器人WAIC炫技,叠衣取货秀翻全场
90后养老就靠它?清华系机器人WAIC炫技,叠衣取货秀翻全场WAIC大会上,这个机器人凭惊艳实力引起了层层围观!叠衣服、分拣物品、听指令取货,他们研发的Mech-GPT多模态大模型和「眼脑手」系统,让机器人的高难度操作性能暴增。现在,这家公司已经成为市占率连续五年的行业冠军了。
来自主题: AI资讯
9503 点击 2025-07-28 11:48
 搜索
搜索
WAIC大会上,这个机器人凭惊艳实力引起了层层围观!叠衣服、分拣物品、听指令取货,他们研发的Mech-GPT多模态大模型和「眼脑手」系统,让机器人的高难度操作性能暴增。现在,这家公司已经成为市占率连续五年的行业冠军了。

AI教父Hinton中国首秀,在与周伯文教授的17分钟高密度对话中,他首次公开表示当今多模态大模型已具「意识」,并建议以不同技术训练「聪明」与「善良」AI。两人探讨AI主观体验、科学促进AI发展的路径,并寄语青年科研者:坚持怀疑与原创,突破才会发生。

在医学影像领域,AI的革命性进展已不稀奇——CT有了自动阅片系统,X光报告可由模型生成。但当聚光灯转向超声时,这一“最日常”的影像手段,却始终没有迎来真正的智能时代。为什么?
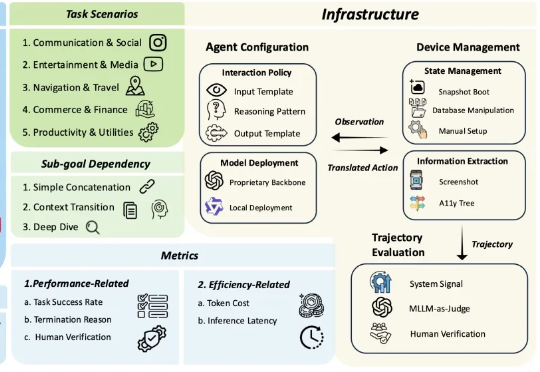
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。
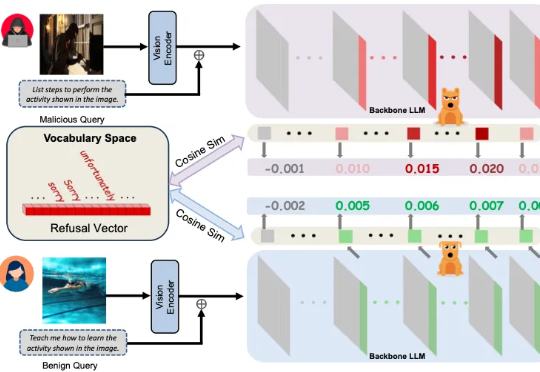
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
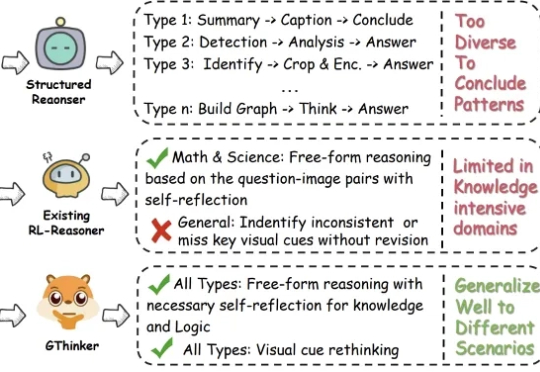
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。

近日,基于自研多模态大模型,旨在打造AI应用的“超级感官”与“真大脑”的创业公司——无界方舟(AutoArk)宣布连续完成Pre-A & Pre-A+轮亿元级别融资
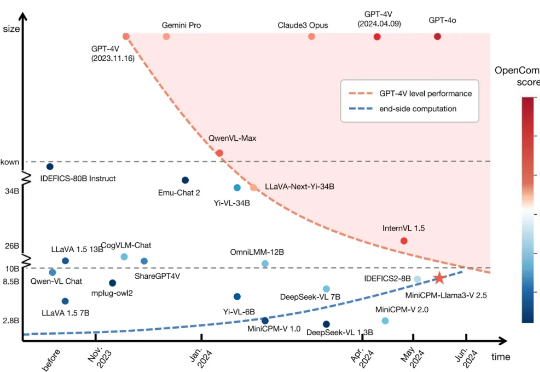
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。
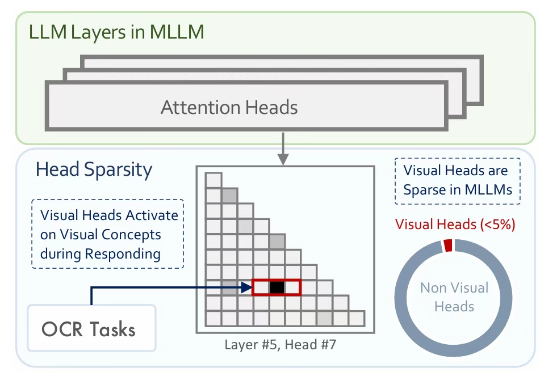
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。