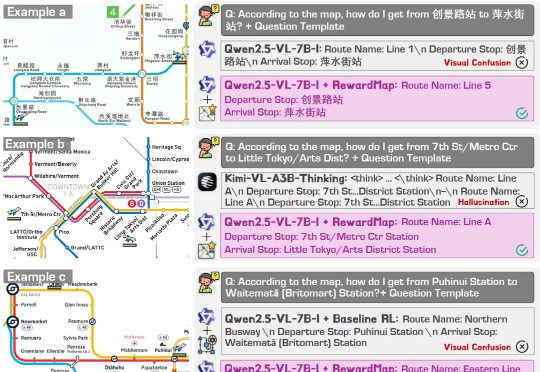
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
来自主题: AI技术研报
7163 点击 2025-10-21 15:53
 搜索
搜索
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
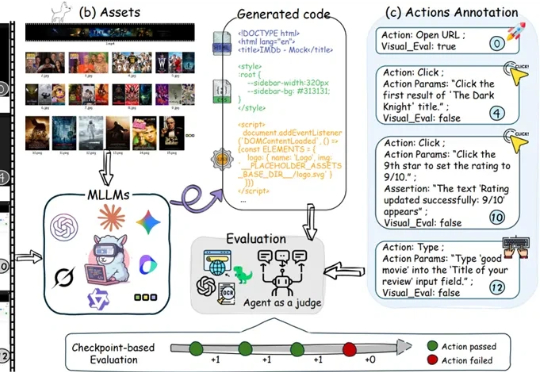
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
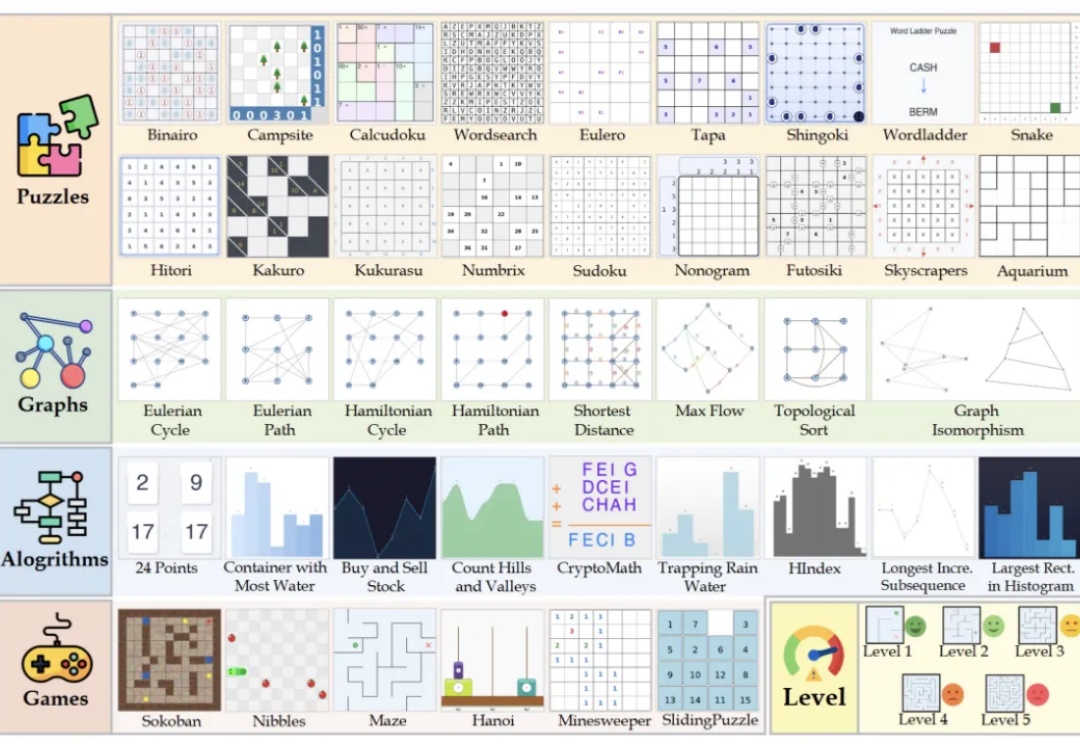
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
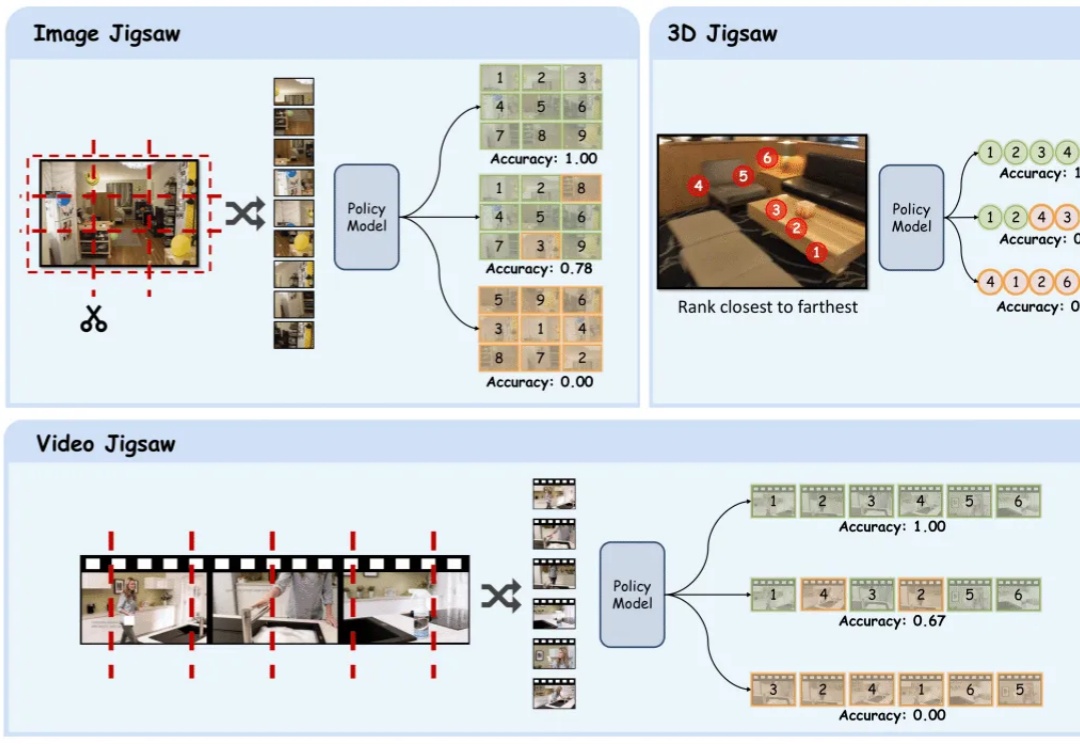
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
