NeurIPS 2025 Spotlight | FSDrive统一VLA和世界模型,推动自动驾驶迈向视觉推理
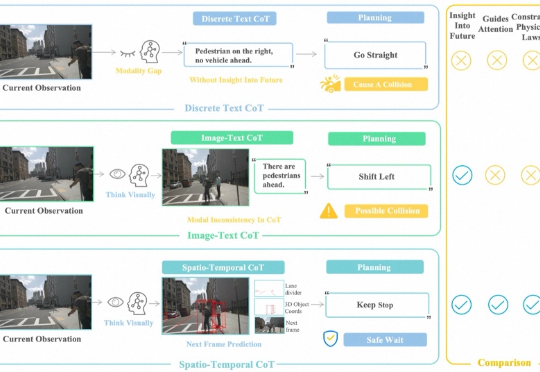
NeurIPS 2025 Spotlight | FSDrive统一VLA和世界模型,推动自动驾驶迈向视觉推理面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
来自主题: AI技术研报
8807 点击 2025-10-06 13:42