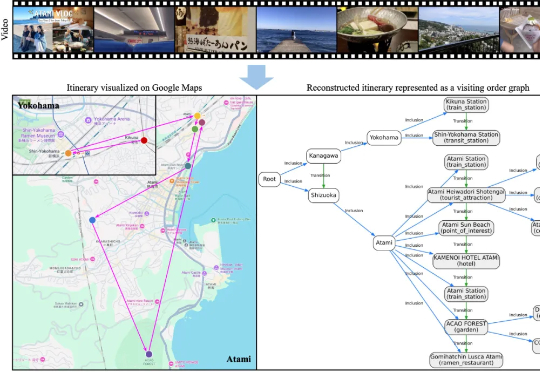
大家或许都有过这样的体验: 看完一部喜欢的动漫,总会心血来潮地想去 “圣地巡礼”;刷到别人剪辑精美的旅行 vlog,也会忍不住收藏起来,想着哪天亲自走一遍同样的路线。旅行与影像的结合,总是能勾起人们的
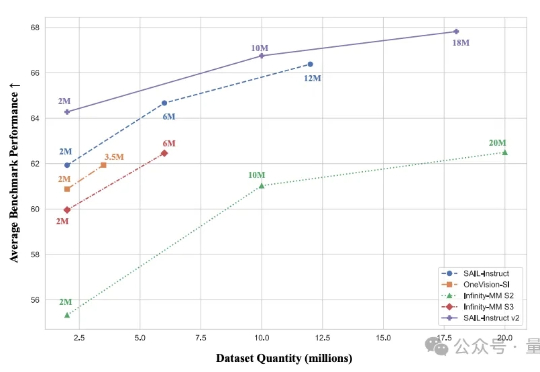
2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。
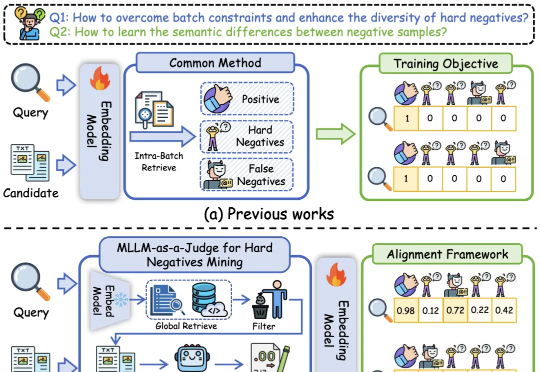
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
本文作者团队来自 Insta360 影石研究院及其合作高校。目前,Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师,欢迎有志于前沿 AI 研究与落地的同